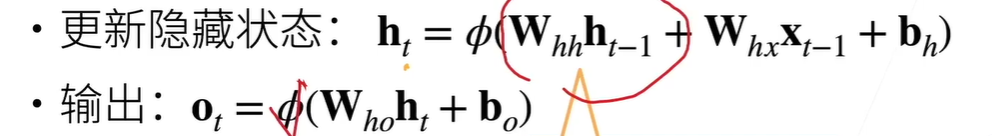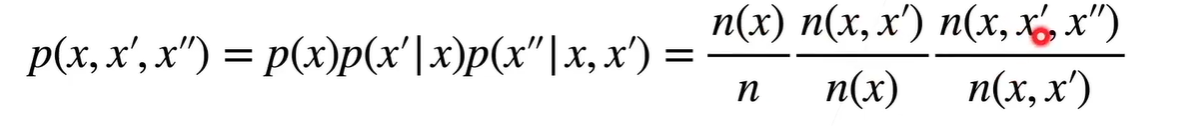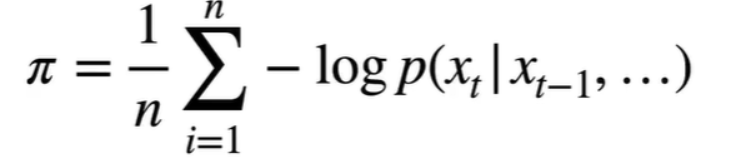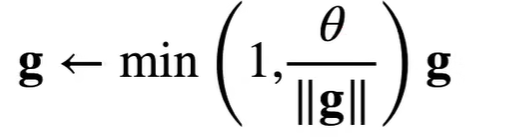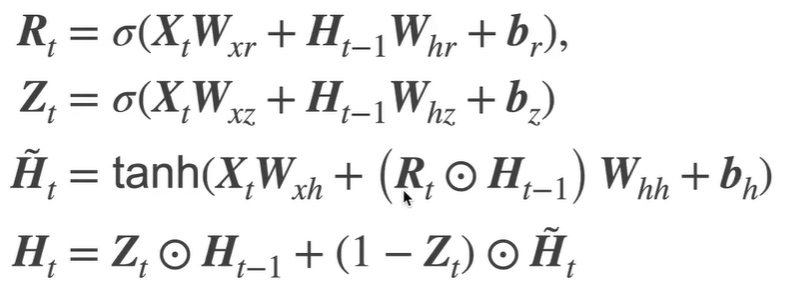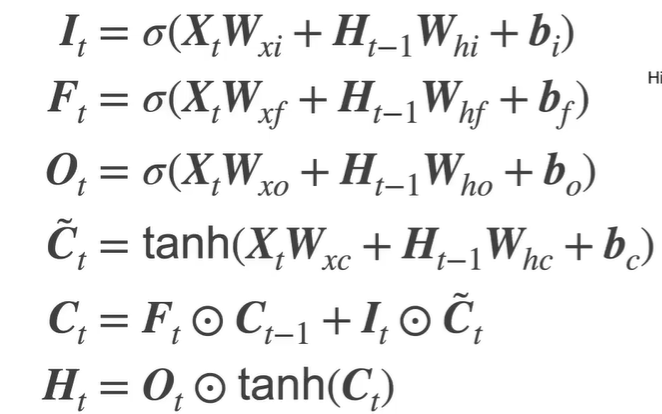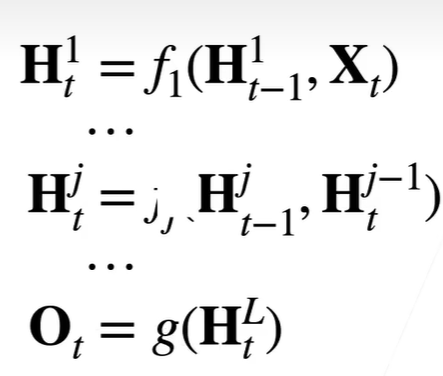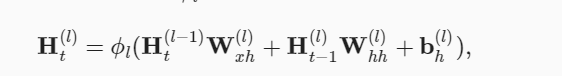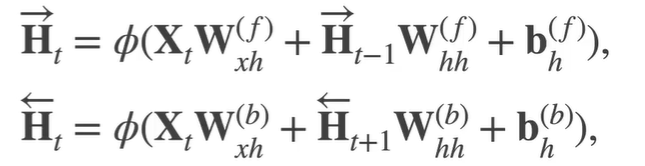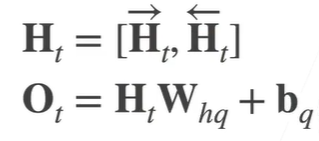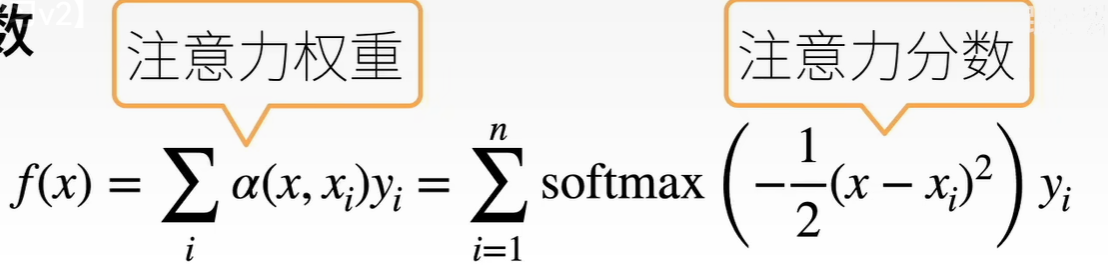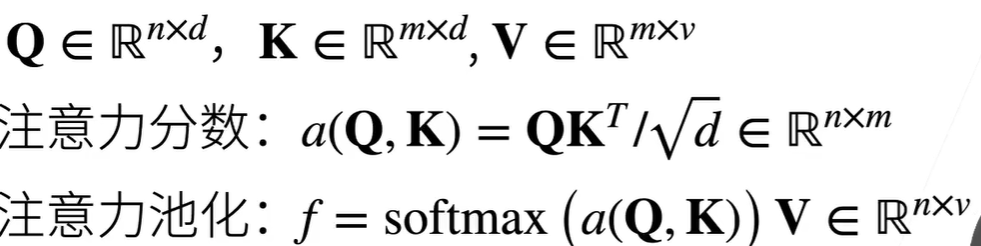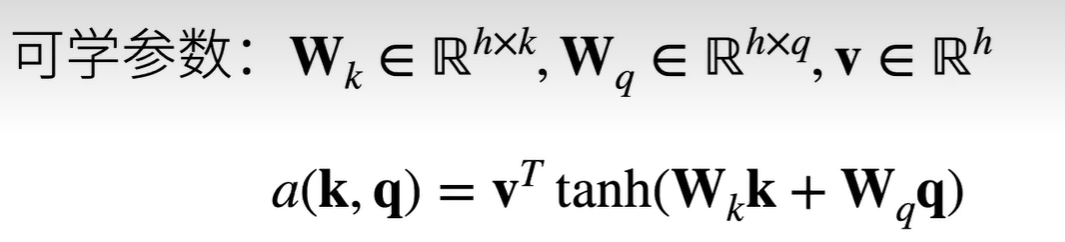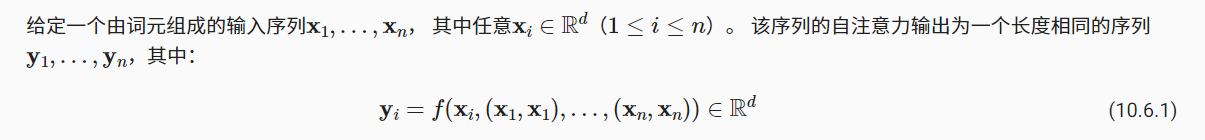GPT摘要
这篇文章主要介绍了GoogLeNet(Inception)网络的结构和特点。GoogLeNet是由Google团队提出的一种深度卷积神经网络,以其高效的计算性能和优异的分类能力而闻名。关键点包括: 1. Inception模块 - 核心创新,通过并行使用不同尺寸的卷积核和池化操作,能够更高效地提取多尺度特征。 2. 网络深度 - GoogLeNet比之前的网络更深(22层),但同时通过1×1卷积减少计算量。 3. 辅助分类器 - 在网络中间层添加辅助分类器,以缓解梯度消失问题并增强训练过程。 4. 全局平均池化 - 替代全连接层以减少参数量,防止过拟合。 5. 高效性 - 通过精心设计,在保持高性能的同时大幅降低了计算成本。 文章详细分析了Inception模块的不同版本(v1-v4)的演进,包括引入批量归一化、因子分解卷积等改进。整体而言,GoogLeNet通过创新的架构设计,实现了在ImageNet等基准数据集上的出色表现。
https://zh-v2.d2l.ai/chapter_convolutional-modern/googlenet.html
课程安排 - 动手学深度学习课程 (d2l.ai)
Base 时序模型 当前数据与之前数据相关
音乐、语言、文本
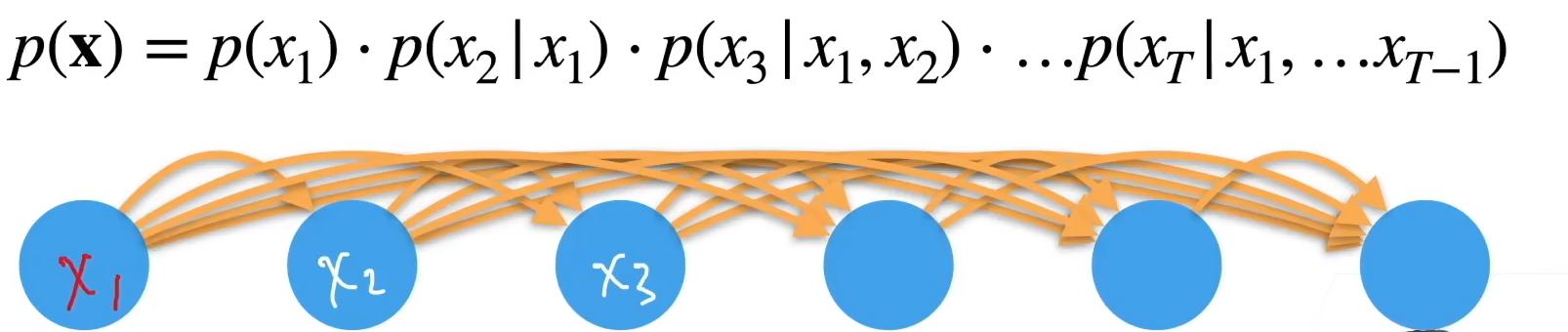
与前面所有有关:
对过去的数据建模,然后预测自己:自回归模型
A:马可夫模型 :当前数据只与最近数据相关;用函数前4个值作为特征,预测下一个值,2层MLP
nn.Sequential(nn.Linear(4, 10),nn.ReLU(),nn.Linear(10, 1))
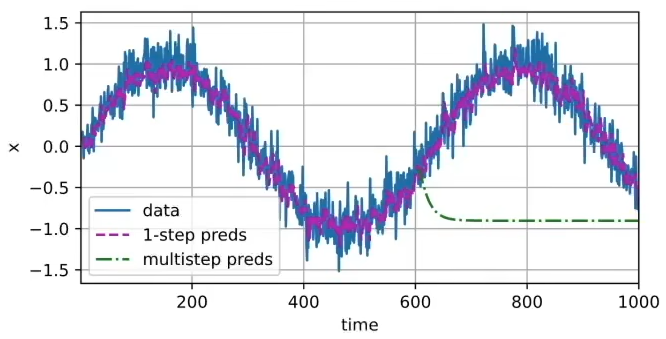
紫线为单步预测,绿线为长步预测
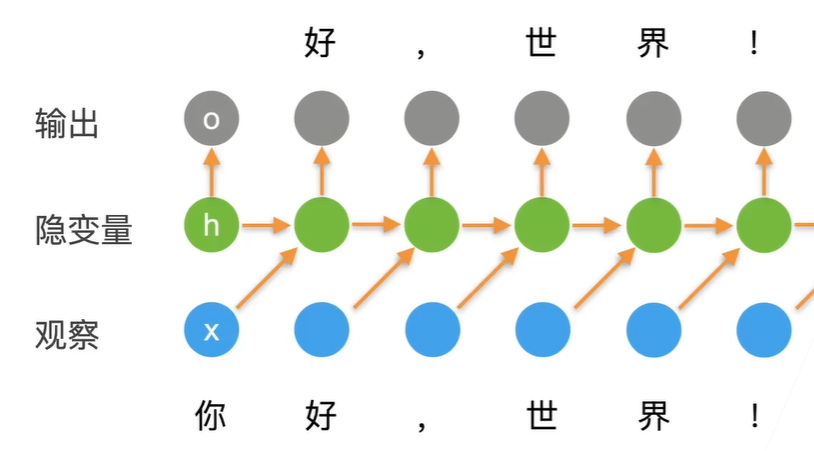
B:潜变量 :引入潜变量,来概括历史信息 RNN 两个模型,(在实际训练中,还是切成了一段段step,实际可以理解为暗含隐马可夫step)
ot利用ht输出(ht由 xt-1 和 ht-1 求出,保存历史信息 ),来推测xt
QA:
RNN甚至可以用来排序?因为可用记住
数据到底和多长的前面的数据相关呢?transformer自动探索多少个
传感器、电池故障预测。单步多步不是重点,关键在于负样本数量
序列也是一维数据,可用用CNN做分类吗? 可以用1维卷积,效果不错的
Vocab
tokenize:将文章按词 或字母 划分,如果是词中文需要分词
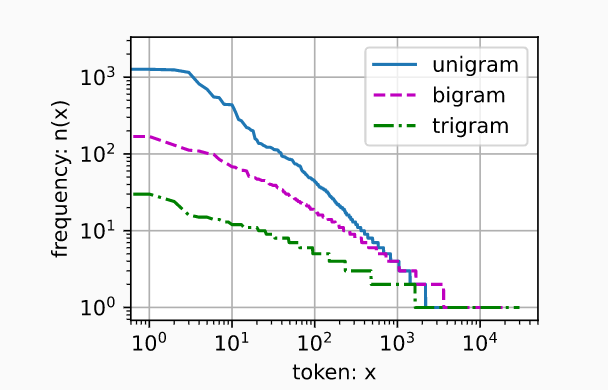
Vocab:文本词汇表,可以按单词分也可以按字母分,将单词映射为index。 按频率排序,方便观察、常用数据内存在一起
语言模型 估计联合概率p(x1 x2 xT),序列出现的概率
做预序列模型 BERT GPT-3
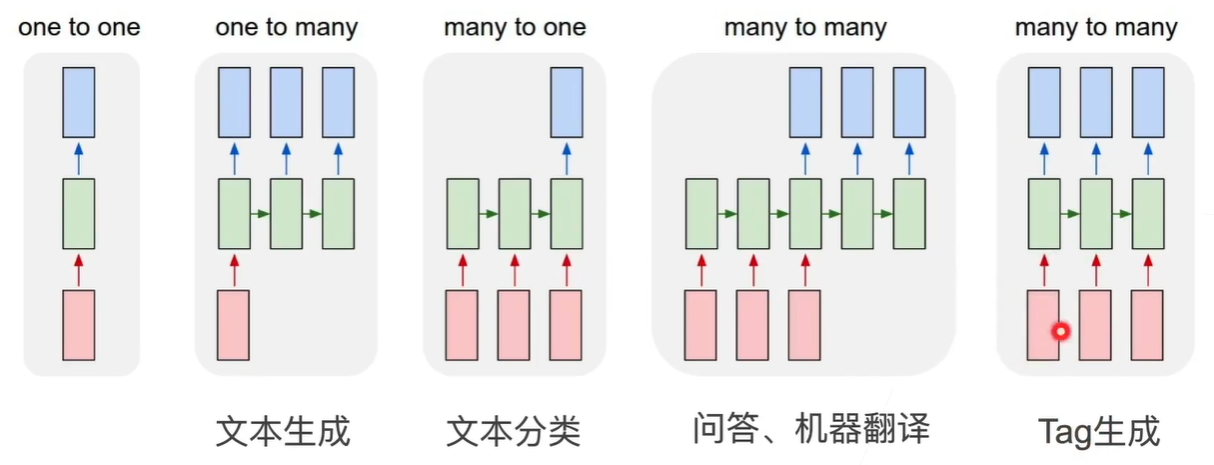
文本生成
判断序列更常见 语音识别哪个更正常 打字
使用计数建模:判断文本出现的概率
n元语法:一个单词出现的概率与它前面的n-1个单词有关。n-1阶段马可夫模型
二元词汇:两个词合起来算一个token
1 2 3 4 5 6 for pair in zip (corpus[:-1 ], corpus[1 :])]for triple in zip (2 ], corpus[1 :-1 ], corpus[2 :])]'the' , 'time' , 'traveller' ), 59 ),'the' , 'time' , 'machine' ), 30 ),]
数据加载 将corpus 转为 batchsize,单个长度为num_step
1.batch间随机;随机起始点,每个单词每次只用一次
1 2 3 4 5 6 7 8 b = 2 , step = 5 11 , 12 , 13 , 14 , 15 ],6 , 7 , 8 , 9 , 10 ]]) 12 , 13 , 14 , 15 , 16 ],7 , 8 , 9 , 10 , 11 ]])1 , 2 , 3 , 4 , 5 ],21 , 22 , 23 , 24 , 25 ]]) 2 , 3 , 4 , 5 , 6 ],
2.batch间连续
1 2 3 4 5 6 7 X: tensor([[ 4 , 5 , 6 , 7 , 8 ],19 , 20 , 21 , 22 , 23 ]]) 5 , 6 , 7 , 8 , 9 ],20 , 21 , 22 , 23 , 24 ]])9 , 10 , 11 , 12 , 13 ],24 , 25 , 26 , 27 , 28 ]]) 10 , 11 , 12 , 13 , 14 ],
load_data_time_machine: 封装数据并返回vocab
x = [b,t] y=[b,t] 特征抽取
x ->onehot-> [t, b, infeature] ->layer-> [t, b, hidden] ->linear-> [t*b, outfeature]
定义:**[in, hidden]** state:( layers * direction, batch, hidden,)
RNN 任务定义:给定一串字母,生成下一个或者n个
模型的好坏(困惑度 ):每一个词都可以看成分类,将每一个词的交叉熵求和求平均。最后做个指数
T个时间上的梯度连乘,需要梯度剪裁。但无法处理梯度消失
任务 视频Tracking:不需要用rnn,直接判断bbox帧间周围的情况
手动实现 h是一个hiddens长的特征记录信息,每一个序列x都会更新下一个h,同时该h能够给出一个o输出,代表着预测的输出
关注h,h是对历史的建模,从h到o只是一个线性回归
参数定义: 五个参数,需要梯度。并且需要定义初始化h的函数 ( (b, hiddens), )
forward函数:
序列输入,所以t一定是在最外面。b的作用仅仅是泛化,b之间互不影响。h也是存储了b个
输入[b,t]和state 转置onehot转为[t, b, onehot]
按t遍历输入到网络中,每次输出[b onehot], 并更新t次state
(和y计算损失函数,预测的下一个字母)
最后堆叠输出 [t*b, onehot],new_state
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def rnn (inputs, state, params ):for X in inputs:return torch.cat(outputs, dim=0 ), (H,)def __call__ (self, X, state ):self .vocab_size).type (torch.float32)return self .forward_fn(X, state, self .params)
剪裁 : 梯度二范数 torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params)) < θ
预测 : 用预先给的词初始化h,并不断forward给输出并更新state
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def predict_ch8 (prefix, num_preds, net, vocab, device ): """在`prefix`后面生成新字符。""" 1 , device=device)0 ]]]lambda : torch.tensor([outputs[-1 ]], device=device).reshape((1 , 1 ))for y in prefix[1 :]: for _ in range (num_preds): int (y.argmax(dim=1 ).reshape(1 )))return '' .join([vocab.idx_to_token[i] for i in outputs])
训练: 一个epoch中,注意batch间如果打乱了的化,state要重新初始化。否者沿用之前的,并且需要detach_()
损失函数: 直接CrossEntropy 注意更新前先剪裁梯度。y是[b, t] 传入前先转置一下
简洁实现 核心:通过保存state信息,对t个features编码,转为t个num_hiddens
RNN的定义是没有b的,只需要features num_hiddens,但state有b且多了个1维度
RNN实际上就是对输入的t个时间序列,进行建模处理,并返回hidden维度信息
1 2 3 4 5 6 7 8 9 10 11
输入数据中的t代表着输入数据的时序长度,很像t次MLP分类,但是前面的数据会影响state从而影响后面的分类
为什么没有out层?输出不一定要和输入的维度一样,比如我可以只去做一个情感分类,或者只想提取特征。如果想分类,直接输入到全连接
1 2 3 Y, state = self .rnn(X, state)self .linear(Y.reshape((-1 , Y.shape[-1 ])))
QA:
处理视频时序序列,t就是想要关联的帧长度,而onehot则改成了由神经网络抽取出来单帧图片的特征。所以[t,features]输入到rnn后,rnn返回给你[t,features’ ] ,根据这个提取出信息
如果用单词作为预测目标 ,onehot将会非常长。不利于预测
RNN不能处理长序列:num_hiddens决定着你记录之前的状态 。但太大会过拟合,太小会无法记录下之前的消息
高频词可以对概率开根号,或者随机去除
GRU 添加两个门,更好的保留以前的信息 :如一群老鼠突然出现一直猫,注意点要转移到猫上。(0~1取值,按位乘)
遗忘门R: 计算ht时,ht-1h忘记多少 更新门Z :ht和现在ht-1所占的比例
实现 获取参数 :11个 W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q
forward函数 :按照公式写
1 2 3 4 5 6 7 8 9 10 11 12 def gru (inputs, state, params ):for X in inputs:1 - Z) * H_tildareturn torch.cat(outputs, dim=0 ), (H,)
和前面一样封装到类中,需要传入infeature hidden get_param init_state forward
1 2 3 model = d2l.RNNModelScratch(len (vocab), num_hiddens, device, get_params,
简洁: 封装到RNNModel中
1 2 3 4 gru_layer = nn.GRU(num_inputs, num_hiddens)len (vocab))
对比GRU,虽然计算复杂了,但运算速度反而更快了 242822.8 -> 26820.1 tokens/sec
QA:
GRU LSTM参数更多,但稳定性比RNN更好
尽量不要使用RNN
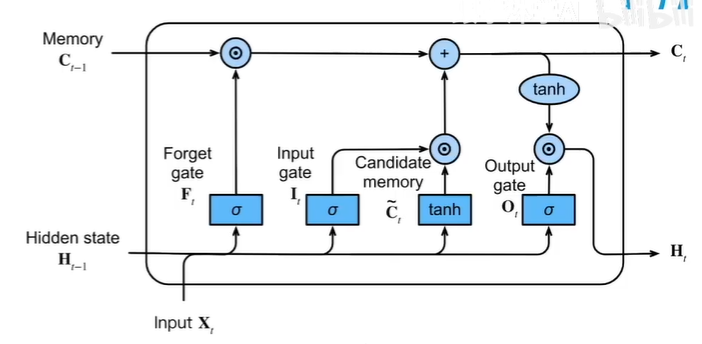
LSTM 两个state :C、H
F (忘记门) 和 I (输入门)决定以前C和现在C~所占比例,O(输出门)决定C求出来后如何向H转换
1 2 3 4 5 6 lstm_layer = nn.LSTM(num_inputs, num_hiddens)
实际内存难以计算,cudnn会用内存换速度,直接跑来看占用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 class RNNModel (nn.Module):"""The RNN model. Defined in :numref:`sec_rnn-concise`""" def __init__ (self, rnn_layer, vocab_size, **kwargs ):super (RNNModel, self ).__init__(**kwargs)self .rnn = rnn_layerself .vocab_size = vocab_sizeself .num_hiddens = self .rnn.hidden_sizeif not self .rnn.bidirectional:self .num_directions = 1 self .linear = nn.Linear(self .num_hiddens, self .vocab_size)else :self .num_directions = 2 self .linear = nn.Linear(self .num_hiddens * 2 , self .vocab_size)def forward (self, inputs, state ):self .vocab_size)self .rnn(X, state)self .linear(Y.reshape((-1 , Y.shape[-1 ])))return output, statedef begin_state (self, device, batch_size=1 ):if not isinstance (self .rnn, nn.LSTM):return torch.zeros((self .num_directions * self .rnn.num_layers,self .num_hiddens),else :return (torch.zeros((self .num_directions * self .rnn.num_layers,self .num_hiddens), device=device),self .num_directions * self .rnn.num_layers,self .num_hiddens), device=device))def train_epoch_ch8 (net, train_iter, loss, updater, device, use_random_iter ):"""Train a net within one epoch (defined in Chapter 8). Defined in :numref:`sec_rnn_scratch`""" None , d2l.Timer()2 ) for X, Y in train_iter:if state is None or use_random_iter:0 ], device=device)else :if isinstance (net, nn.Module) and not isinstance (state, tuple ):else :for s in state:1 )if isinstance (updater, torch.optim.Optimizer):1 )else :1 )1 )return math.exp(metric[0 ] / metric[1 ]), metric[1 ] / timer.stop()
1 2 3 4 lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)len (vocab))
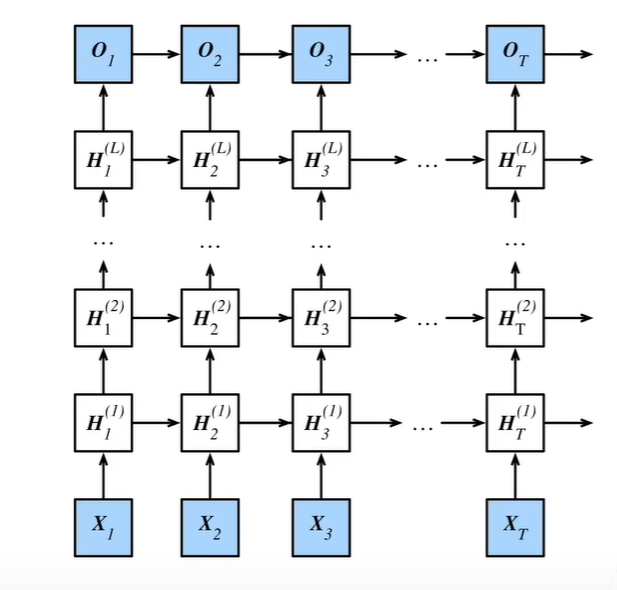
深度 多个隐藏层获得非线性性
在同一个时刻,保存多个Ht ,由左下角推理而来
state: ([1, b, num_hiddens],[1, b, num_hiddens]) ->([2, b, num_hiddens],[2, b, num_hiddens]) 两层够了
1 lstm_layer = nn.LSTM(num_inputs, num_hiddens,num_layer) num_layer决定H个数
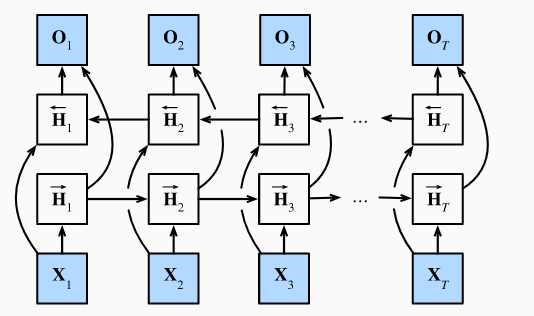
双向
两个H,一个依赖以前的,一个依赖以后的。相互独立,cat在一起决定输出
抽取特征,分类,填空、翻译。但不能预测未来,因为反方向不存在
1 lstm_layer = nn.LSTM(num_inputs, num_hiddens,num_layer, bidirectional=True )
对句子做特征提取:做翻译、改写,不能做预测,因为完全没有反方向的信息
机器翻译数据集
读入数据,预处理去除大写、特殊字符。
单词化后,英语,法语分别绘制vocab,加入一些特殊字符
结尾补上vocab[‘‘], 批量计算,每一个句子长度要想同,所以限制最大长度,不足补vocab[‘‘] 转idx
1 2 3 4 5 6 7 8 def build_array_nmt (lines, vocab, num_steps ):"""将机器翻译的文本序列转换成小批量""" for l in lines]'<eos>' ]] for l in lines]'<pad>' ]) for l in lines])'<pad>' ]).type (torch.int32).sum (1 )return array, valid_len
封装成batch,每次返回 X, X_valid_len, Y, Y_valid_len. len为实际句子长度
1 2 3 4 5 6 7 8 9 10 11 12 13 def load_data_nmt (batch_size, num_steps, num_examples=600 ):"""返回翻译数据集的迭代器和词表""" 2 ,'<pad>' , '<bos>' , '<eos>' ])2 ,'<pad>' , '<bos>' , '<eos>' ])return data_iter, src_vocab, tgt_vocab
1 2 3 4 5 6 7 8 9 10 11 12 for X, X_valid_len, Y, Y_valid_len in train_iter:93 , 12 , 4 , 3 , 1 , 1 , 1 , 1 ],13 , 34 , 5 , 3 , 1 , 1 , 1 , 1 ]])for X: tensor([4 , 4 ])0 , 103 , 104 , 105 , 5 , 3 , 1 , 1 ],121 , 5 , 3 , 1 , 1 , 1 , 1 , 1 ]], dtype=torch.int32)for Y: tensor([6 , 3 ])2 ,每个句子最大长度num_steps=8 输入为一个句子,输出也为一个句子
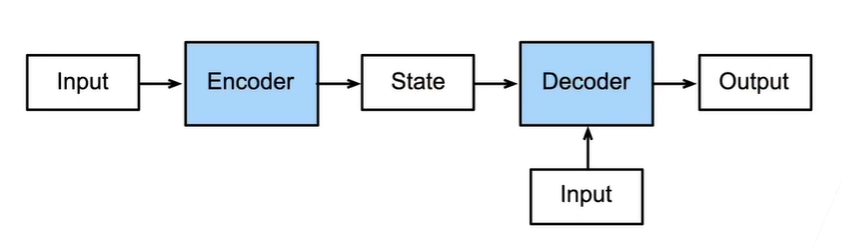
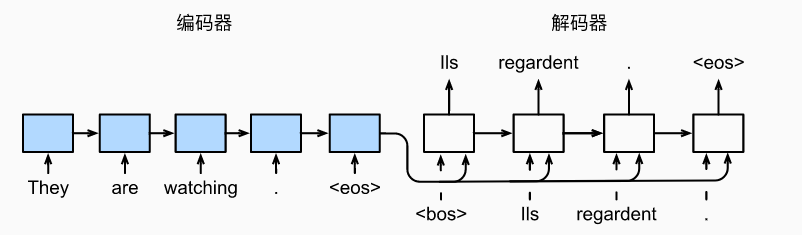
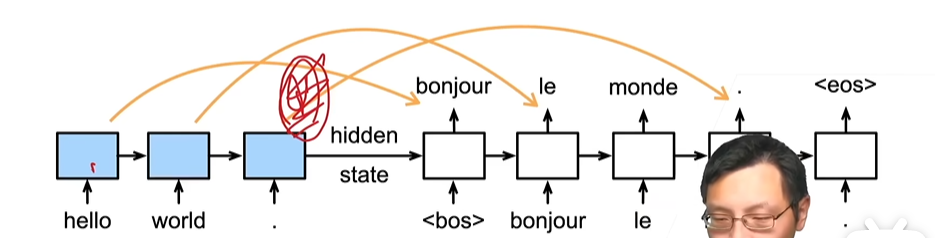
Encoder-Decoder encoder最后的隐藏状态作为decoder的输入,decoder还可以有额外输入。decoder时,由于不知道后面的信息,所以需要一个一个输入
1 2 3 4 5 6 7 8 9 10 11 12 class EncoderDecoder (nn.Module):"""编码器-解码器架构的基类""" def __init__ (self, encoder, decoder, **kwargs ):super (EncoderDecoder, self ).__init__(**kwargs)self .encoder = encoderself .decoder = decoderdef forward (self, enc_X, dec_X, *args ):self .encoder(enc_X, *args)self .decoder.init_state(enc_outputs, *args)return self .decoder(dec_X, dec_state)
Seq2Seq 句子生成句子,使用编码器解码器架构
编码器用于提取句子(生成context),解码器输入为
预测阶段:前一个单词(1,b,h) 和 context的concate
训练阶段:整个单词序列(t,b,h) 和 context的concate,由于context不变,GRU内部其实也是相对于进行了t次
encoder可用双向 ,对输入编码后返回编码器最后的状态,作为decoder输入
训练时decoder需要右移位一下,每次用的正确的输入(强制教学),推理用的上一次输出
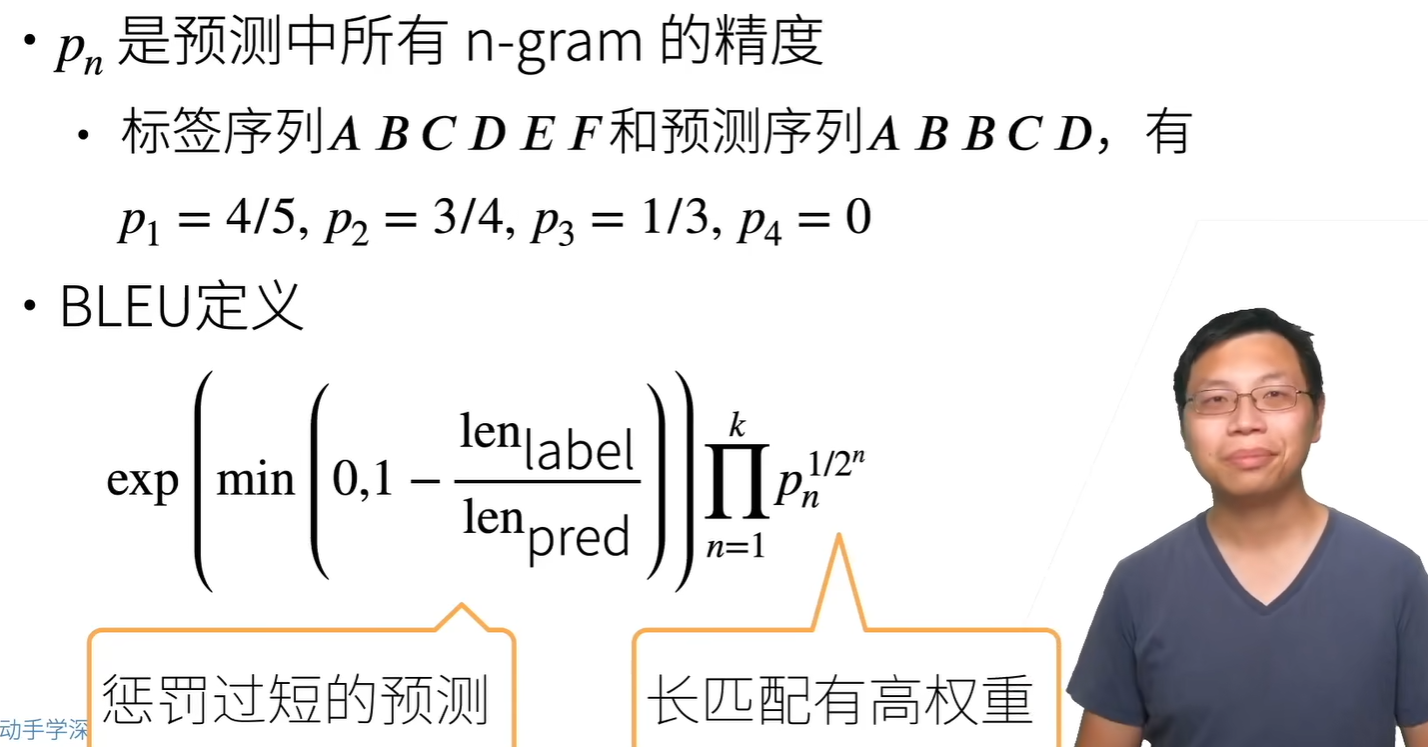
衡量结果 如何衡量生成序列的好坏
编码器获得state后,把最后一次的state [num_layer, b, num_hiddens] 作为解码器的输入state
解码器负责将state[-1]重复t次,作为历史状态,并和输入Y[b,t] concat [t, b, emb+hid]传入GRU网络
GRU将t个state作为dense的输入,输出t * b * vocab permuteb * t * vocab
model encoder 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 输入 b, tclass Seq2SeqEncoder (d2l.Encoder):"""用于序列到序列学习的循环神经网络编码器""" def __init__ (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0 , **kwargs ):super (Seq2SeqEncoder, self ).__init__(**kwargs)self .embedding = nn.Embedding(vocab_size, embed_size)self .rnn = nn.GRU(embed_size, num_hiddens, num_layers,def forward (self, X, *args ):self .embedding(X)1 , 0 , 2 )self .rnn(X)return output, state
decoder 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 输入 X[b, t] embedding -> X[t, b, embed_size] + cat state[t, b, hiddens] = [t, b, em+hiddens]class Seq2SeqDecoder (d2l.Decoder):"""用于序列到序列学习的循环神经网络解码器""" def __init__ (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0 , **kwargs ):super (Seq2SeqDecoder, self ).__init__(**kwargs)self .embedding = nn.Embedding(vocab_size, embed_size)self .rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,self .dense = nn.Linear(num_hiddens, vocab_size)def init_state (self, enc_outputs, *args ):return enc_outputs[1 ]def forward (self, X, state ):self .embedding(X).permute(1 , 0 , 2 )1 ].repeat(X.shape[0 ], 1 , 1 )2 )self .rnn(X_and_context, state)self .dense(output).permute(1 , 0 , 2 )return output, state
loss 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 , 1 , 1 ], [1 , 1 , 1 ]]) b, t1 , 2 ]))1 , 0 , 0 ],[1 , 1 , 0 ]]class MaskedSoftmaxCELoss (nn.CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数""" def forward (self, pred, label, valid_len ):self .reduction='none' super (MaskedSoftmaxCELoss, self ).forward(0 , 2 , 1 ), label)1 )return weighted_loss
train 1 2 3 4 5 6 7 8 9 10 for batch in data_iter:for x in batch]'<bos>' ]] * Y.shape[0 ],1 , 1 )1 ]], 1 ) sum ().backward() 1 )
predict 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def predict_seq2seq (net, src_sentence, src_vocab, tgt_vocab, num_steps, device, save_attention_weights=False ):"""序列到序列模型的预测""" eval ()' ' )] + ['<eos>' ]]len (src_tokens)], device=device)'<pad>' ])0 )'<bos>' ]], dtype=torch.long, device=device), dim=0 )for _ in range (num_steps):2 )0 ).type (torch.int32).item()if save_attention_weights:if pred == tgt_vocab['<eos>' ]:break return ' ' .join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
QA:
word2vec没讲,跳过了
transformer可以代替seq2seq
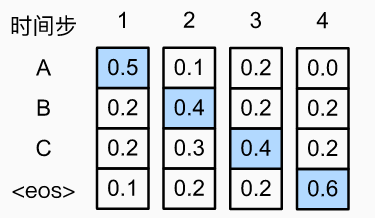
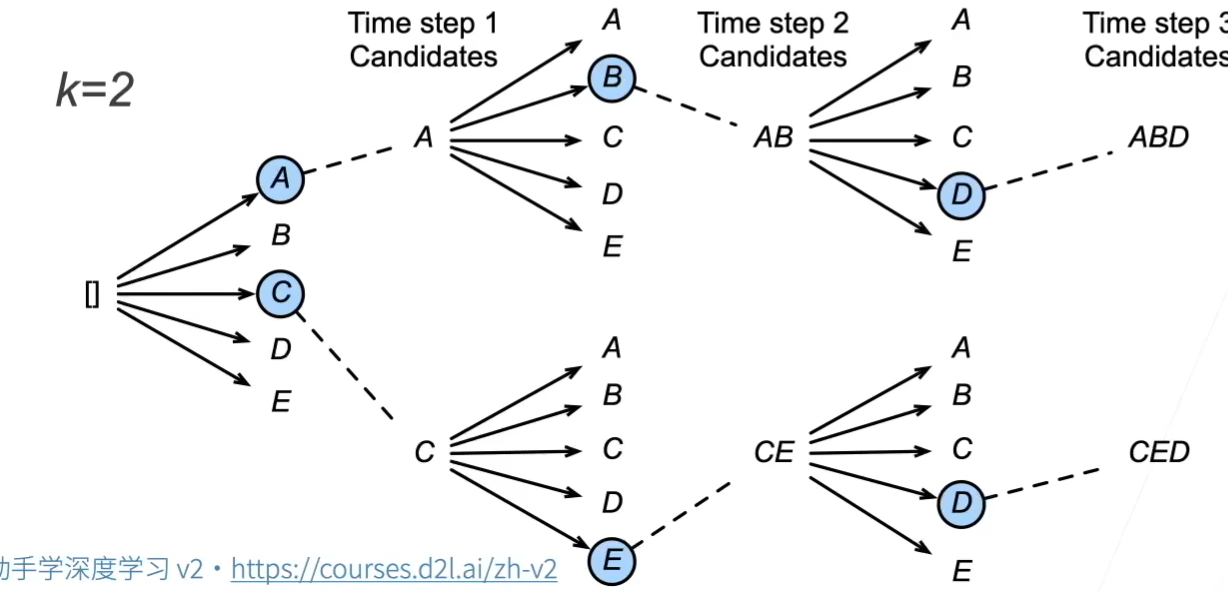
束搜索 预测时,每一步都是取最优的(贪心),但贪心不一定是全局最优,例如下面第二步取C
穷举:指数级 太大了
束搜索:每次在所有kn个选项中,保留k个最大的。只保留一个就是贪心
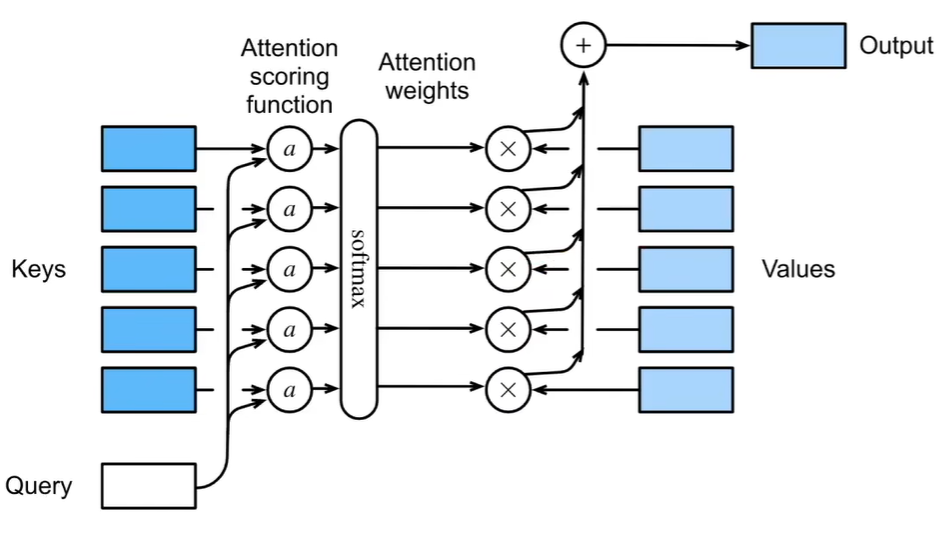
注意力 attention query:输入 key,value :已有的一些数据
核心:根据query和keyi的关系,决定出valuei的权重,加权得到一个最终value
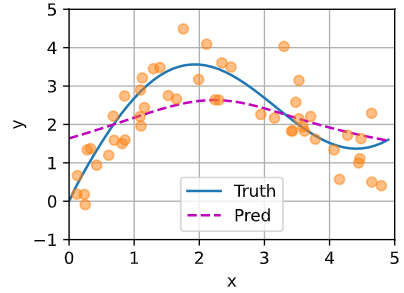
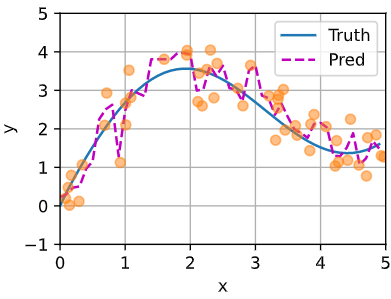
核回归 非参数 query为输入x,根据数据((xi,yi))给出预测y。xi-yi是keys-values
最简单的是对y的数据求平均,这样每个数据给出的f(x)都一样
根据一个权重,加权求和。权重为根据K(距离)函数求出来的。如果k是高斯核,就等价于用高斯距离softmax加权
1 2 3 4 5 6 7 8 9 1 , n_train))2 / 2 , dim=1 )
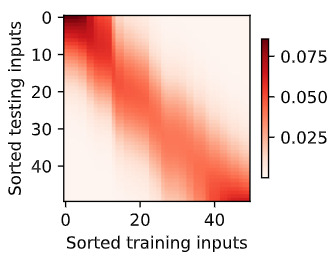
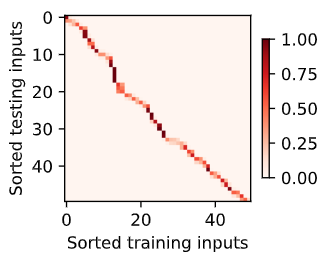
一行代表,对哪个inpute的权重更大。权重给的比较平滑,所以pred也比较平滑
参数化 引入可学习的w=nn.Parameter(torch.rand((1,), requires_grad=True)) 控制高斯核的窗口大小,w越大窗口越小
窗口更窄了,只给离得近的分配权重,所以pred更加弯曲
注意力分数 拓展到高维 情况,q k v都是向量
Scaled Dot
k和q长度一样:kq做内积后除去根号dk。transformer。两次矩阵乘法,无学习的参数,去除根号d防止梯度问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class DotProductAttention (nn.Module):"""Scaled dot product attention. Defined in :numref:`subsec_additive-attention`""" def __init__ (self, dropout, **kwargs ):super (DotProductAttention, self ).__init__(**kwargs)self .dropout = nn.Dropout(dropout)def forward (self, queries, keys, values, valid_lens=None ):1 ]1 ,2 )) / math.sqrt(d)self .attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self .dropout(self .attention_weights), values)
additive
k和q长度一样:k和q concat输入到隐藏层为h输出为1的MLP,再乘上vT输出为分数值。有参
对于每一个query,我都需要得到一个len(“键-值”对)的向量,多个query就是一个weight矩阵 [len(query), len(“键-值”对)],weight*values得到加权输出[querys, d(v)]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class AdditiveAttention (nn.Module):"""加性注意力""" def __init__ (self, key_size, query_size, num_hiddens, dropout, **kwargs ):super (AdditiveAttention, self ).__init__(**kwargs)self .W_k = nn.Linear(key_size, num_hiddens, bias=False )self .W_q = nn.Linear(query_size, num_hiddens, bias=False )self .w_v = nn.Linear(num_hiddens, 1 , bias=False )self .dropout = nn.Dropout(dropout)def forward (self, queries, keys, values, valid_lens ):self .W_q(queries), self .W_k(keys)2 ) + keys.unsqueeze(1 )self .w_v(features).squeeze(-1 )self .attention_weights = masked_softmax(scores, valid_lens) return torch.bmm(self .dropout(self .attention_weights), values)
dropout增加模型的泛化能力
应用:key value query到底是什么
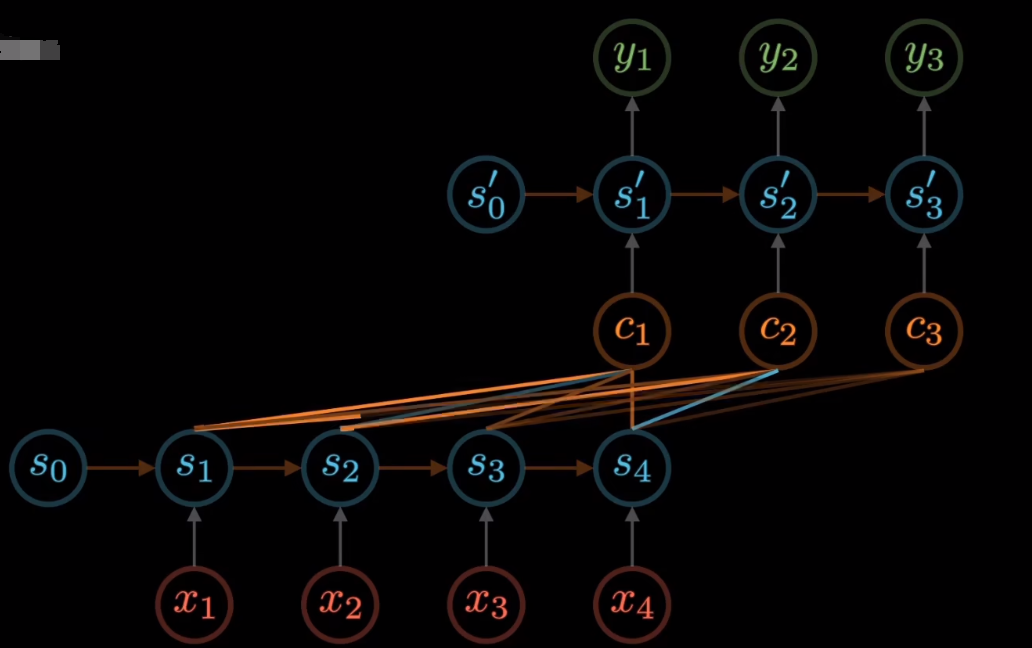
Bahdanau seq2seq 翻译时额外添加原句子的对应信息,而不是只用最后一个state。具体用以前的哪个state由attention决定
key-value:编码器每一次的RNN 的输出states
query:解码器上一次输出
对比之前的改进:之前context直接用最后一个state,现在对所有state拿出来做一个weight
query:当前state[-1] [batch_size,1,num_hiddens] key-value: encoder的output[batch_size,num_steps,num_hiddens]
以前的context :t次都一样,都是最后的state
1 2 3 4 1 ].repeat(X.shape[0 ], 1 , 1 )2 )self .rnn(X_and_context, state) 直接一次性输入到网络
现在的context: 每次都不一样,为output的加权。C=attention(pre-state, (h1,h2...ht)) 不一样所以需要遍历
query为上次state[-1],代表着当前状态 [batch_size, query=1, num_hiddens] 当前状态的维度为num_hiddenskey-value = enc_outputs是encoder的output转置下 [batch_size, num_steps, num_hiddens] 代表着有t次状态,每个状态的维度为num_hiddens,attention对t次状态加权后得到[batch_size, query=1, num_hiddens], 权重矩阵为[b, query=1, num_steps]
1 2 3 4 5 6 7 8 9 10 for x in X: 1 ], dim=1 )self .attention(query, enc_outputs, enc_outputs, enc_valid_lens)1 )), dim=-1 )self .rnn(x.permute(1 , 0 , 2 ), hidden_state)
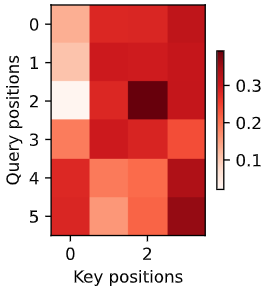
纵坐标为生成的token['<bos>', 'je', 'suis', 'chez', 'moi', '.', '<eos>']["i'm", 'home', '.', '<eos>']
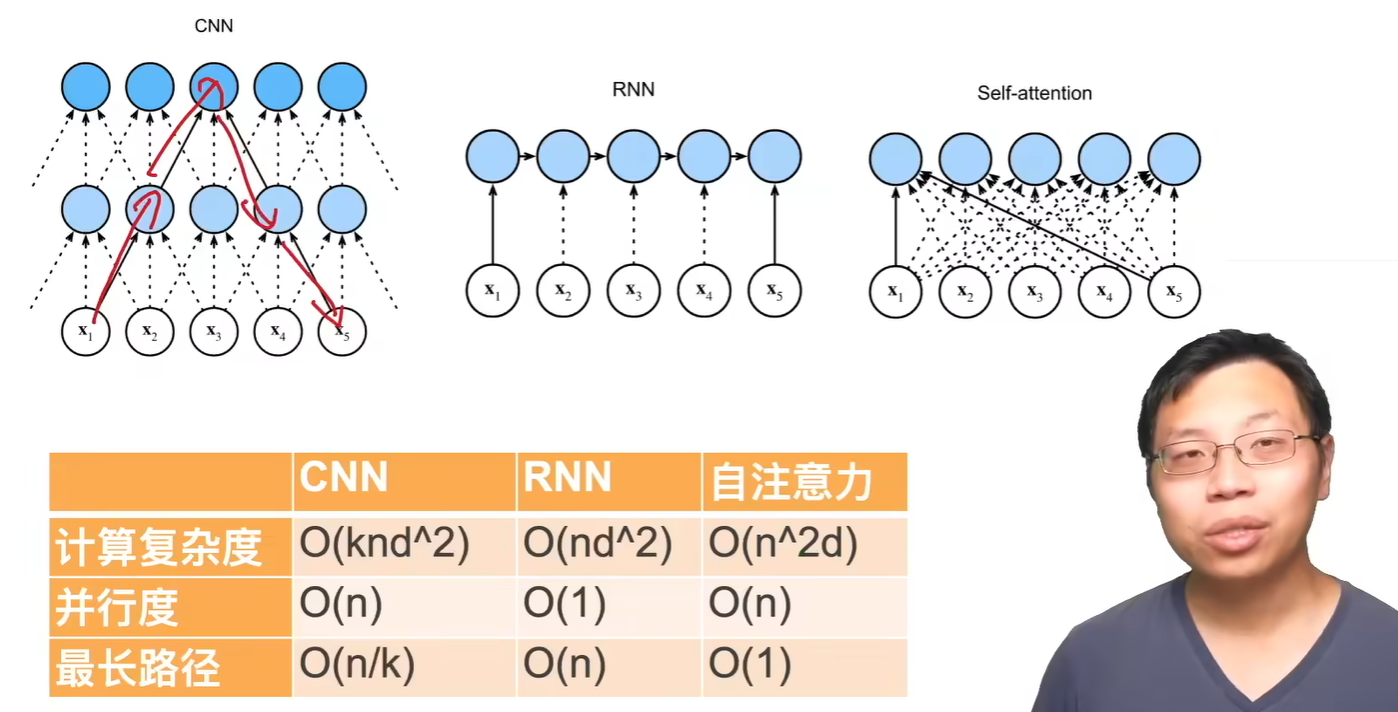
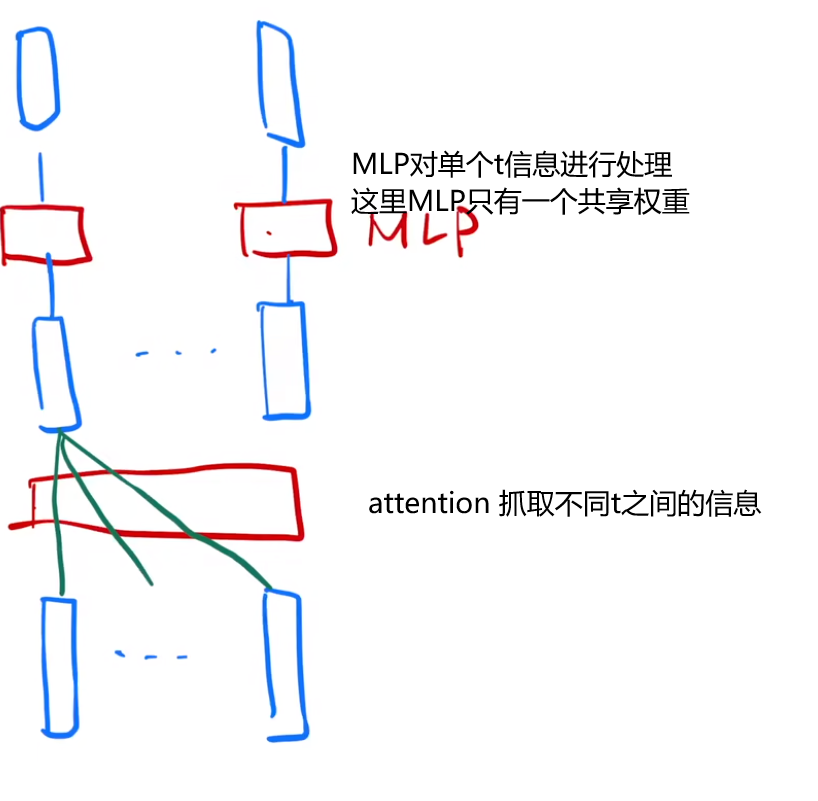
self-attention! 同时拉取汇聚全部时间的信息
key value query都是x
code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 self .attention(query, enc_outputs, enc_outputs)self .attention(X, X, X)self .attention(X, X, X, 1 , num_steps + 1 , device=X.device).repeat(batch_size, 1 ))0 ], state[1 ]2 ][self .i], X), axis=1 )2 ][self .i] = key_valuesself .attention1(X, key_values, key_values, dec_valid_lens=None )self .addnorm1(X, X2)
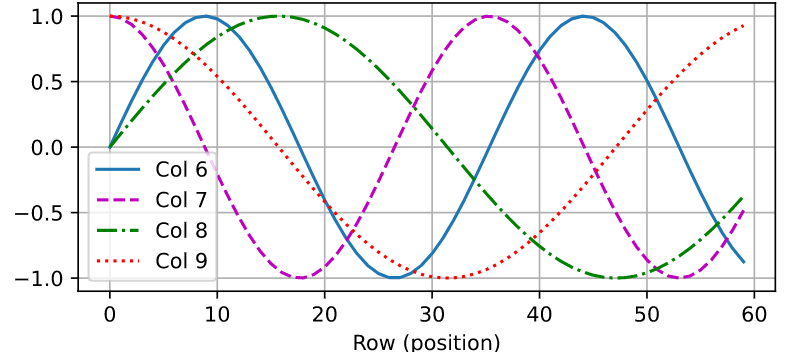
pos-encoding 失去了位置信息,添加上位置P矩阵。n个词i,每个d维j。也可以是可学习(BERT)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1 , max_len, num_hiddens]class PositionalEncoding (nn.Module):"""位置编码""" def __init__ (self, num_hiddens, dropout, max_len=1000 ):super (PositionalEncoding, self ).__init__()self .dropout = nn.Dropout(dropout)self .P = torch.zeros((1 , max_len, num_hiddens))1 , 1 ) / torch.pow (10000 , torch.arange(0 , num_hiddens, 2 , dtype=torch.float32) / num_hiddens)self .P[:, :, 0 ::2 ] = torch.sin(X)self .P[:, :, 1 ::2 ] = torch.cos(X)def forward (self, X ):self .P[:, :X.shape[1 ], :].to(X.device)return self .dropout(X)
QA:
self-attention理解为一个layer,有输入输出
BERT 其实是纯self-attention + context-attention
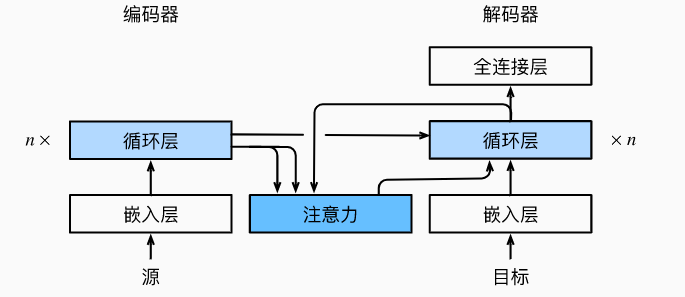
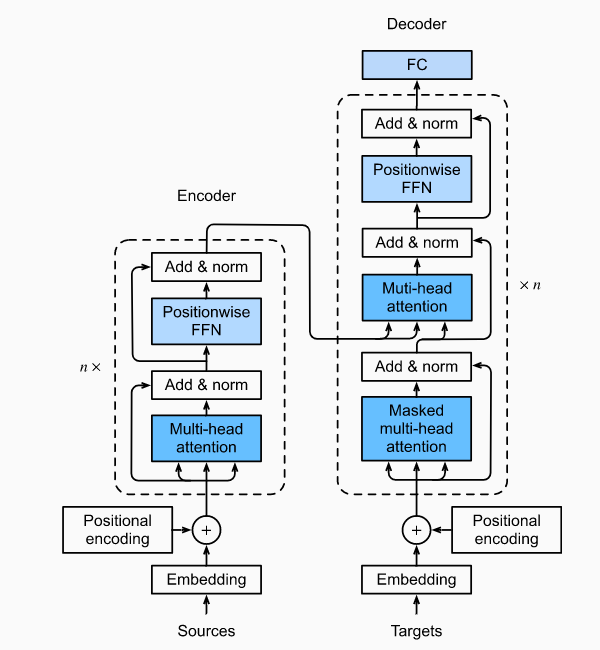
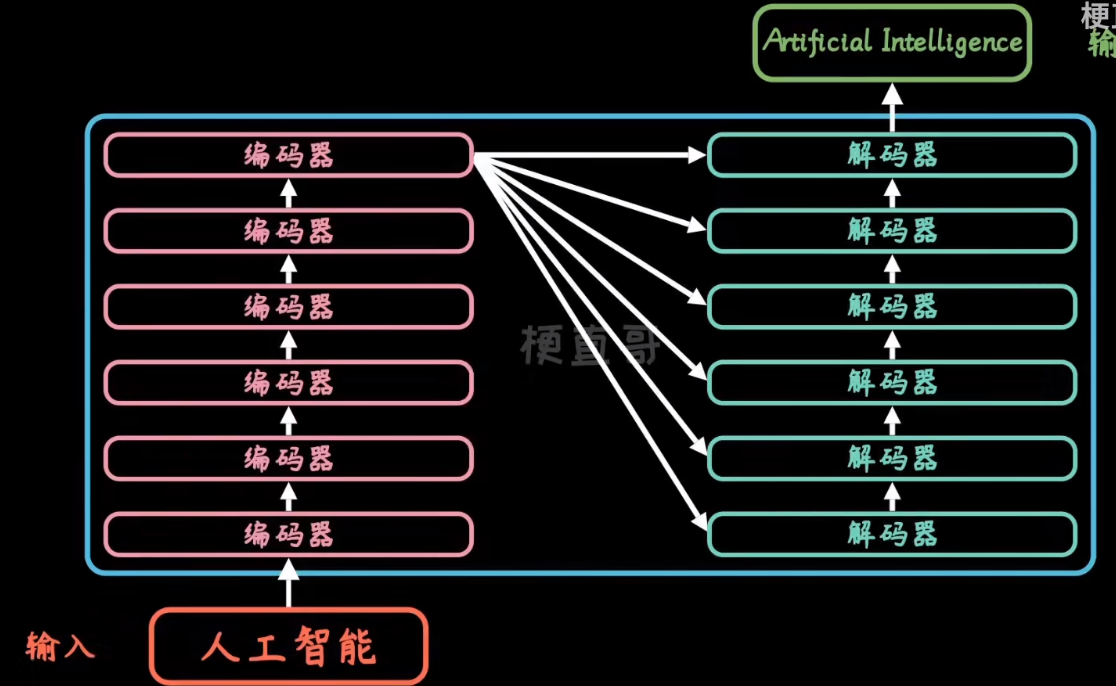
encoder-decoder架构
纯注意力,n个transformer块
block input-output形状一样
编码器的状态信息会同时传给每一个解码器block
muti-head-attention 多个dot attention,也就是多个h。dot attention通过一个多头相当于添加了可学习参数
1 2 3 4 5 6 7 num_hiddens, num_heads = 100 , 5 0.5 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 for 循环class MultiHeadAttention (nn.Module):"""多头注意力""" def __init__ (self, key_size, query_size, value_size, num_hiddens, num_heads, dropout, bias=False , **kwargs ):super (MultiHeadAttention, self ).__init__(**kwargs)self .num_heads = num_headsself .attention = d2l.DotProductAttention(dropout)self .W_q = nn.Linear(query_size, num_hiddens, bias=bias)self .W_k = nn.Linear(key_size, num_hiddens, bias=bias)self .W_v = nn.Linear(value_size, num_hiddens, bias=bias)self .W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward (self, queries, keys, values, valid_lens ):self .W_q(queries), self .num_heads)self .W_k(keys), self .num_heads)self .W_v(values), self .num_heads)if valid_lens is not None :self .num_heads, dim=0 )self .attention(queries, keys, values, valid_lens)self .num_heads)return self .W_o(output_concat)
FFN 基于位置的前馈网络两层 MLP,[b, t, in] -> [b, t, out]
self-attention是在不同的t之间汇聚信息,而mlp对单个t中的in信息做处理
1 2 3 4 5 6 7 8 9 10 11 12 class PositionWiseFFN (nn.Module):"""基于位置的前馈网络""" def __init__ (self, ffn_num_input=512 , ffn_num_hiddens=2048 , ffn_num_outputs=512 , **kwargs ):super (PositionWiseFFN, self ).__init__(**kwargs)self .dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self .relu = nn.ReLU()self .dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward (self, X ):return self .dense2(self .relu(self .dense1(X)))
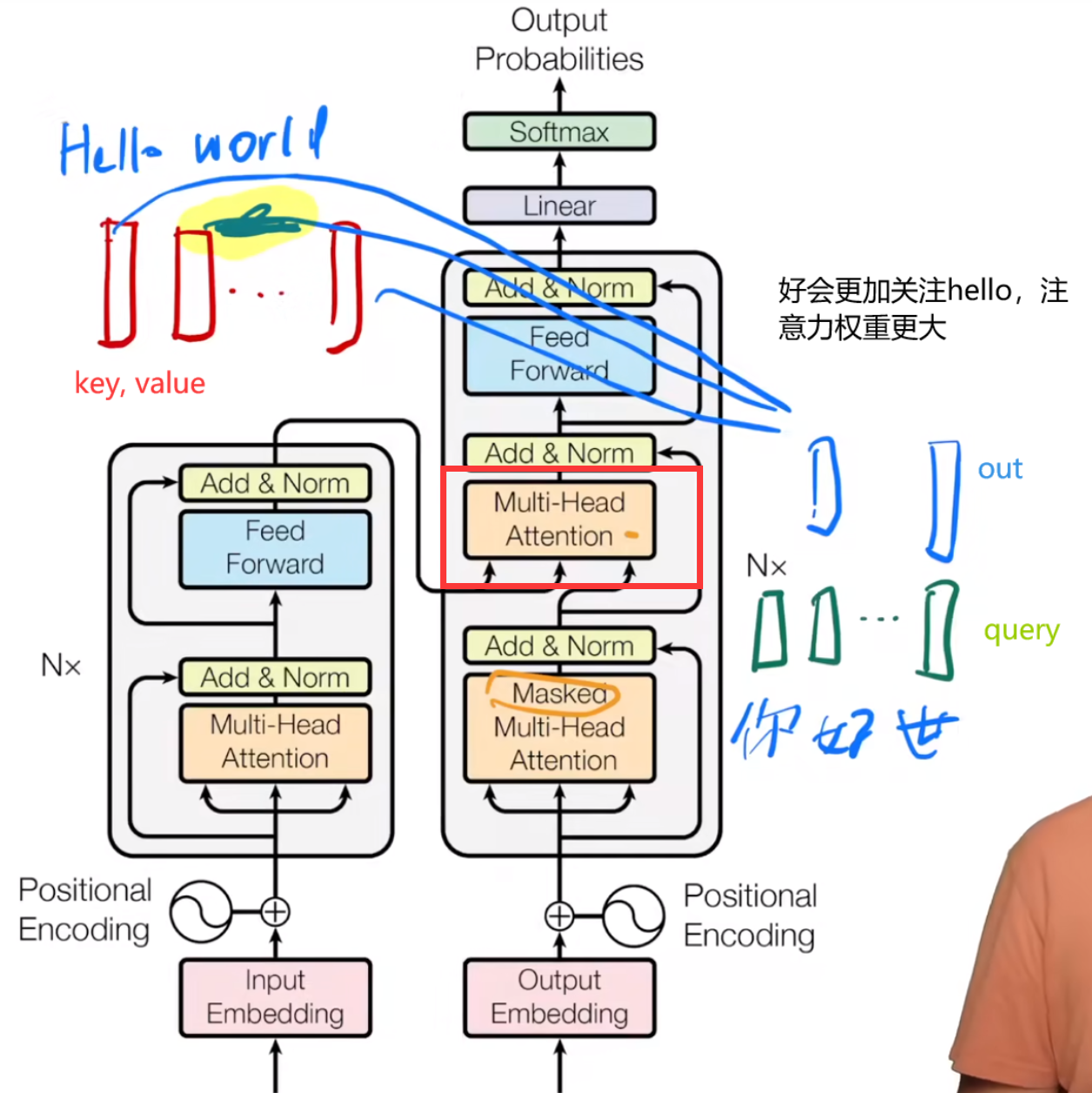
mask-Mutiattention predict时,不能使用未来的信息,通过设置有效的attention长度
1 2 3 4 5 6 7 8 9 10 11 12 if self .training:1 , num_steps + 1 , device=X.device).repeat(batch_size, 1 )else :None self .attention1(X, X, X, dec_valid_lens) self .addnorm1(X, X2)
Context Attention decoder第二层为context attention,query当前状态,keyvalue为encoder的输出
1 2 3 enc_outputs, enc_valid_lens = state[0 ], state[1 ]self .attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)self .addnorm2(Y, Y2)
AddNorm 残差标准化
1 2 3 4 5 6 7 8 9 10 class AddNorm (nn.Module):"""残差连接后进行层规范化""" def __init__ (self, normalized_shape, dropout, **kwargs ):super (AddNorm, self ).__init__(**kwargs)self .dropout = nn.Dropout(dropout)self .ln = nn.LayerNorm(normalized_shape)def forward (self, X, Y ):return self .ln(self .dropout(Y) + X)
Encoderblock MultiHeadAttention + addnorm1 + ffn + addnorm2 输入输出维度不变
1 2 3 4 5 X = torch.ones((2 , 100 , 24 ))3 , 2 ])24 , 24 , 24 , 24 , [100 , 24 ], 24 , 48 , 8 , 0.5 )eval ()2 , 100 , 24 ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class EncoderBlock (nn.Module):"""Transformer编码器块""" def __init__ (self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias=False , **kwargs ):super (EncoderBlock, self ).__init__(**kwargs)self .attention = d2l.MultiHeadAttention(self .addnorm1 = AddNorm(norm_shape, dropout)self .ffn = PositionWiseFFN(self .addnorm2 = AddNorm(norm_shape, dropout)def forward (self, X, valid_lens ):self .addnorm1(X, self .attention(X, X, X, valid_lens))return self .addnorm2(Y, self .ffn(Y))
Encoder 多个block堆叠。embedding + pos_encoding + 多个EncoderBlock
1 2 3 4 5 encoder = TransformerEncoder(200 , 24 , 24 , 24 , 24 , [100 , 24 ], 24 , 48 , 8 , 2 , 0.5 )eval ()2 , 100 ), dtype=torch.long), valid_lens).shape2 , 100 , 24 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class TransformerEncoder (d2l.Encoder):"""Transformer编码器""" def __init__ (self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, use_bias=False , **kwargs ):super (TransformerEncoder, self ).__init__(**kwargs)self .num_hiddens = num_hiddensself .embedding = nn.Embedding(vocab_size, num_hiddens)self .pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self .blks = nn.Sequential()for i in range (num_layers):self .blks.add_module("block" +str (i),def forward (self, X, valid_lens, *args ):self .pos_encoding(self .embedding(X) * math.sqrt(self .num_hiddens))self .attention_weights = [None ] * len (self .blks)for i, blk in enumerate (self .blks):self .attention_weights[return X
Decoderblock 需要自己的输入和encoder的输出。输入输出维度不变!
self-MultiHeadAttention + addnorm1 + MultiHeadAttention(编码器解码器注意力) + addnorm2 + fnn + addnorm3
第一次mask-self-attention就是attention1(X, X, X, dec_valid_lens),dec_valid_lens保证不看后面
第二次需要用到encoder输出attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class DecoderBlock (nn.Module):"""解码器中第i个块""" def __init__ (self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs ):super (DecoderBlock, self ).__init__(**kwargs)self .i = iself .attention1 = d2l.MultiHeadAttention(self .addnorm1 = AddNorm(norm_shape, dropout)self .attention2 = d2l.MultiHeadAttention(self .addnorm2 = AddNorm(norm_shape, dropout)self .ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,self .addnorm3 = AddNorm(norm_shape, dropout)def forward (self, X, state ):0 ], state[1 ]if state[2 ][self .i] is None :else :2 ][self .i], X), axis=1 )2 ][self .i] = key_valuesif self .training:1 , num_steps + 1 , device=X.device).repeat(batch_size, 1 )else :None self .attention1(X, key_values, key_values, dec_valid_lens)self .addnorm1(X, X2)self .attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)self .addnorm2(Y, Y2)return self .addnorm3(Z, self .ffn(Z)), state
1 2 3 4 5 decoder_blk = DecoderBlock(24 , 24 , 24 , 24 , [100 , 24 ], 24 , 48 , 8 , 0.5 , 0 )eval ()2 , 100 , 24 ))None ]]0 ].shape
Decoder embedding + pos_encoding + 多个decoderBlock + dense;decoderBlock需要的state训练时不变,都是encoder给的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class TransformerDecoder (d2l.AttentionDecoder):def __init__ (self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, **kwargs ):super (TransformerDecoder, self ).__init__(**kwargs)self .num_hiddens = num_hiddensself .num_layers = num_layersself .embedding = nn.Embedding(vocab_size, num_hiddens)self .pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self .blks = nn.Sequential()for i in range (num_layers):self .blks.add_module("block" +str (i),self .dense = nn.Linear(num_hiddens, vocab_size)def init_state (self, enc_outputs, enc_valid_lens, *args ):return [enc_outputs, enc_valid_lens, [None ] * self .num_layers]def forward (self, X, state ):self .pos_encoding(self .embedding(X) * math.sqrt(self .num_hiddens))self ._attention_weights = [[None ] * len (self .blks) for _ in range (2 )]for i, blk in enumerate (self .blks):self ._attention_weights[0 ][self ._attention_weights[1 ][return self .dense(X), state @property def attention_weights (self ):return self ._attention_weights
train num_hiddens 512 1024, num_heads 8 16
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 num_hiddens, num_layers, dropout, batch_size, num_steps = 32 , 2 , 0.1 , 64 , 10 0.005 , 200 , d2l.try_gpu()32 , 64 , 4 32 , 32 , 32 32 ]len (src_vocab), key_size, query_size, value_size, num_hiddens,len (tgt_vocab), key_size, query_size, value_size, num_hiddens,
预测 预测t+1:前t个转为key value,第t个为query
QA:
concat特征比加权平均好
transfomer硬件要求还好,BERT很大
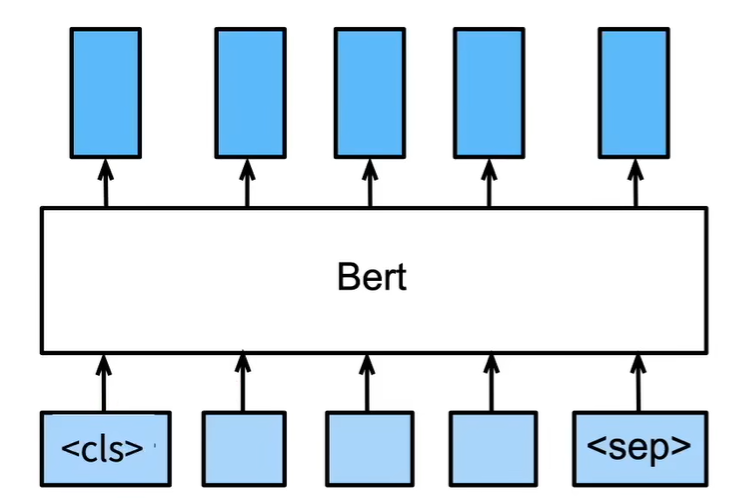
很多模型只有encoder,如bert
可以处理图片,抠出一个个patch
BERT 使用预训练模型提取句子特征,如word2vec(忽略时序)。预训练模型可以不更新,只修改output layer
只有transformer的encoder:block=12 24 hiddensize=768 1024 head=12 16 parameters=110 340M 10亿个词
输入
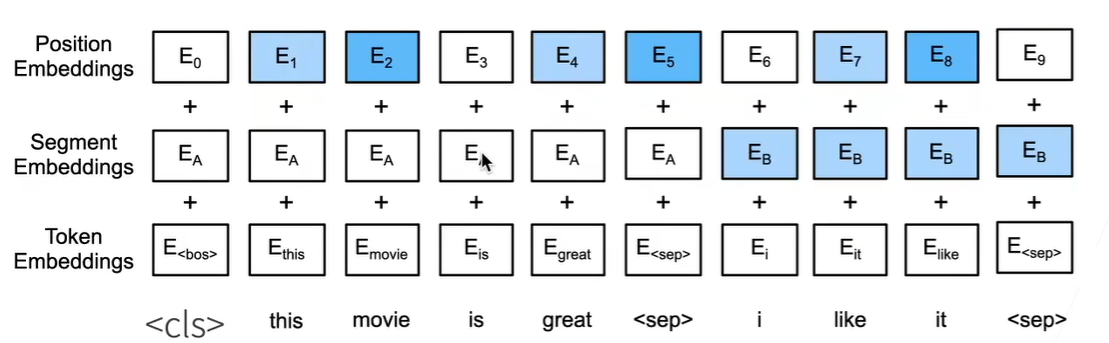
Segment:没有解码器,所以输入输出都输入到encoder,用分开并且添加额外编码
Position:可学习
Token:普通编码
训练任务 带掩码 transformer是双向的,如何做单向预测?
带掩码的语言模型:15%将一些词作为,完形填空
微调任务时,压根没有没有mask,让模型能在有答案情况下填空:对于mask 80%不变、10%保持、10%替换别的
下一句子预测 句子是不是相邻
BERT代码 1.对token添加
1 2 3 4 5 6 7 8 9 10 def get_tokens_and_segments (tokens_a, tokens_b=None ):"""获取输入序列的词元及其片段索引""" '<cls>' ] + tokens_a + ['<sep>' ]0 ] * (len (tokens_a) + 2 )if tokens_b is not None :'<sep>' ]1 ] * (len (tokens_b) + 1 )return tokens, segments
BERTEncoder 输入tokens,segments [b, t],返回[b, t, hidden]。Encoder中包含pos_embedding
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class BERTEncoder (nn.Module):"""BERT编码器""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , **kwargs ):super (BERTEncoder, self ).__init__(**kwargs)self .token_embedding = nn.Embedding(vocab_size, num_hiddens)self .segment_embedding = nn.Embedding(2 , num_hiddens)self .blks = nn.Sequential()for i in range (num_layers):self .blks.add_module(f"{i} " , d2l.EncoderBlock(True ))self .pos_embedding = nn.Parameter(torch.randn(1 , max_len,def forward (self, tokens, segments, valid_lens ):self .token_embedding(tokens) + self .segment_embedding(segments)self .pos_embedding.data[:, :X.shape[1 ], :]for blk in self .blks:return X
MaskLM 对编码器的输出特征encoded_X,在指定位置上pred_positions,提取出该位置特征masked_X去分类
encoded_X:[b, t, hidden] pred_positions:[b, num_pred] masked_X:[b, num_pred, hidden]
out: [b, num_pred, vocab_size]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class MaskLM (nn.Module):"""BERT的掩蔽语言模型任务""" def __init__ (self, vocab_size, num_hiddens, num_inputs=768 , **kwargs ):super (MaskLM, self ).__init__(**kwargs)self .mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),def forward (self, X, pred_positions ):1 ]1 )0 ]0 , batch_size)1 ))self .mlp(masked_X)return mlm_Y_hat
NextSentencePred 对encoded_X[:, 0, :]的特征进行分类
1 2 3 4 5 6 7 8 9 10 class NextSentencePred (nn.Module):"""BERT的下一句预测任务""" def __init__ (self, num_inputs, **kwargs ):super (NextSentencePred, self ).__init__(**kwargs)self .output = nn.Linear(num_inputs, 2 )def forward (self, X ):return self .output(X)
BERTModel 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class BERTModel (nn.Module):"""BERT模型""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , hid_in_features=768 , mlm_in_features=768 , nsp_in_features=768 ):super (BERTModel, self ).__init__()self .encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,self .hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),self .mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self .nsp = NextSentencePred(nsp_in_features)def forward (self, tokens, segments, valid_lens=None , pred_positions=None ):self .encoder(tokens, segments, valid_lens)if pred_positions is not None :self .mlm(encoded_X, pred_positions)else :None self .nsp(self .hidden(encoded_X[:, 0 , :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
数据集
需要先获得 tokens, segments, is_next ; segments为0、1用于区别句子
对tokens进行mask替换,返回tokens,positions,positions上原词汇mlm_Y
pad 和对应 valid_lens。all_mlm_weights0或1用于过滤掉mask中,属于pad的词
1 2 3 4 5 for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y) in train_iter.Size ([512, 64] ) torch.Size ([512, 64] ) torch.Size ([512] ) torch.Size ([512, 10] ) torch.Size ([512, 10] ) torch.Size ([512, 10] ) torch.Size ([512] )0 或1 用于过滤掉mask 中,属于pad的词
训练 训练是不需要encoder_X,为了提升模型抽取encoder的能力
1 2 3 4 5 6 7 net = d2l.BERTModel(len (vocab), num_hiddens=128 , norm_shape=[128 ],128 , ffn_num_hiddens=256 , num_heads=2 ,2 , dropout=0.2 , key_size=128 , query_size=128 ,128 , hid_in_features=128 , mlm_in_features=128 ,128 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def _get_batch_loss_bert (net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y ):1 ),1 , vocab_size), mlm_Y.reshape(-1 )) *\1 , 1 )sum () / (mlm_weights_X.sum () + 1e-8 )return mlm_l, nsp_l, l
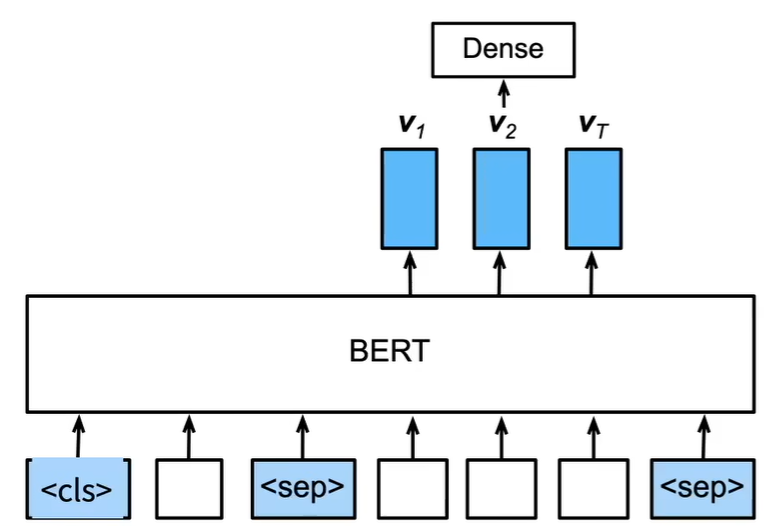
BERT表示文本 利用BERT获得句子的encoded_X,去进行分类、预测等
1 2 3 4 5 6 7 def get_bert_encoding (net, tokens_a, tokens_b=None ):0 ]).unsqueeze(0 )0 ]).unsqueeze(0 )len (tokens), device=devices[0 ]).unsqueeze(0 )return encoded_X
1 2 3 4 5 6 7 8 tokens_a = ['a' , 'crane' , 'is' , 'flying' ]1 , 6 , 128 ]0 , :] [1 , 128 ]'a' , 'crane' , 'driver' , 'came' ], ['he' , 'just' , 'left' ]
QA:
模型太大? model分在不同GPU上
微调BERT 利用bert对每个词都抽取了特征,我们不需要考虑如何抽取句子特征、词特征了。只需要添加输出层。需要相同Vocab
code 只需要用上encoder,hidden是bert中输出到NSP前的处理,这里也用上;相对于替换了NSP
1 2 3 4 5 6 7 8 9 10 11 class BERTClassifier (nn.Module):def __init__ (self, bert ):super (BERTClassifier, self ).__init__()self .encoder = bert.encoderself .hidden = bert.hiddenself .output = nn.Linear(256 , 3 )def forward (self, inputs ):self .encoder(tokens_X, segments_X, valid_lens_x)return self .output(self .hidden(encoded_X[:, 0 , :]))
QA:
YOLO基础效果不好,但加了大量trick细节
通过蒸馏十分之一大小,但精度不会下降很多