CPU故障排查
GPT摘要
在压测考试期间,作者发现resource、teacher-admin等微服务的CPU利用率达到100%,但相关负责同学并不了解原因。经过排查,作者发现需要进入pod内部使用jstack等工具进行线程分析,但pod基于jre镜像构建,缺少jdk工具,因此通过配置阿里云镜像源并安装procps、openjdk-11-jdk等工具解决了环境问题。 作者通过TOP命令定位进程pid,结合ps和jstack命令分析线程执行情况,但未能获取具体代码信息,转而使用arthas工具。通过arthas最终定位到问题代码——一段为nacos添加配置监听器的逻辑。开发同学误解了官方文档中while(true)的作用,错误地认为需要保持线程存活以防止守护线程退出(实际nacos会自动维护监听线程)。这段冗余代码导致CPU持续满载,若多次调用甚至会使CPU占用达200%。 问题代码位于公共模块的静态代码块中,当类被加载时会触发,导致部分pod出现高CPU现象。此外,该问题引发k8s集群动态扩容,加剧了资源消耗。修复后,集群CPU使用率显著下降,并缩减了3台4核16G的机器资源。作者强调,正式代码中无需保留while循环,仅需正确使用addListener即可,同时指出即使保留Thread.sleep(1000)也不会导致CPU满载。最终问题根源在于对守护线程机制的误解和冗余代码的设计。
CPU故障排查
背景
在压测考试的时候,无意间看到resource、teacher-admin等微服务CPU利用率百分之百,询问相关负责同学并不了解,于是自己寻找了一下原因。
方法
jstack
jstack可以定位线程的执行情况,因此直接进入pod内部执行,发现并没有找到此命令,查看dockerfile打包文件发现打包时是基于jre镜像构建的,并没有jdk中的其他工具,因此需要先安装工具。此外TOP等命令也没有,需要安装
1 | |
- 执行TOP命令,定位微服务pid
- 执行
ps H -eo pid, tid, %cpu | grep pid搜索出线程id以及cpu printf '0x%x\n' pid将线程id转为16进制jstack pid | grep 线程id查看线程执行的情况
最后jstack定位发现该线程为守护进程,并没有给出具体的代码行以及其他信息,因此转向其他工具
arthas
1 | |
arthas给出了线程执行的代码行,直接定位到了错误代码,如下图

至此错误的原因找到了。
分析
这段代码的目的是为nacos添加一个推送变更配置,当dataid发生变化时,执行listener保存下最新的配置,官方文档如下
1 | |
但编码的同学理解错误了文档中while true的作用,当执行完addListener后,nacos会自动创建守护进程监听配置变化,如果所有非守护进程结束该守护进程才会结束,所以正式部署中并不需要执行addListener的线程一直存活,整个微服务当然会有非守护进程在执行,这段代码直接删去即可。
此外,如果没有删除官方文档中的Thread.sleep(1000); 即便编码是错误的方式,其实也不会导致cpu直接占满
结论
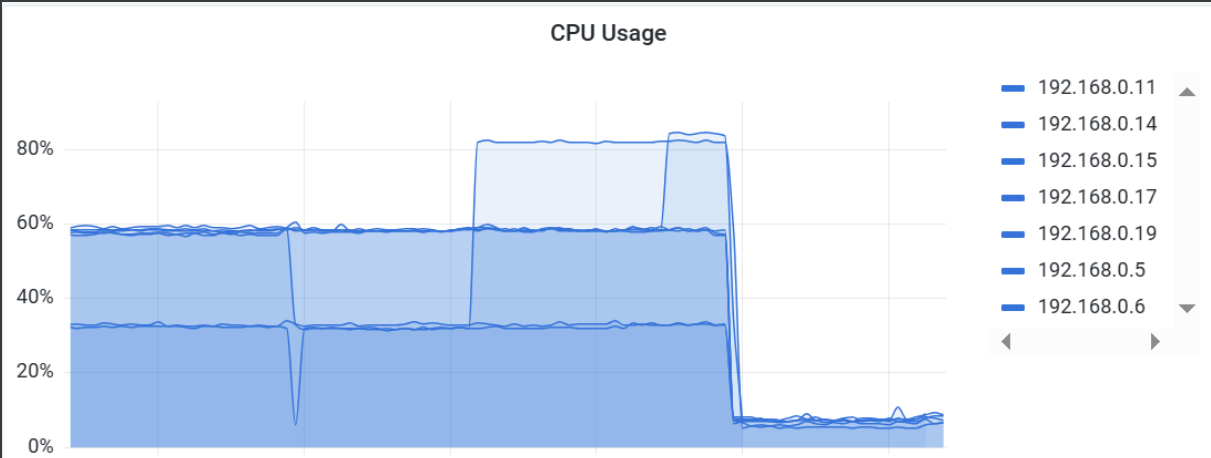
- 该段代码是在某些类的static代码块中调用,只有类被加载时才会导致该bug触发,所以可以看到图中有少部分pod并没有占满cpu
- 这个bug直接导致pod上cpu利用率占满(如果addListener两次,CPU直接会到200%),并且会触发动态扩容策略,导致第一张图中的一群pod中cpu都占满;
- 该代码编写在common中,导致用到的所有微服务(如resource、course)都会触发
- 修复后k8s集群整体cpu大幅度下降,弹性伸缩关闭了3台4核16G机器