GPT摘要
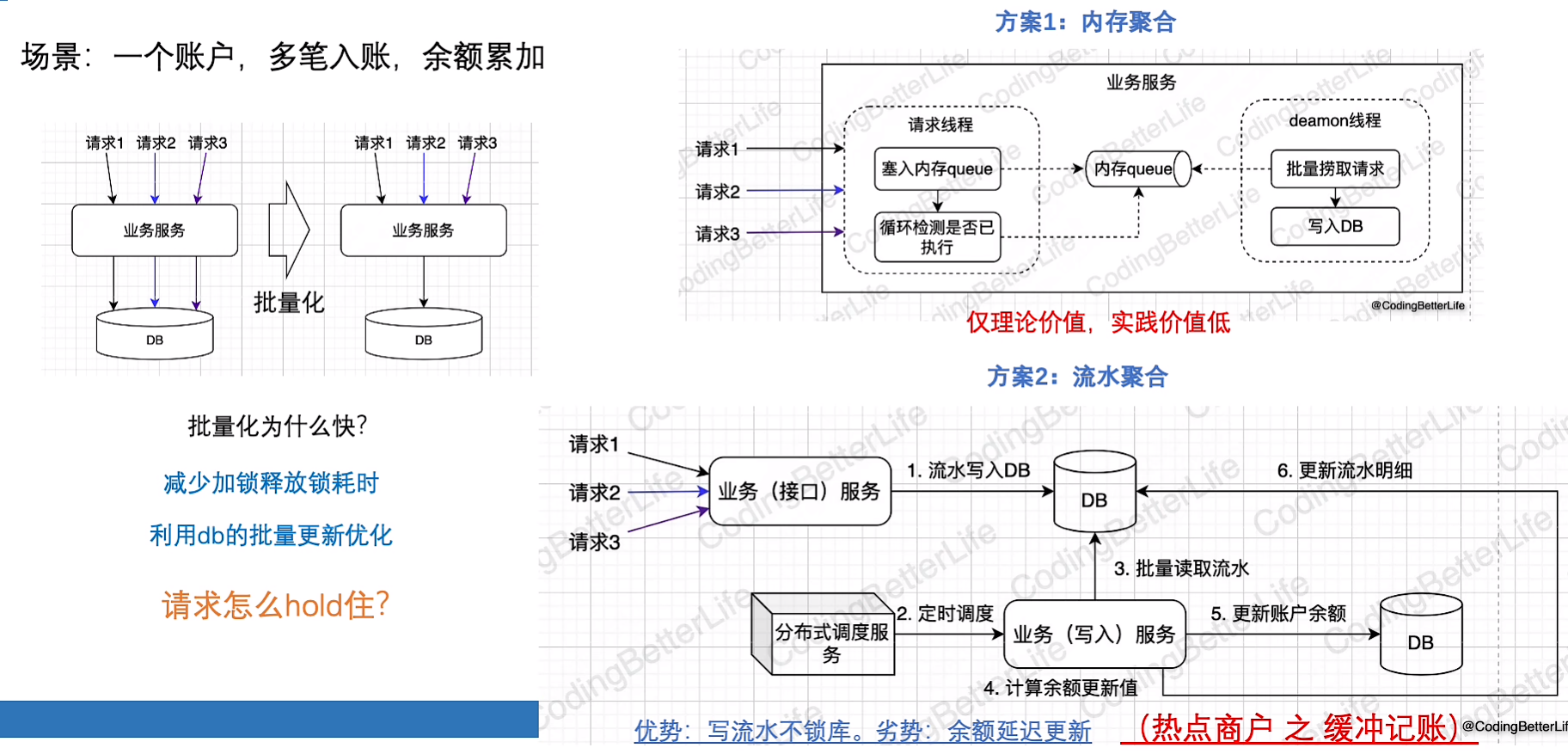
这篇文章主要围绕软件开发中的设计模式、系统架构优化和故障处理展开,以下是摘要内容: 1. 学习能力与代码优化 - 知识更新快、需求变化多,需通过优化代码结构应对(如避免重复代码)。提出两种方案: - 方案1:工具类统一逻辑,标准化流程 - 方案2:模板方法模式(Java示例),固定调用顺序,集中处理日志/错误 2. 领域驱动设计(DDD)与流程引擎 - 通过事件风暴建模划分业务边界(如电商场景),抽象核心领域模型(订单、支付)。 - 分层架构:接口层(校验格式)、服务层(编排流程)、领域层(规则实现)、数据层(单纯CRUD)。 - 流程引擎实践:将业务拆分为处理器(Processor),通过模板或JSON配置驱动流程(如转账、风控)。 3. 设计模式应用 - 责任链模式:处理参数校验(如多条件依次验证)。 - 策略模式:动态选择通知方式(短信/邮件)。 - 观察者模式:异步处理非主链路操作(如打点监控)。 - 状态编排:通过事件驱动状态机(如订单状态流转)。 4. 高并发与扩展性 - 读优化:多级缓存(本地+Redis)、缓存策略(延迟双删)。 - 写优化:批量操作、缓冲记账(先写文件再同步DB)。 - 分库分表:按用户ID哈希路由,隔离资源。 5. 容错与稳定性 - 幂等设计:唯一ID+流水表防重。 - 降级策略:非核心依赖熔断(如查询余额忽略账单服务)。 - 监控:日志采集、链路追踪、定时对账。 6. 故障预防与发布 - 灰度发布:按用户ID分段生效。 - 回滚机制:兼容性设计(新旧代码并存)。 - 全链路压测:模拟真实流量验证性能。 7. 异常处理规范 - 系统内用异常中断流程,RPC接口返回错误码。 - 区分业务异常(如余额不足)与系统异常(如DB超时)。 总结:通过设计模式解耦、领域建模明确边界、分层架构隔离变化,结合流程引擎提升扩展性,再辅以缓存/容错/监控保障稳定性,最终实现高内聚低耦合的系统设计。
https://www.bilibili.com/video/BV1pz4y1j72C
1.大学学点啥
学习能力
2.搭建系统先搭架子
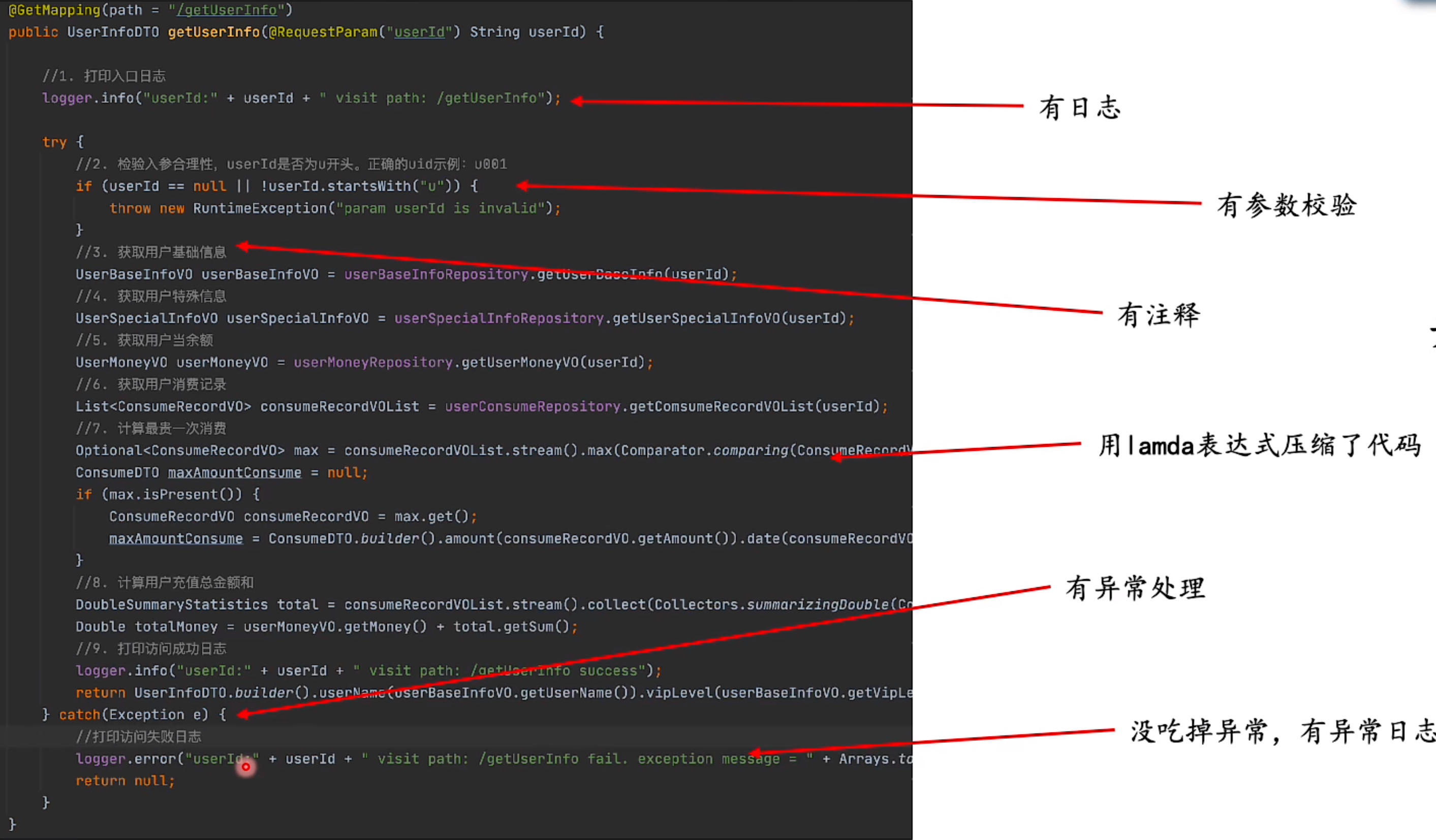
1.用户首页
(用户信息、余额、消费等)
2.新需求
需要添加用户修改功能;存在许多重复代码
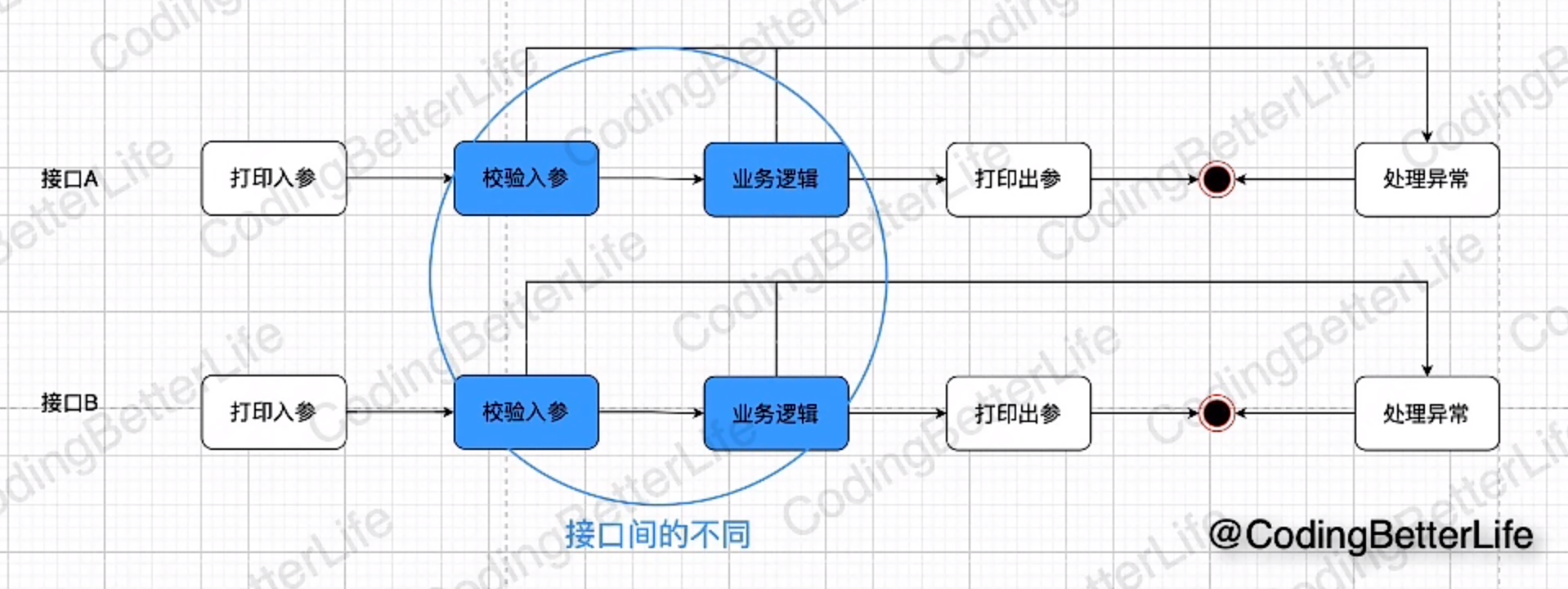
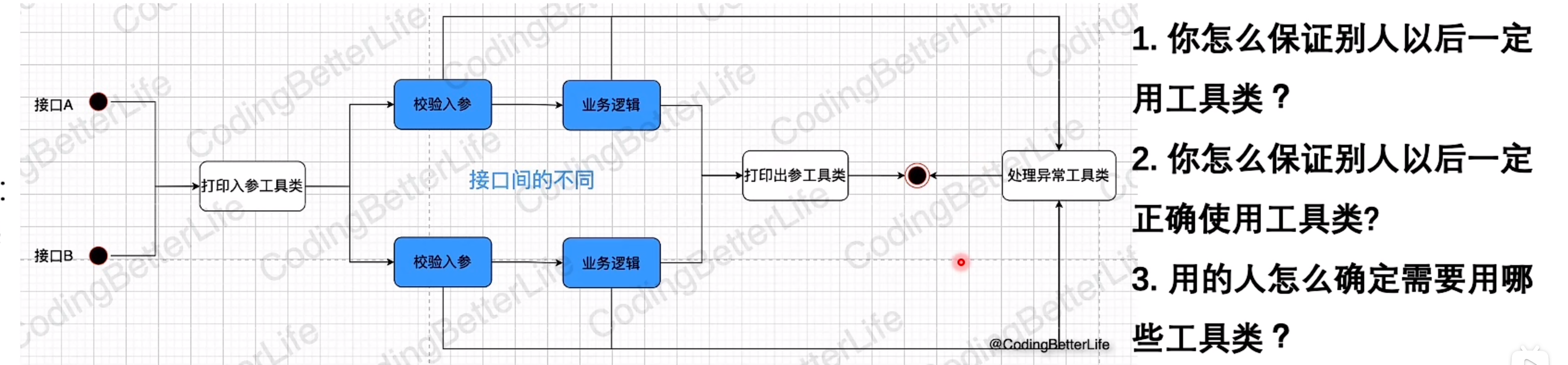
解决方案1:添加工具类
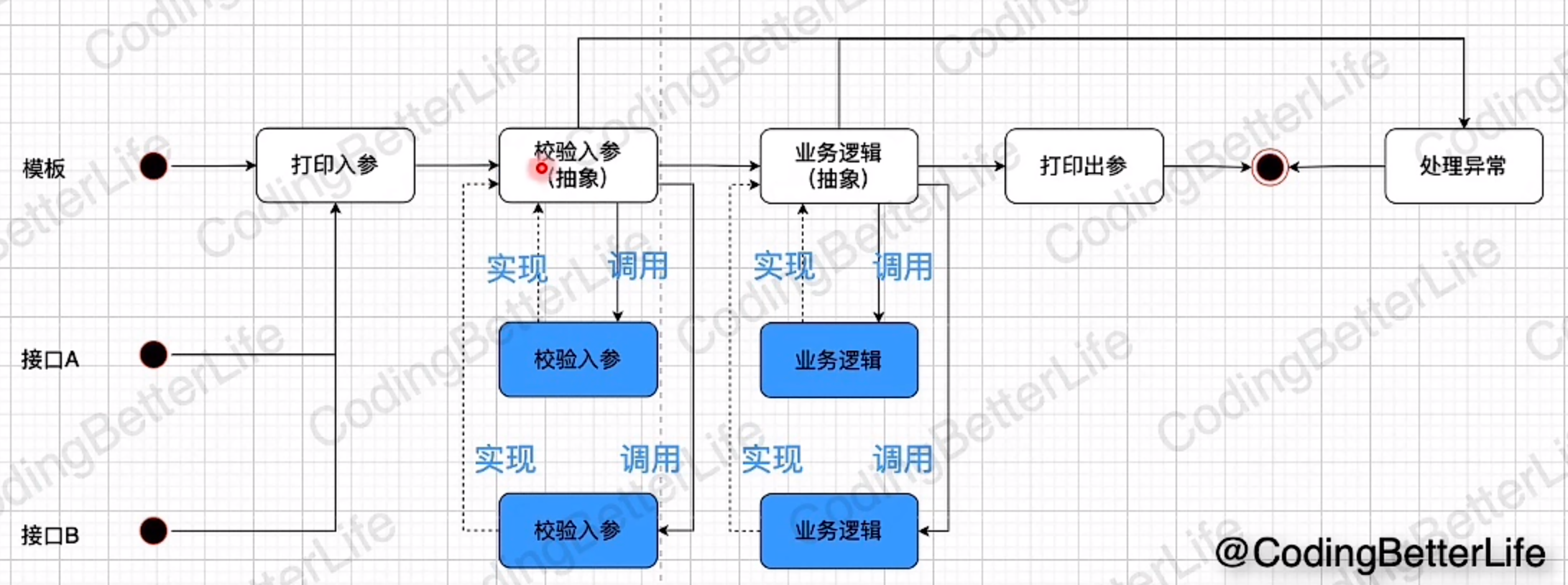
模板方法模式
统一逻辑,标准化流程
解决方案2:模板方法模式;保证必须要调用以及调用顺序;通用部分直接一起升级(log、error)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import com.google.common.base.Stopwatch;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
public abstract class ServiceTemplate<T, R> {
private final Logger logger = new LoggerImpl();
public R process(T request) {
logger.info("start invoke, request=" + request);
Stopwatch stopwatch = Stopwatch.createStarted();
try {
validParam(request);
R response = doProcess(request);
long timeCost = stopwatch.elapsed(TimeUnit.MILLISECONDS);
logger.info("end invoke, response=" + response + ", costTime=" + timeCost);
return response;
} catch (Exception e) {
logger.error("error invoke, exception:" + Arrays.toString(e.getStackTrace()));
return null;
}
}
protected abstract void validParam(T request);
protected abstract R doProcess(T request);
}
|
1
2
3
4
5
6
7
8
9
10
|
class LoggerImpl {
public void info(String msg) {
System.out.println("INFO: " + msg);
}
public void error(String msg) {
System.out.println("ERROR: " + msg);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public Integer get(Integer userId) {
return new ServiceTemplate<>() {
@Override
protected void validParam(Integer request) {
if (request == null) {
throw new IllegalArgumentException("Request cannot be null");
}
}
@Override
protected Integer doProcess(Integer request) {
return request * request;
}
}.process(userId);
|
再进一步:如果子需求再次变化,例如添加优惠券信息、消费记录查询限制时间、只有授权才返回余额
这样代码越来越长,并且子业务之间相互影响;耦合
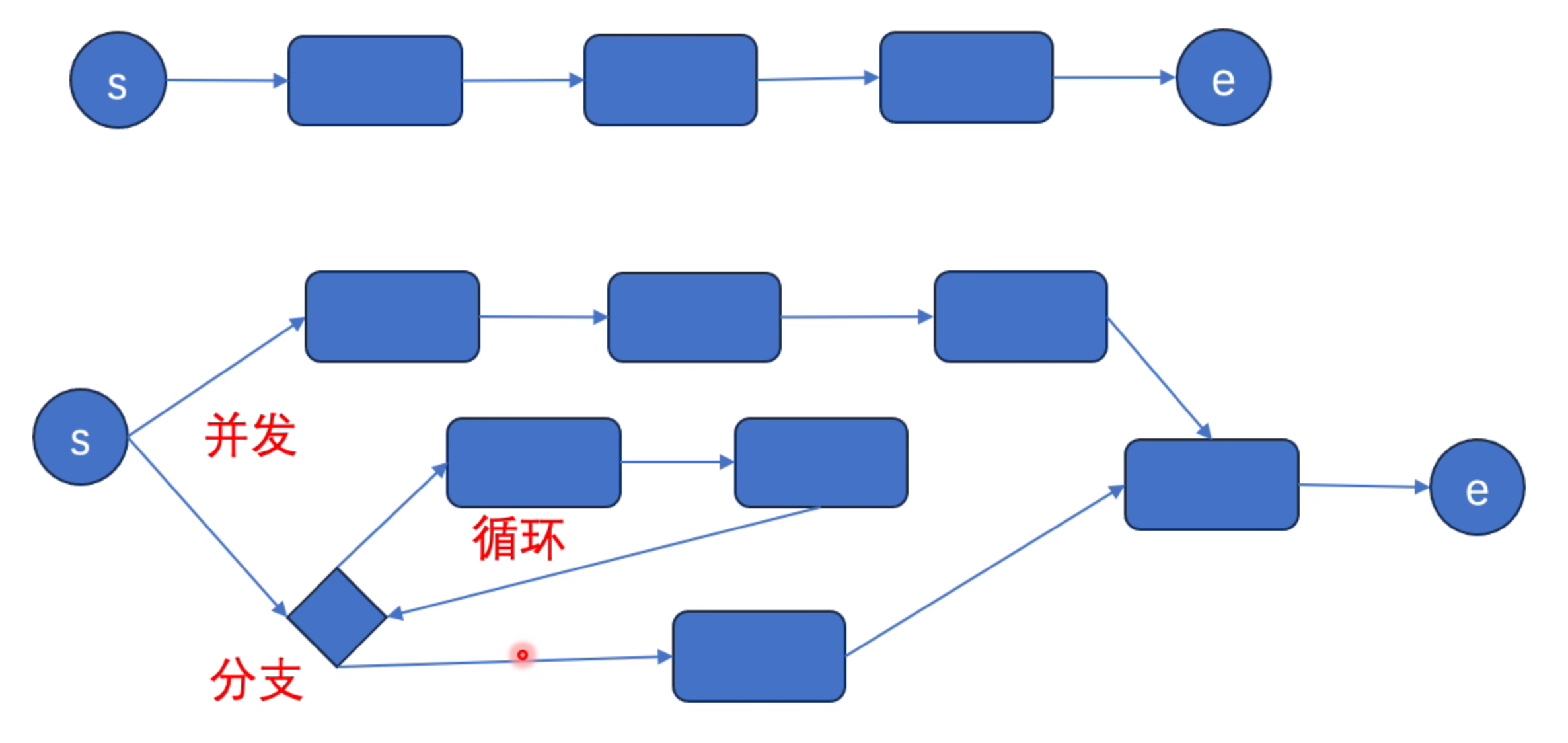
3.搭完架子串珠子
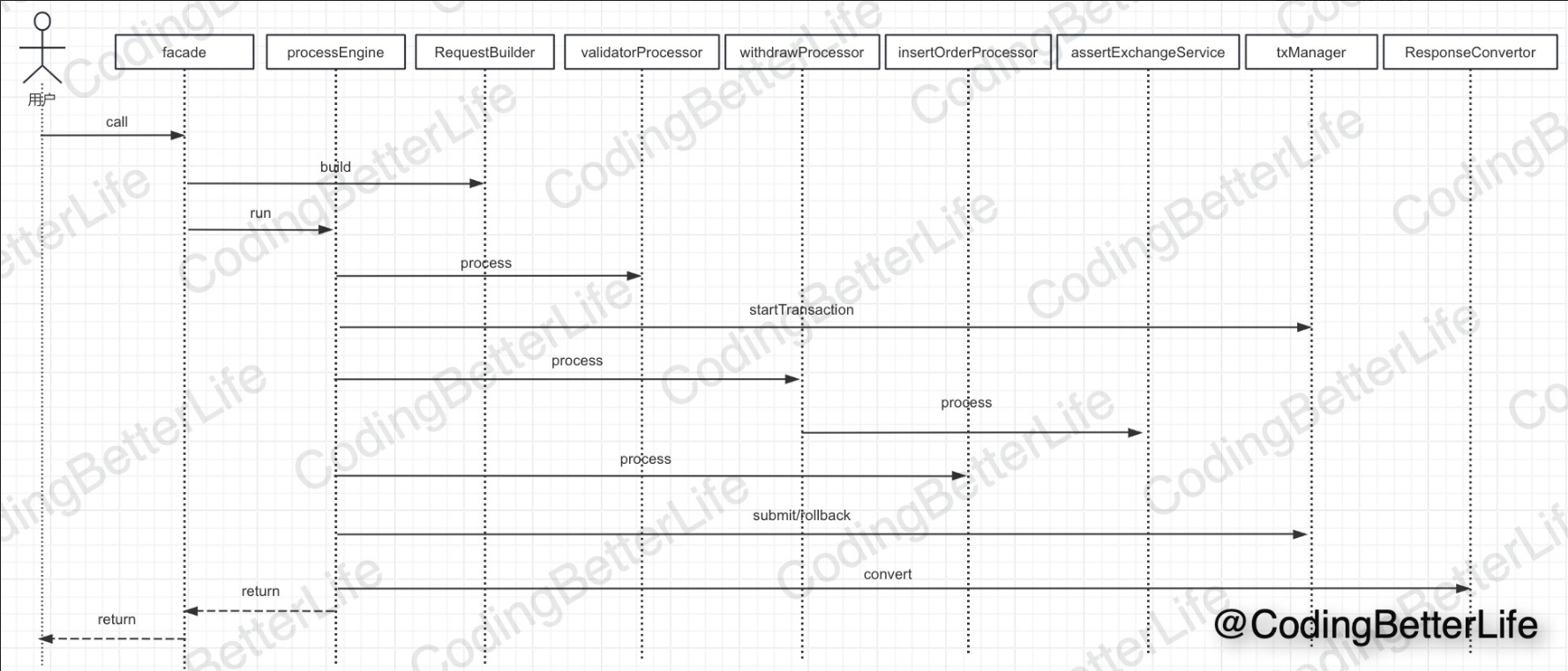
流程引擎
逻辑拆分、边界组装
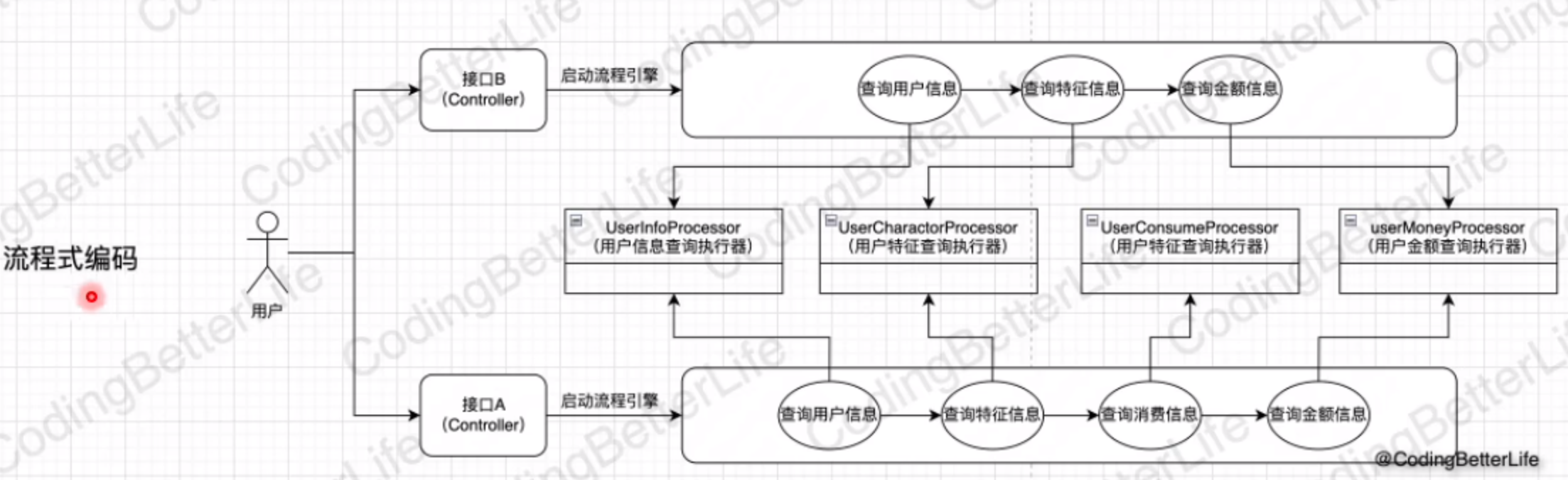
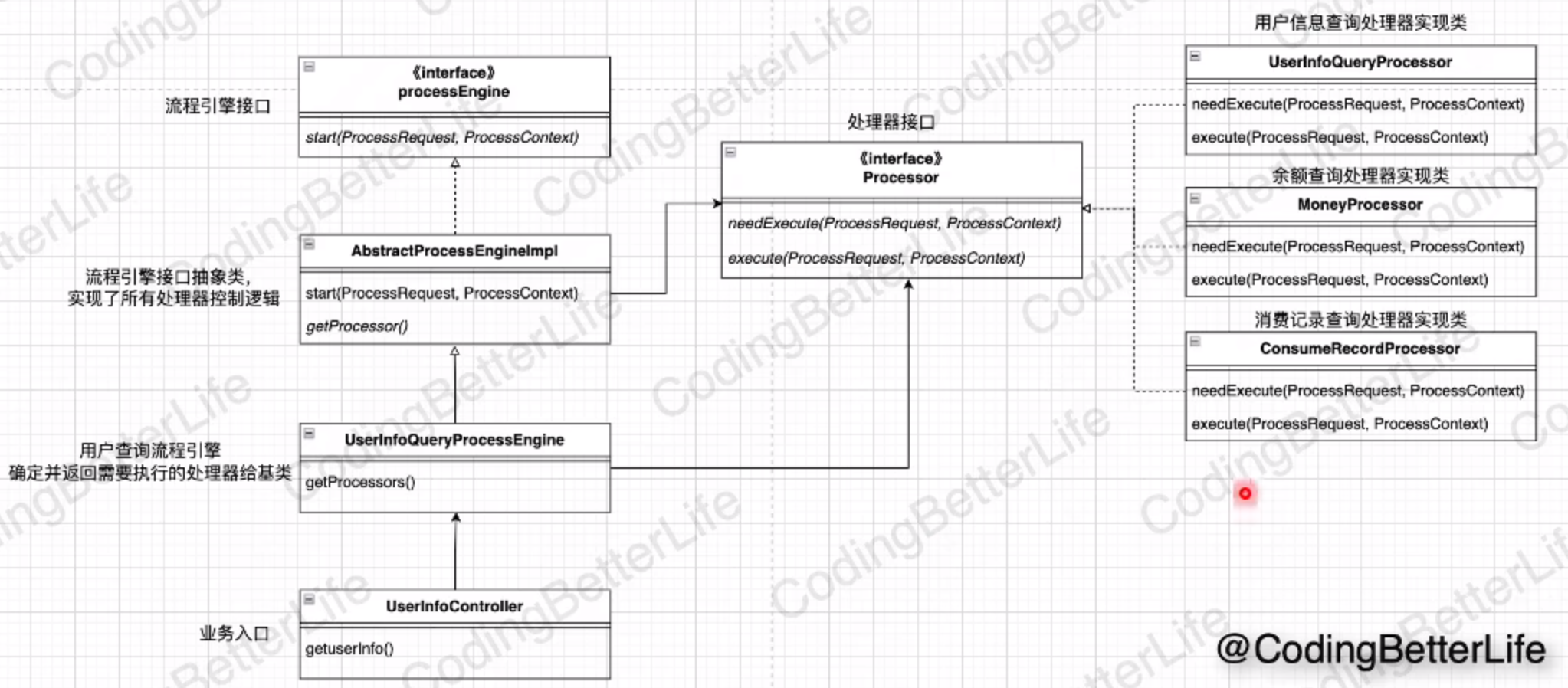
其实就是实习中遇到的模板引擎玩法
在活动中,就是处理器就是 获取活动信息 过活动人群 过任务人群 过风控 处理业务 (首次进入任务就是添加一次任务记录,然后发一次抽奖机会;抽奖就是消耗抽奖机会,然后执行抽奖流程)
CODE
造珠子(定义组件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public interface Processor {
boolean needExecute(ProcessRequest request, ProcessContext context);
void execute(ProcessRequest request, ProcessContext context);
}
@Component
public class UserInfoQueryProcessor implements Processor {
@Autowired
private UserBaseInfoRepository userBaseInfoRepository;
@Autowired
private UserSpecialInfoRepository userSpecialInfoRepository;
@Override
public boolean needExecute(ProcessRequest request, ProcessContext context) {
return true;
}
@Override
public void execute(ProcessRequest request, ProcessContext context) {
UserBaseInfoVO userBaseInfoVo = userBaseInfoRepository.getUserBaseInfo(request.getUserId());
UserSpecialInfoVO userSpecialInfoVo = userSpecialInfoRepository.getUserSpecialInfo(request.getUserId());
context.setUserBaseInfo(userBaseInfoVo);
context.setUserSpecialInfo(userSpecialInfoVo);
}
}
|
串珠子(编排组件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
public interface ProcessEngine {
void start(ProcessRequest request, ProcessContext context);
}
public abstract class AbstractProcessEngineImpl implements ProcessEngine {
@Autowired
private Logger logger;
@Autowired
private ApplicationContext applicationContext;
@Override
public void start(ProcessRequest request, ProcessContext context) {
logger.info("ProcessEngine start, request:" + request);
List<ProcessNameEnum> processors = getProcessors();
try {
for (ProcessNameEnum processorName : processors) {
Object bean = applicationContext.getBean(processorName.getName());
if (!(bean instanceof Processor)) {
logger.error("Processor: " + processorName + " not exist or type is incorrect");
continue;
}
logger.info("Processor: " + processorName + " start");
Processor processor = (Processor) bean;
if (!processor.needExecute(request, context)) {
logger.info("Processor: " + processorName + " skipped");
continue;
}
processor.execute(request, context);
logger.info("Processor: " + processorName + " end");
}
} catch (Exception e) {
logger.error("ProcessEngine interrupted, exception: " + Arrays.toString(e.getStackTrace()));
throw e;
}
logger.info("ProcessEngine end, context: " + context);
}
protected abstract List<ProcessNameEnum> getProcessors();
}
@Component
public class UserInfoQueryProcessEngine extends AbstractProcessEngineImpl {
private static final List<ProcessNameEnum> processorList = new ArrayList<>();
static {
processorList.add(ProcessNameEnum.USER_INFO_QUERY_PROCESSOR);
processorList.add(ProcessNameEnum.MONEY_PROCESSOR);
processorList.add(ProcessNameEnum.CONSUME_RECORD_PROCESSOR);
}
@Override
protected List<ProcessNameEnum> getProcessors() {
return processorList;
}
}
|
调用(启动流程)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public UserInfoDTO getUserInfo(@RequestParam("userId") String userId) {
return (new ServiceTemplate<String, UserInfoDTO>() {
@Override
public void validParam(String request) {
}
@Override
protected UserInfoDTO doProcess(String request) {
ProcessRequest processRequest = ProcessRequest.builder().userId(userId).build();
ProcessContext ctx = ProcessContext.builder().build();
userInfoQueryProcessEngine.start(processRequest, ctx);
return UserInfoDTO.builder()
.totalMoney(ctx.getTotalMoney())
.maxAmount(ctx.getMaxAmount())
.build();
}
}).process(userId);
}
|
复杂流程编排
amunda, JBPM, 或Activiti 轻量级框架:LiteFlow
0.JSON
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {
"initialProcessor": "UserInfoQueryProcessor",
"processMap": {
"UserInfoQueryProcessor": {
"success": "MoneyProcessor",
"failed": "ErrorHandlingProcessor"
},
"MoneyProcessor": {
"success": "ConsumeRecordProcessor",
"failed": "ErrorHandlingProcessor"
},
"ConsumeRecordProcessor": {
"success": null,
"failed": "ErrorHandlingProcessor"
}
}
}
|
1.返回string,决定着next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public interface Processor {
boolean needExecute(ProcessRequest request, ProcessContext context);
String execute(ProcessRequest request, ProcessContext context) throws Exception;
}
@Component
public class UserInfoQueryProcessor implements Processor {
@Autowired
private UserBaseInfoRepository userBaseInfoRepository;
@Autowired
private UserSpecialInfoRepository userSpecialInfoRepository;
@Override
public boolean needExecute(ProcessRequest request, ProcessContext context) {
return true;
}
@Override
public void execute(ProcessRequest request, ProcessContext context) {
UserBaseInfoVO userBaseInfoVo = userBaseInfoRepository.getUserBaseInfo(request.getUserId());
UserSpecialInfoVO userSpecialInfoVo = userSpecialInfoRepository.getUserSpecialInfo(request.getUserId());
if (userSpecialInfoVo == null){
return "failed"
}
context.setUserBaseInfo(userBaseInfoVo);
context.setUserSpecialInfo(userSpecialInfoVo);
return "success"
}
}
|
2.编排
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| @Component
public class ConfigurableProcessEngineImpl implements ProcessEngine {
@Autowired
private Logger logger;
@Autowired
private ApplicationContext applicationContext;
private Map<String, Map<String, String>> processMap;
private String initialProcessorName;
public ConfigurableProcessEngineImpl(String jsonFilePath) {
init(jsonFilePath);
}
private void init(String jsonFilePath) {
String jsonContent = new String(Files.readAllBytes(Paths.get(jsonFilePath)));
JSONObject jsonConfig = JSON.parseObject(jsonContent);
this.initialProcessorName = jsonConfig.getString("initialProcessor");
this.processMap = parseProcessMap(jsonConfig.getJSONObject("processMap"));
}
@Override
public void start(ProcessRequest request, ProcessContext context) {
String currentProcessorName = this.initialProcessorName;
Processor currentProcessor;
while (currentProcessorName != null) {
currentProcessor = (Processor) applicationContext.getBean(currentProcessorName);
String result;
try {
if (currentProcessor.needExecute(request, context)) {
result = currentProcessor.execute(request, context);
} else {
logger.info("Processor: " + currentProcessorName + " skipped");
result = "Skipped";
}
} catch (Exception e) {
result = "Failed";
logger.error("Processor: " + currentProcessorName + " failed, exception: " + Arrays.toString(e.getStackTrace()));
}
currentProcessorName = determineNextProcessor(currentProcessorName, result);
}
logger.info("ProcessEngine end, context: " + context);
}
private String determineNextProcessor(String currentProcessorName, String result) {
Map<String, String> decisionMap = processMap.get(currentProcessorName);
if (decisionMap == null) {
return null;
}
return decisionMap.get(result);
}
private Map<String, Map<String, String>> parseProcessMap(JsonObject processMapJson) {
return JSONObject.parseObject(processMapJson.toJSONString(),
new TypeReference<Map<String, Map<String, String>>>() {});
}
}
|
3.调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| protected UserInfoDTO doProcess(String request) {
ConfigurableProcessEngineImpl processEngine = new ConfigurableProcessEngineImpl("/path/to/your/process-flow.json");
processEngine.start(request, context);
ProcessRequest processRequest = ProcessRequest.builder().userId(userId).build();
ProcessContext ctx = ProcessContext.builder().build();
processEngine.start(processRequest, ctx);
return UserInfoDTO.builder()
.totalMoney(ctx.getTotalMoney())
.maxAmount(ctx.getMaxAmount())
.build();
}
|
责任链
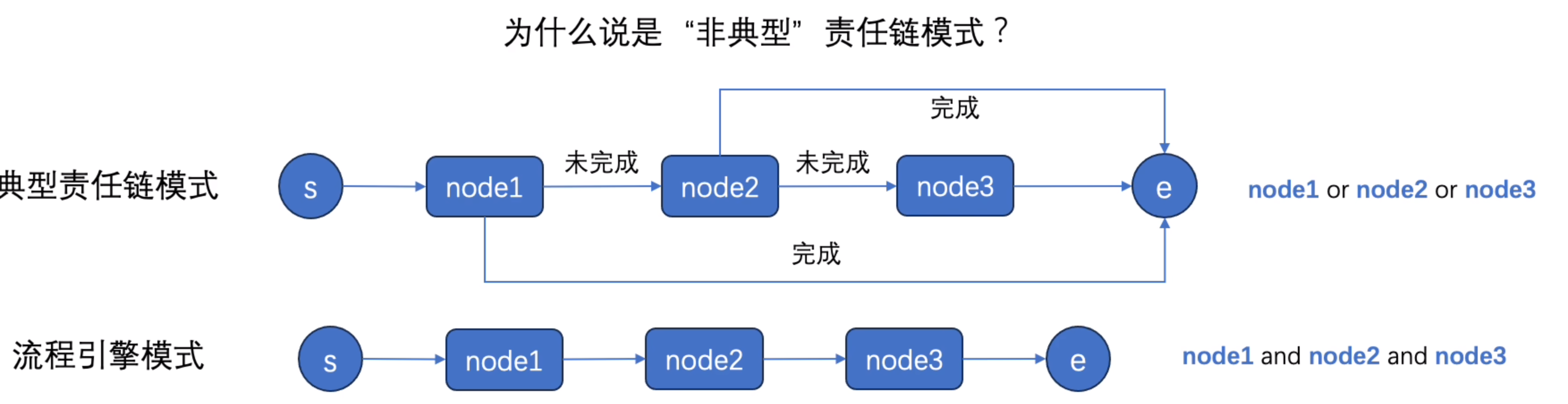
责任链:沿着这条链传递请求,直到有一个对象处理它为止,具体由哪个对象处理则在运行时动态决定的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| abstract class Handler {
protected Handler successor;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public abstract void handleRequest(double amount);
}
class NoDiscountHandler extends Handler {
public void handleRequest(double amount) {
System.out.println("No discount applied.");
}
}
class LowDiscountHandler extends Handler {
public void handleRequest(double amount) {
if (amount < 1000) {
System.out.println("Low discount applied. Amount: " + amount);
} else if (successor != null) {
successor.handleRequest(amount);
}
}
}
class HighDiscountHandler extends Handler {
public void handleRequest(double amount) {
if (amount >= 1000) {
System.out.println("High discount applied. Amount: " + amount);
} else if (successor != null) {
successor.handleRequest(amount);
}
}
}
class HandlerChain {
private Handler head;
private Handler tail;
public HandlerChain add(Handler handler) {
if (head == null) {
head = handler;
tail = handler;
} else {
tail.setSuccessor(handler);
tail = handler;
}
return this;
}
public void handleRequest(double amount) {
if (head != null) {
head.handleRequest(amount);
}
}
}
public class ChainDemo {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.add(new LowDiscountHandler())
.add(new HighDiscountHandler())
.add(new NoDiscountHandler());
chain.handleRequest(500);
chain.handleRequest(1500);
}
}
|
4.系统是个三明治
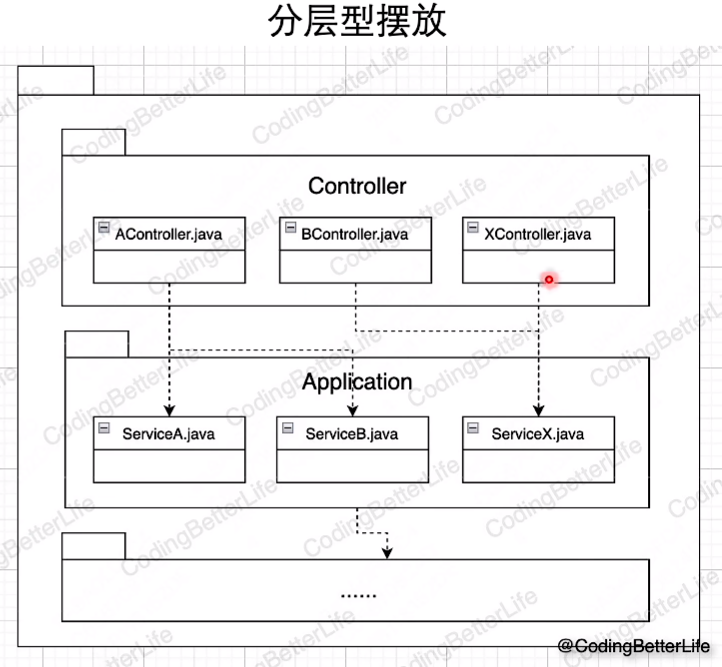
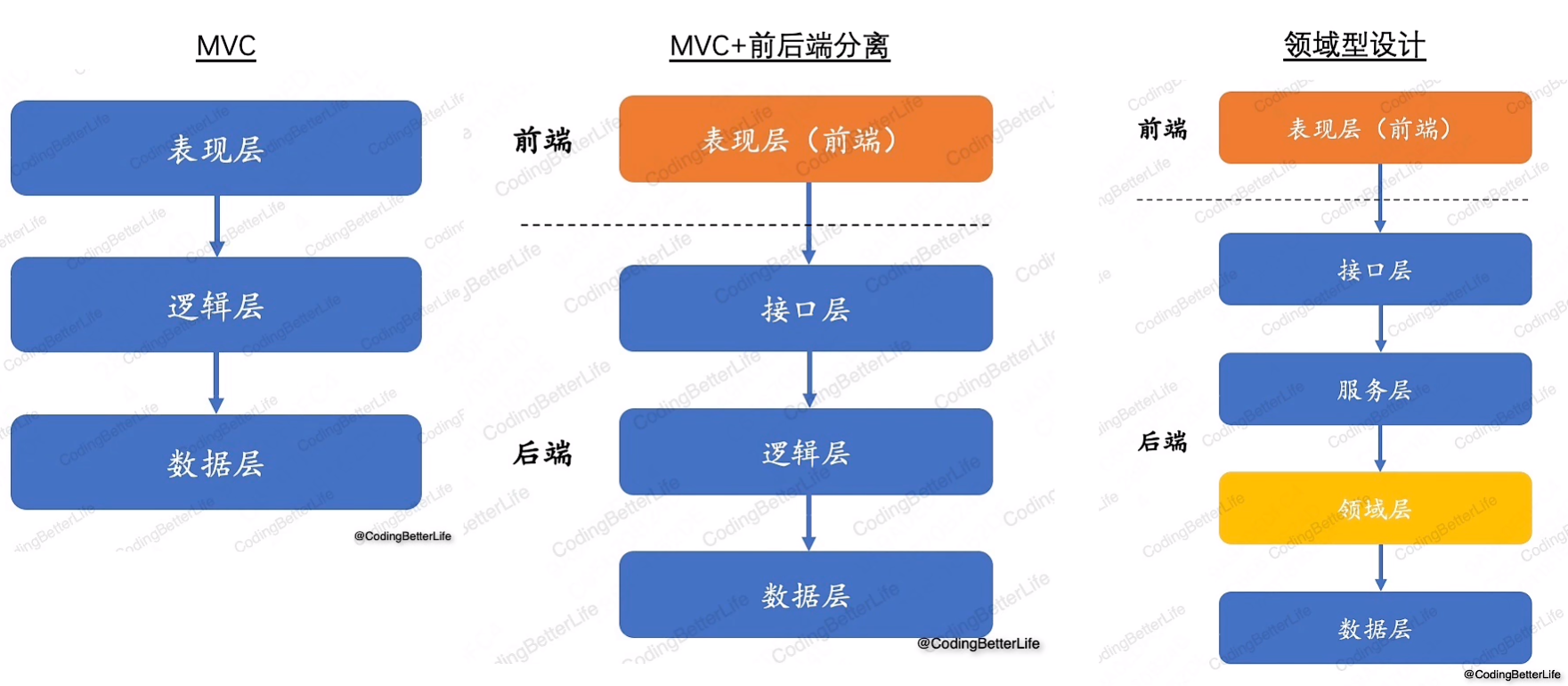
- [接口层] :对出入参仅做格式上的校验,不能涉及“例如用户是否在黑名单中”这样的校验。
- [服务层] :负责编排流程、处理rpc请求、控制同异步。不能涉及领域概念。
- [领域层] :针对领域规则来实现具体的能力。
- [数据层] :仅对数据做CRUD,不能涉及对数据的额外加工。
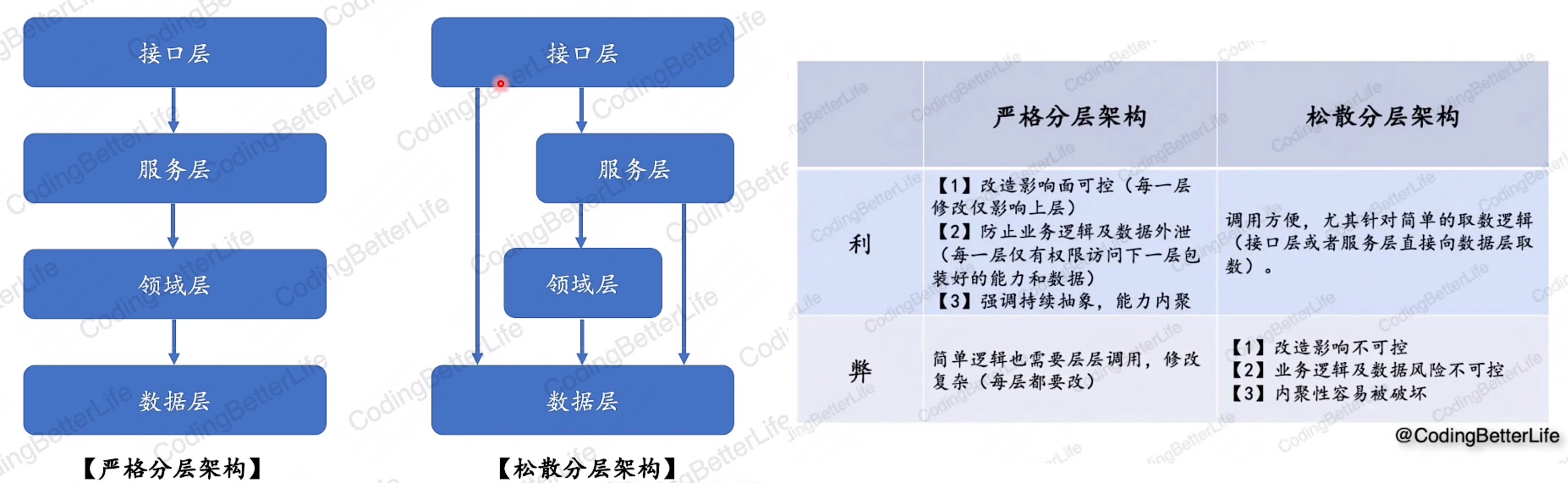
5.DDD
复杂度提升
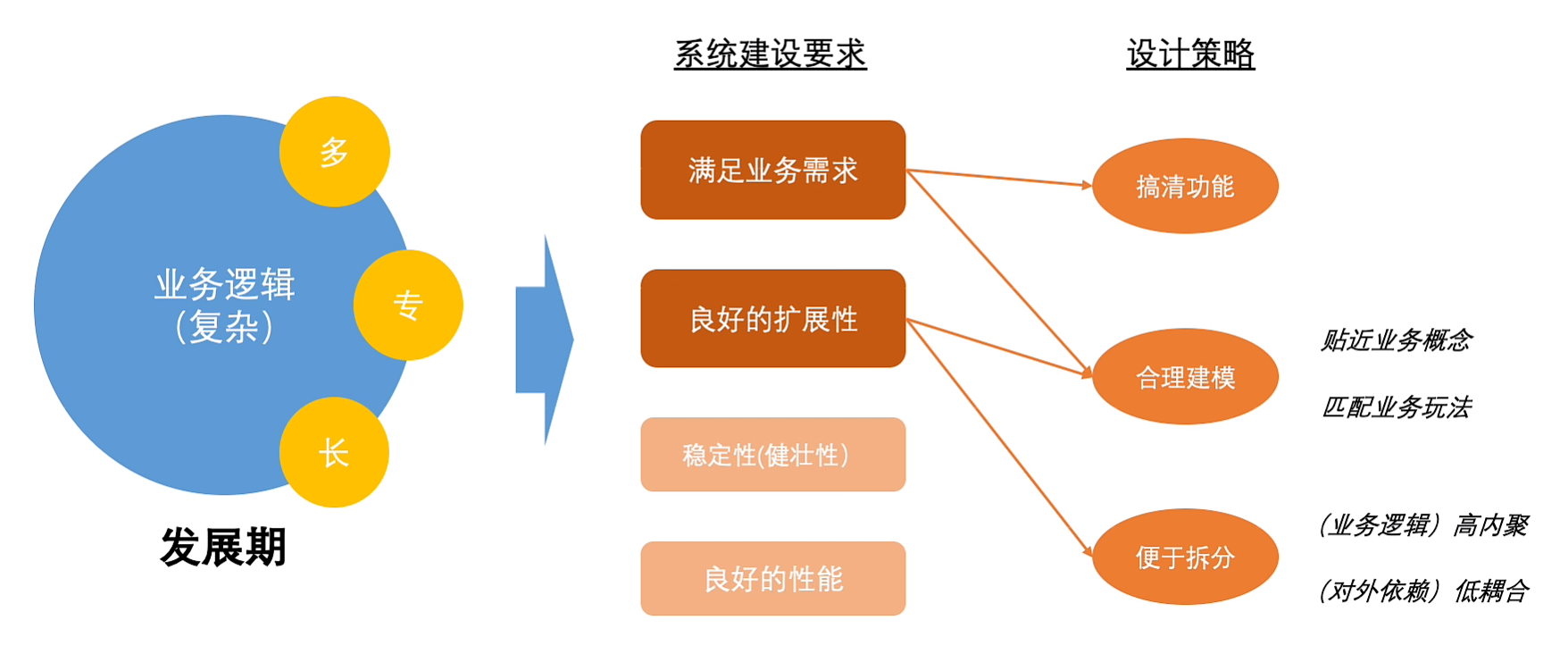
设计策略:
case:卖家可以在网上挂商品售卖,买家可以选择商品并购买,购买后卖家会发快递,买家收到货后确认收货,网站把款项结算给卖家。
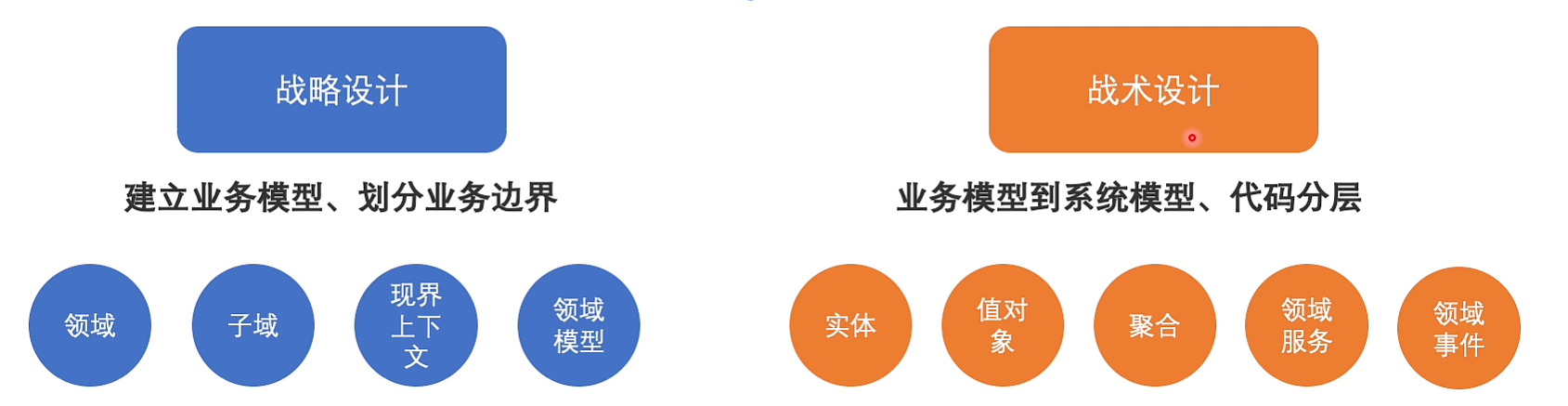
战略设计
解释业务,建立业务模型,划分业务边界
事件风暴
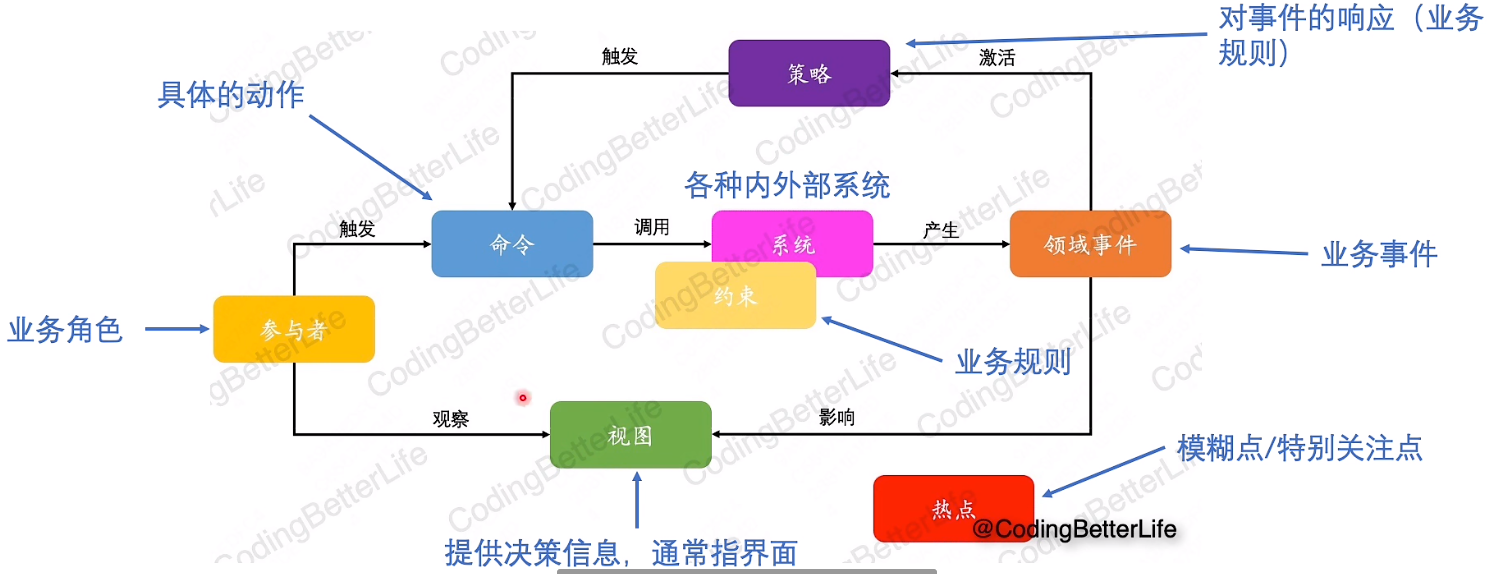
事件:行为的结果(业务的重点),再通过事件反推整个流程
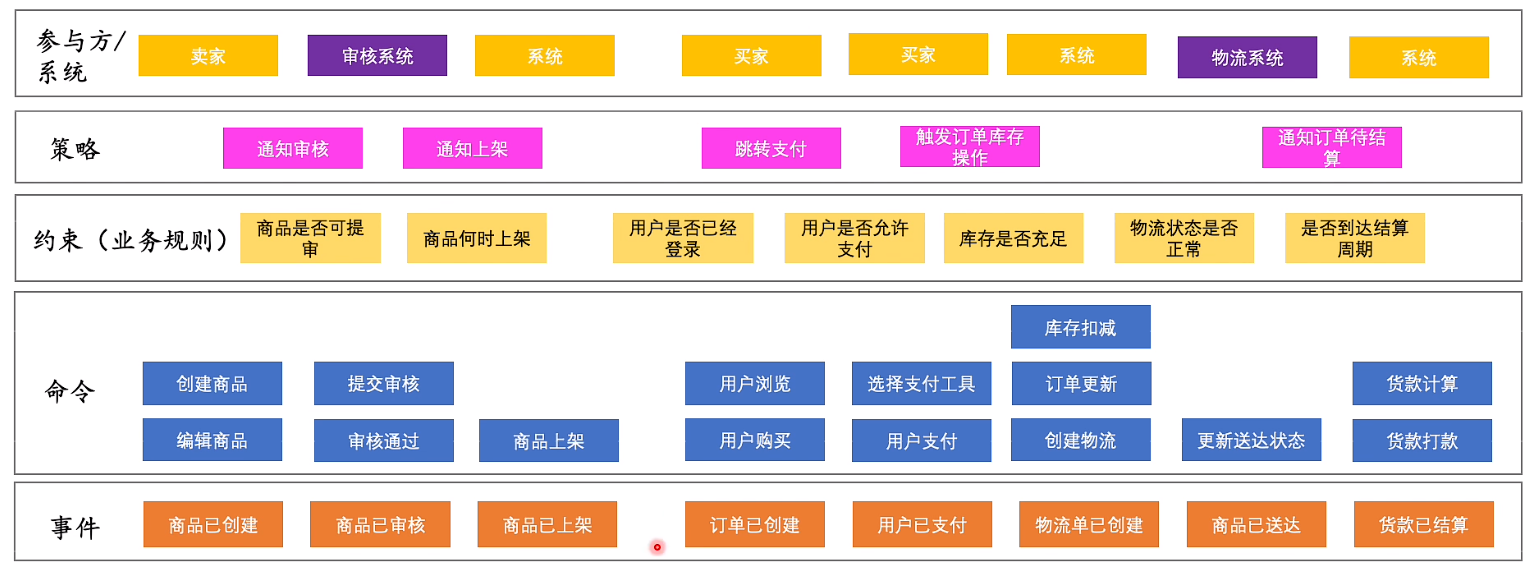
领域建模
分析领域模型
找出事件风暴中的名词
连接名词
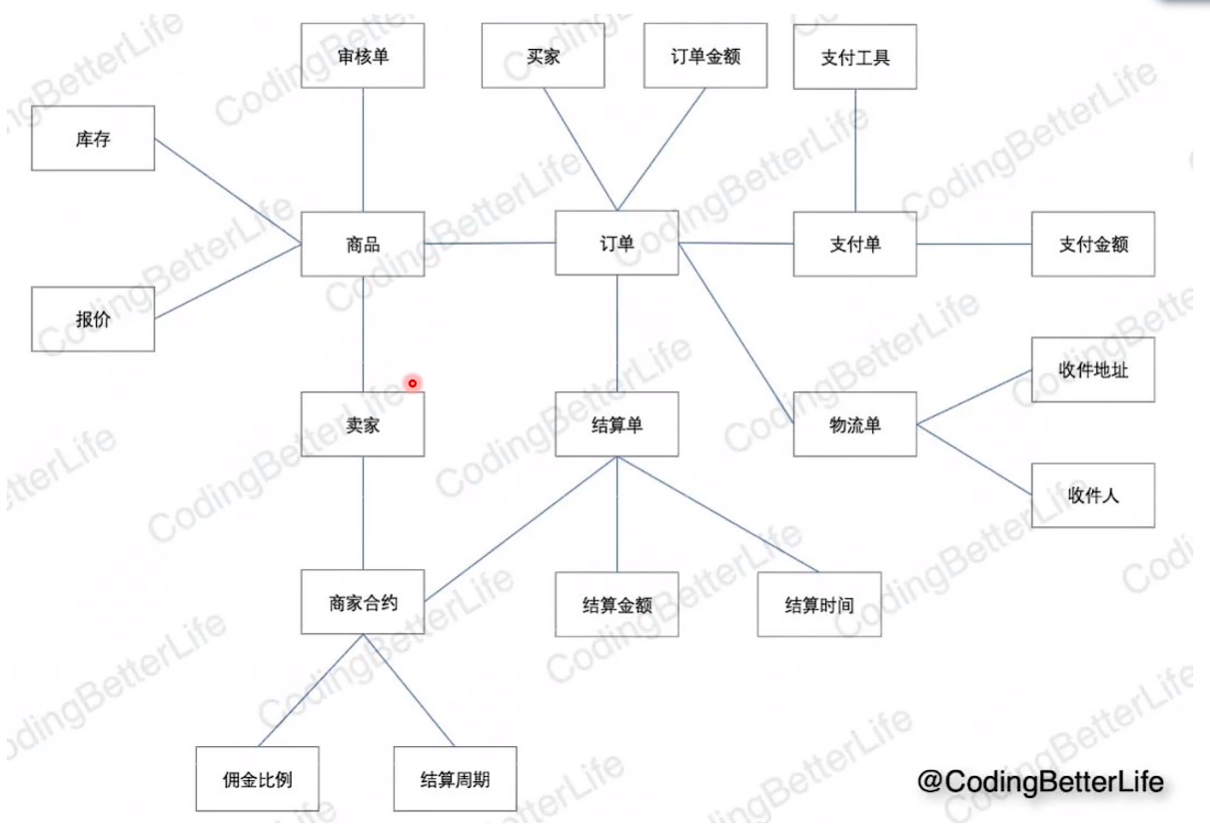
找聚合:
直接关系最多的节点
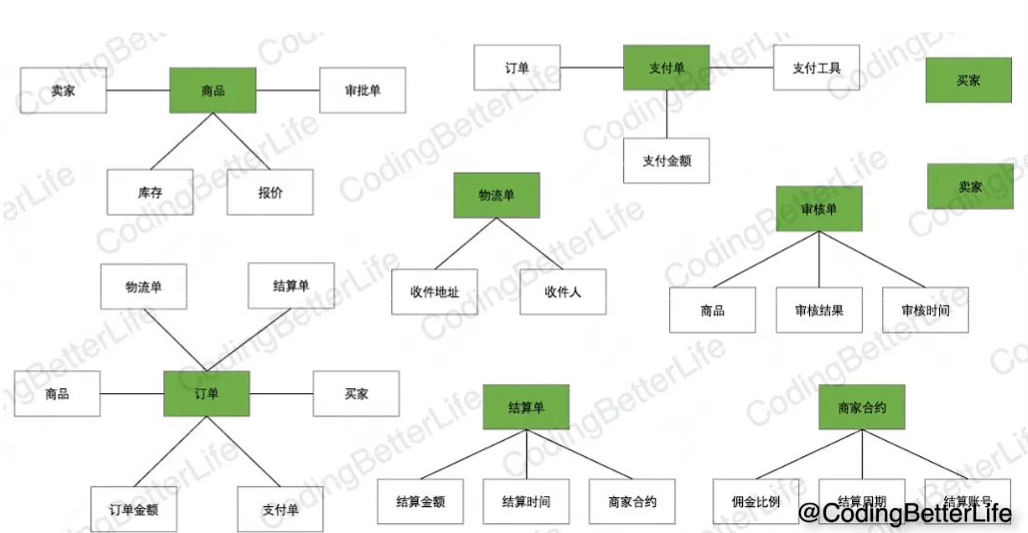
划分(限界上下文)
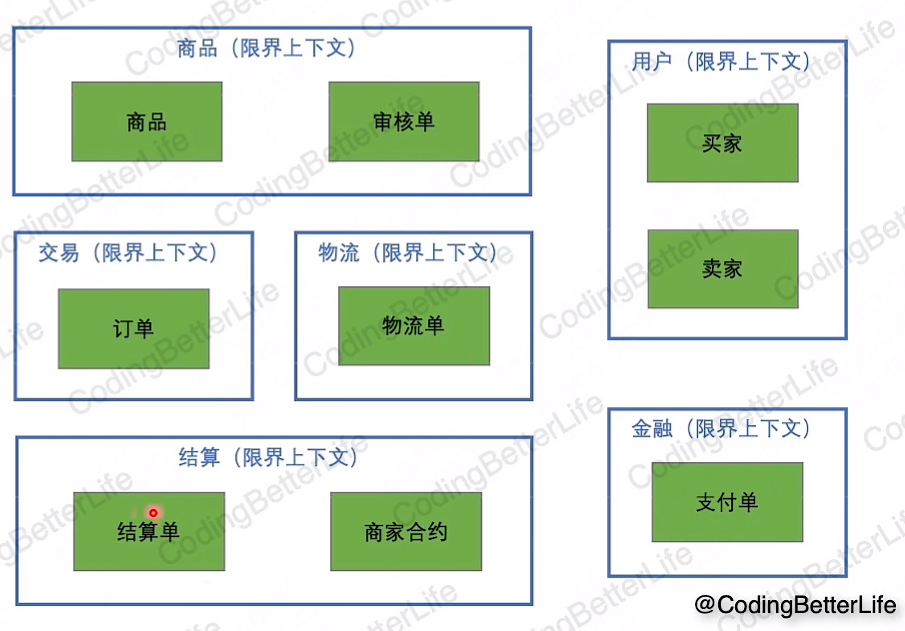
1.整理出了重要的业务概念和规则.
2.所有角色都对概念对齐了认知
3.识别了重要的领域模型,继而指导了系统模型
4.做了系统划分
丛业务嘴里的模糊描述 ->清晰的业务概念(多方认知)具体系统建设的内容
战术设计
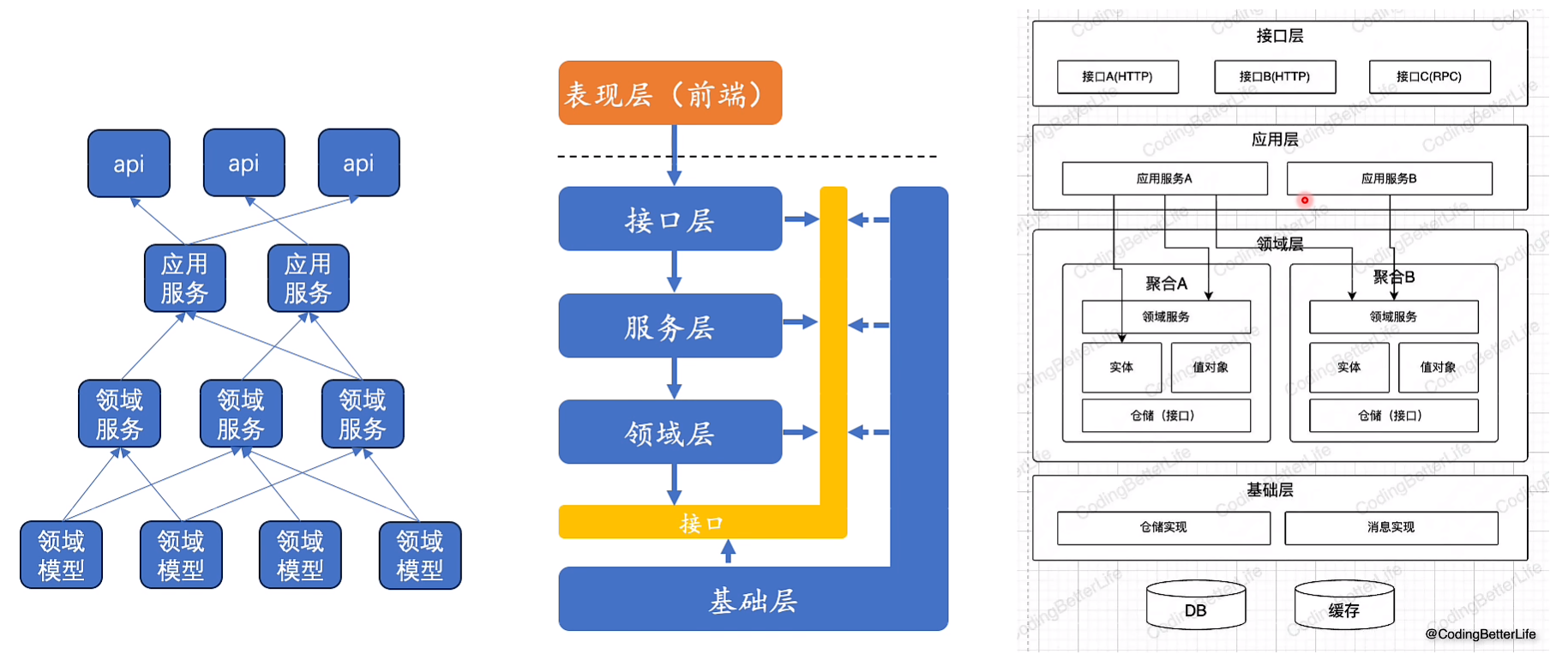
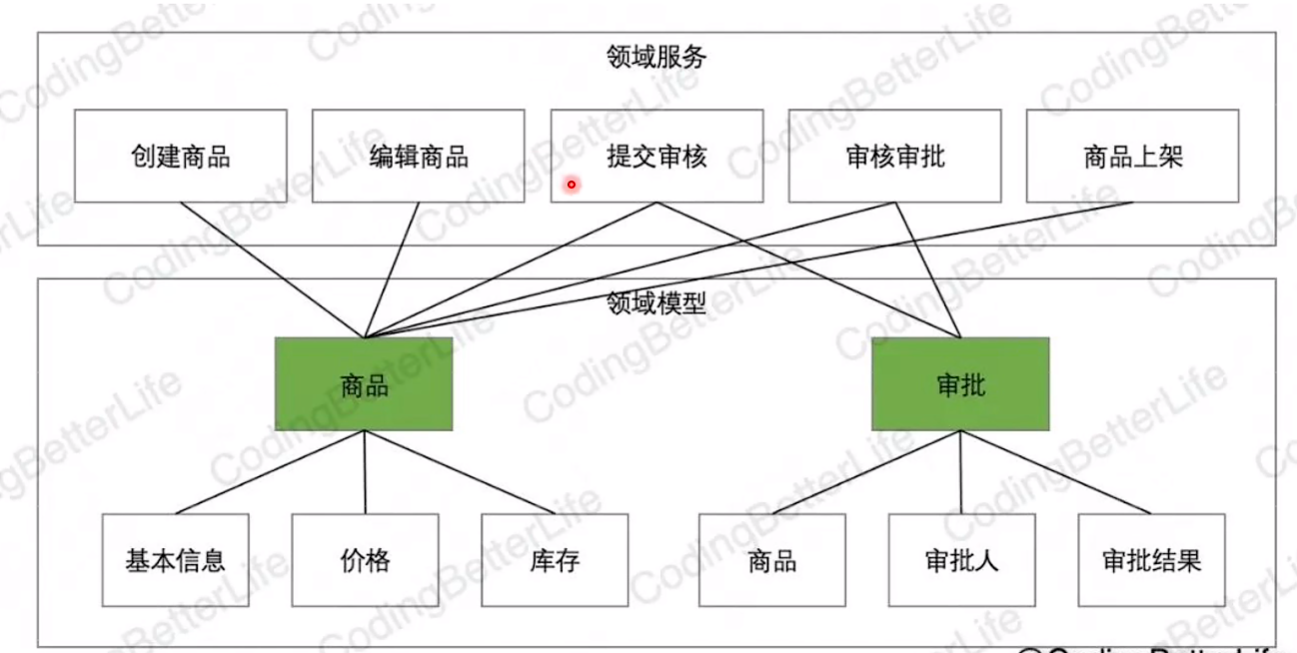
领域模型:提供了基本的能力,包含业务规则(如类文件对外暴露的方法)
领域服务:就是命令(动作),由多个领域模型聚合
应用层:编排领域服务;同时需要处理消息(例如下单后的邮件通知通过事件驱动实现)
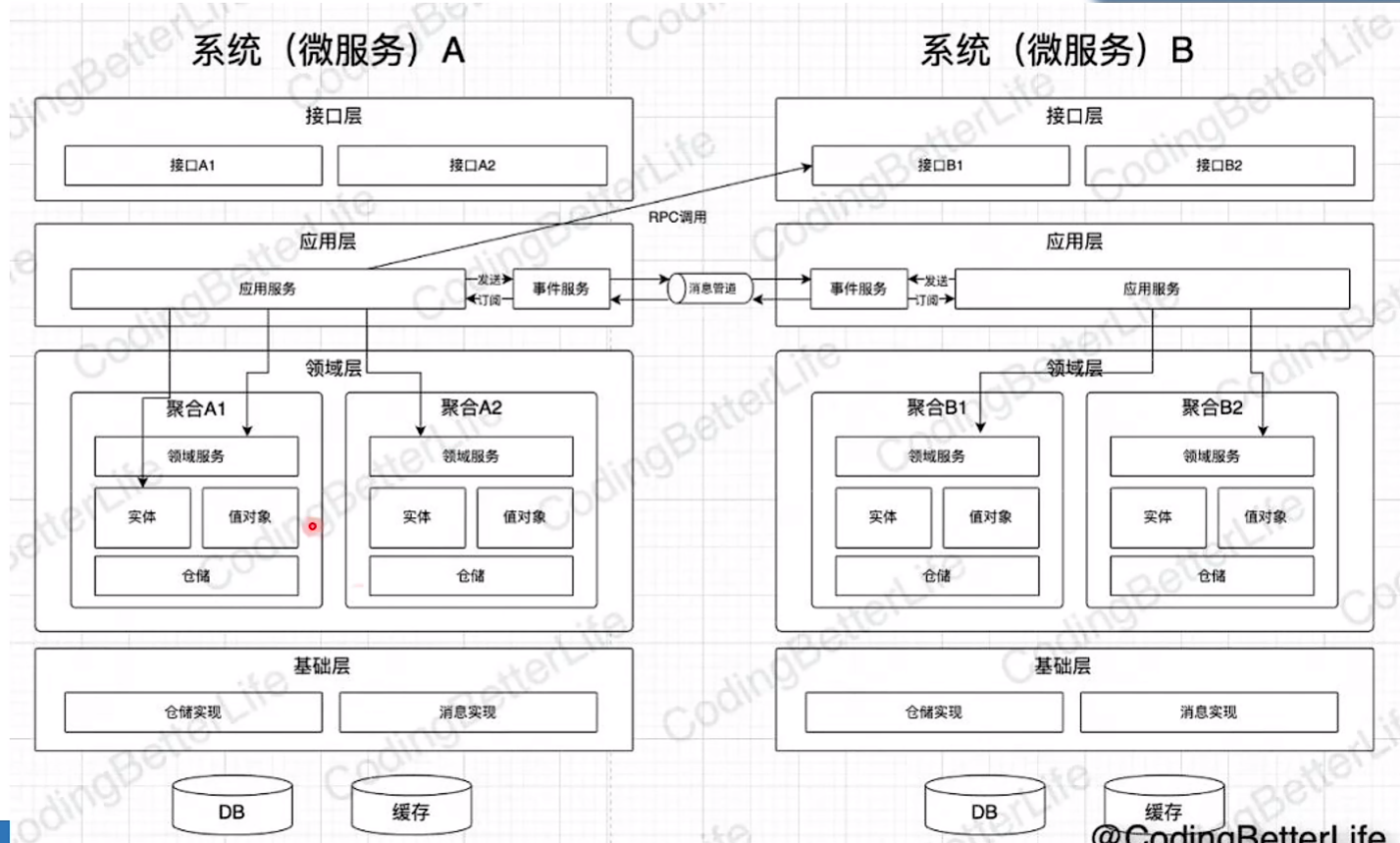
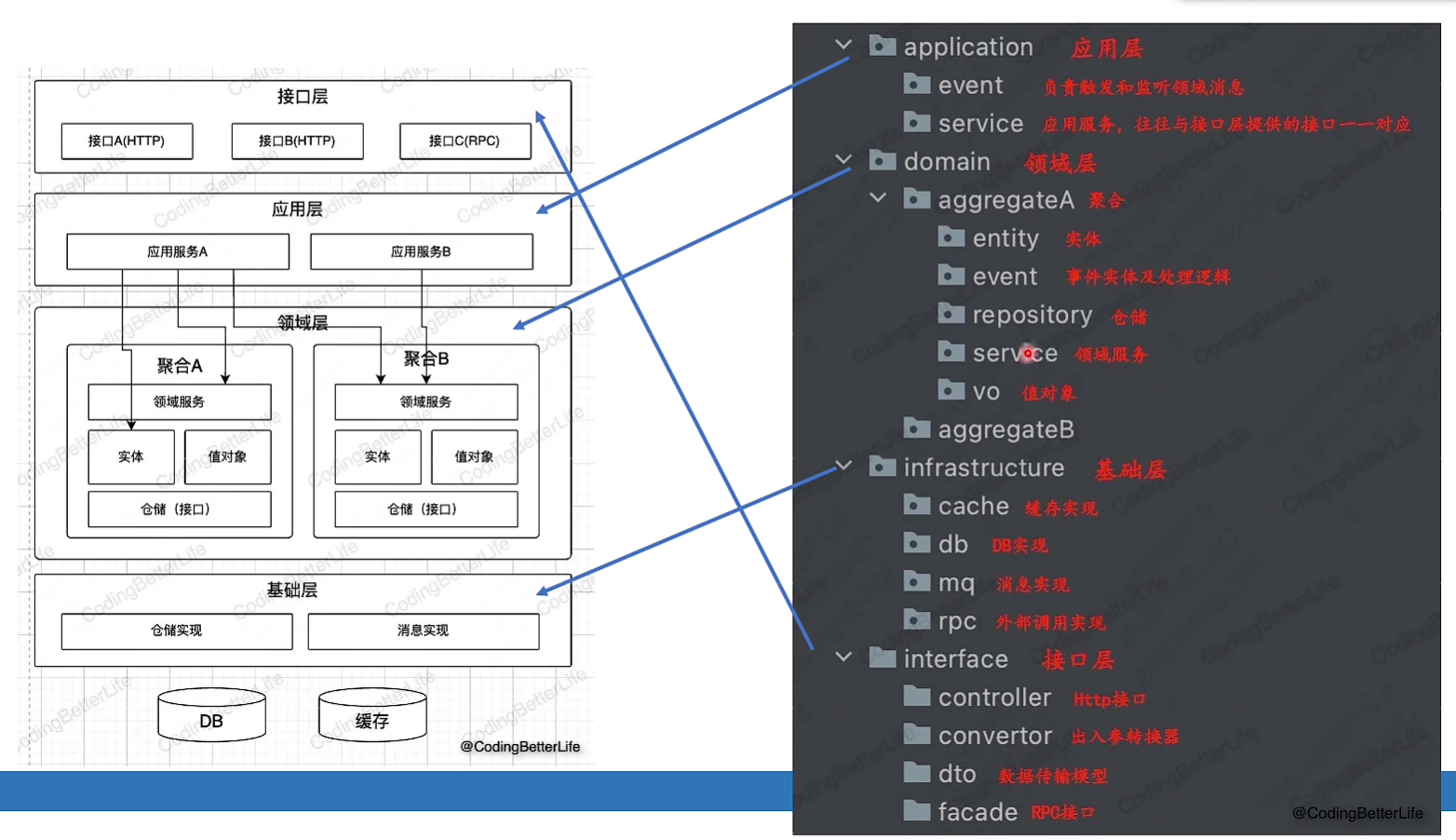
目录结构:
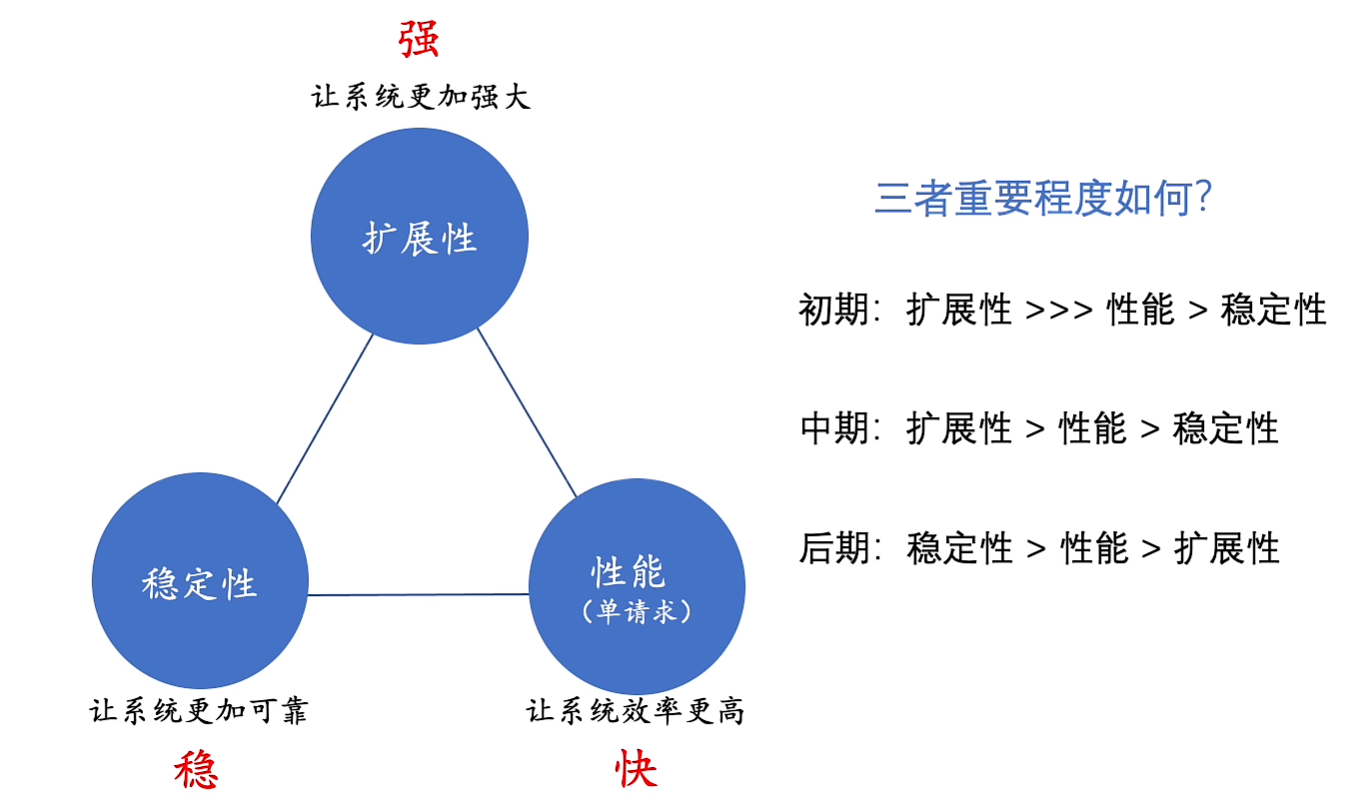
6.0铁三角
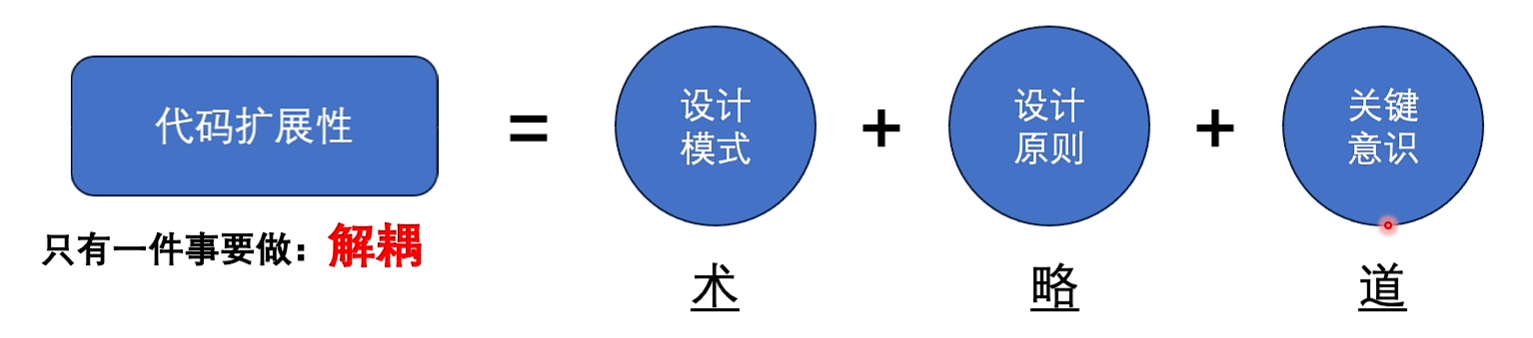
6.还得是设计模式(扩展-功能扩展)
看不懂 改不动 风险高
会写代码的人很多,写好的代码的人少
case
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public boolean transfer(String payer, String payee, String money) {
Log.info("transfer start, payer={}, payee={}, money={}", payer, payee, money);
if (!isValidUser(payer) || !isValidUser(payee) || !isValidMoney(money)) {
return false;
}
TransferResult transferResult = transferService.transfer(payer, payee, money);
if (!transferResult.isSuccess()) {
return false;
}
UserInfo userInfo = userInfoService.getUserInfo(payee);
if (userInfo.getNotifyType() == NotifyTypeEnum.SMS) {
smsClient.sendSms(payee, NOTIFY_CONTENT);
} else if (userInfo.getNotifyType() == NotifyTypeEnum.MAIL) {
mailClient.sendMail(payee, NOTIFY_CONTENT);
}
billService.sendBill(transferResult);
monitorService.sendRecord(transferResult);
quotaService.recordQuota(transferResult);
Log.info("transfer success");
return true;
}
|
入参出参不具备扩展性,可以考虑使用对象参数
参数的校验可以使用责任链优化,所有校验方法都添加到一个list中 context.getBeansOfTypeParamValidator.class)

通知方式,使用多态替换条件表达式 策略模式或适配器;和上面最大区别在于只执行一个而不是都执行 所以要一个一个添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Service
public class NotifyServiceManager implements InitializingBean {
@Autowired
private SmsNotifyService smsNotifyService;
@Autowired
private MailNotifyService mailNotifyService;
private final Map<NotifyTypeEnum, NotifyService> notifyServiceMap = new HashMap<>();
@Override
public void afterPropertiesSet() throws Exception {
notifyServiceMap.put(NotifyTypeEnum.SMS, smsNotifyService);
notifyServiceMap.put(NotifyTypeEnum.MAIL, mailNotifyService);
}
public void notify(NotifyTypeEnum notifyTypeEnum, String userId, String content) {
NotifyService notifyService = notifyServiceMap.get(notifyTypeEnum);
if (notifyService == null) {
throw new RuntimeException("Notify service not exist for type: " + notifyTypeEnum);
}
notifyService.notifyMessage(userId, content);
}
}
|
最后非主链路的统计、打点,使用观察者模式实现;并结合线程池加速及错误隔离;和校验器区别在于这是非主链路
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public interface TransferObserver {
void update(TransferResult transferResult);
}
public class BillServiceObserver implements TransferObserver {
@Override
public void update(TransferResult transferResult) {
billService.sendBill(transferResult);
}
}
public class MonitorServiceObserver implements TransferObserver {
@Override
public void update(TransferResult transferResult) {
monitorService.sendRecord(transferResult);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Component
public class TransferSubject implements InitializingBean {
@Autowired
private ApplicationContext applicationContext;
private final List<TransferObserver> transferObserverList = new ArrayList<>();
private final ExecutorService executorService = Executors.newFixedThreadPool(10);
@Override
public void afterPropertiesSet() throws Exception {
Map<String, TransferObserver> transferObserverMap = applicationContext.getBeansOfType(TransferObserver.class);
transferObserverMap.values().forEach(this::addObserver);
}
public void notifyObservers(TransferResult transferResult) {
transferObserverList.forEach(transferObserver -> {
executorService.execute(() -> transferObserver.update(transferResult));
});
}
public void addObserver(TransferObserver transferObserver) {
transferObserverList.add(transferObserver);
}
}
|
至此新增参数校验、通知类型、后处理等,transfer方法不用修改
设计原则
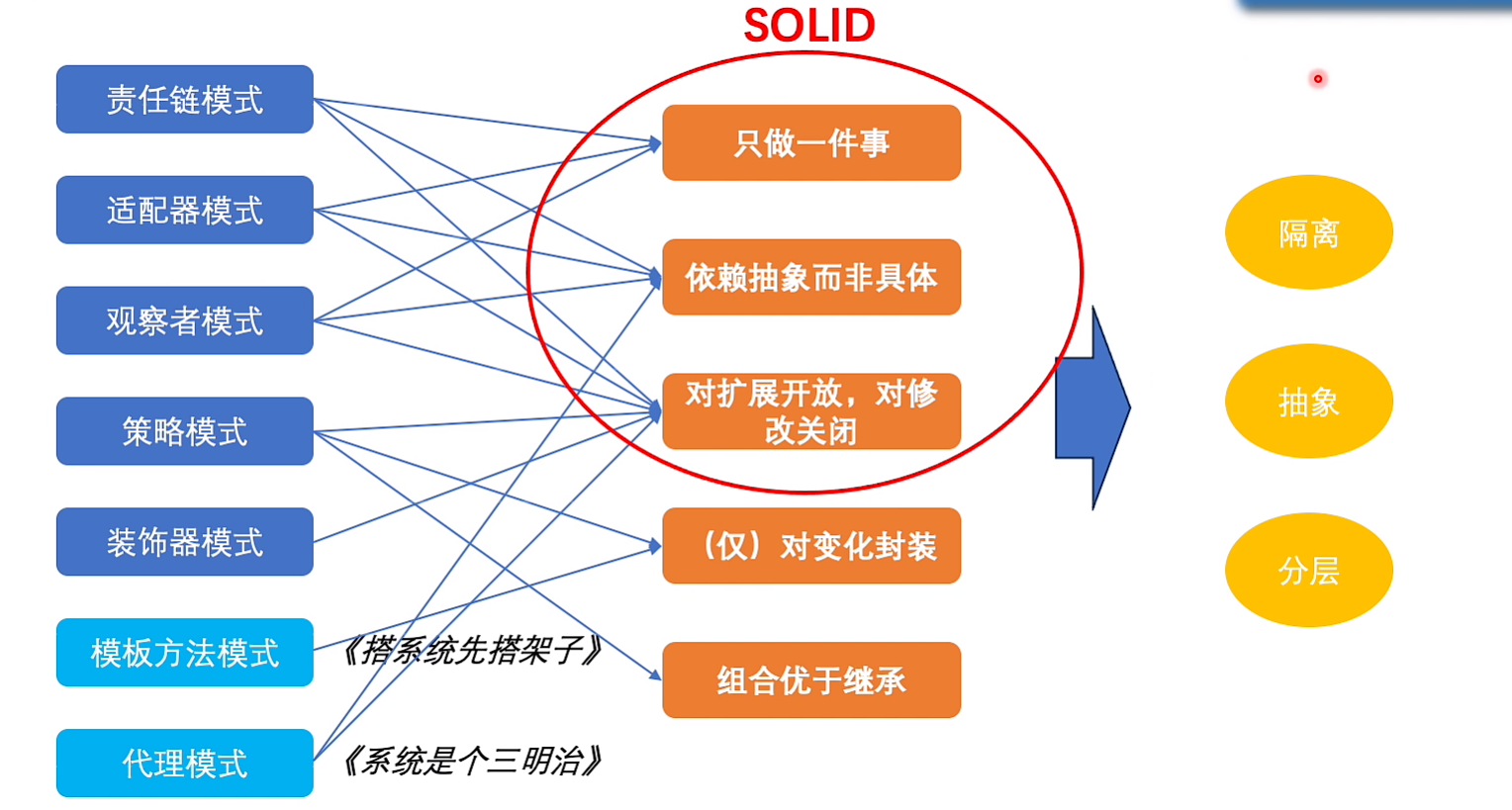
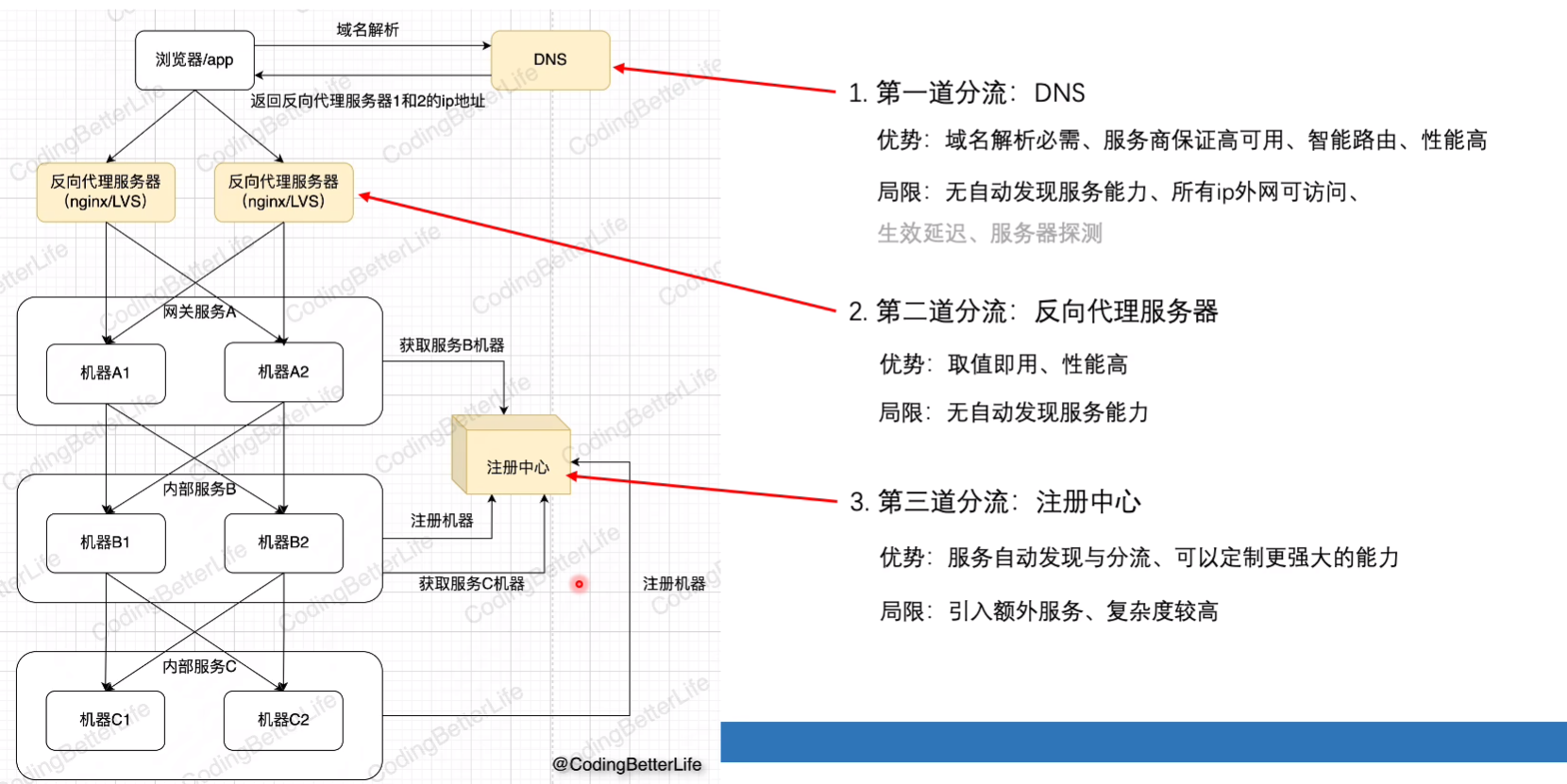
7.没有扛不住的流量(扩展-流量扩展)
引入
可能存在的问题:

此外,还需要拦截恶意的流量,并在特殊情况下对部分有效流量进行降级
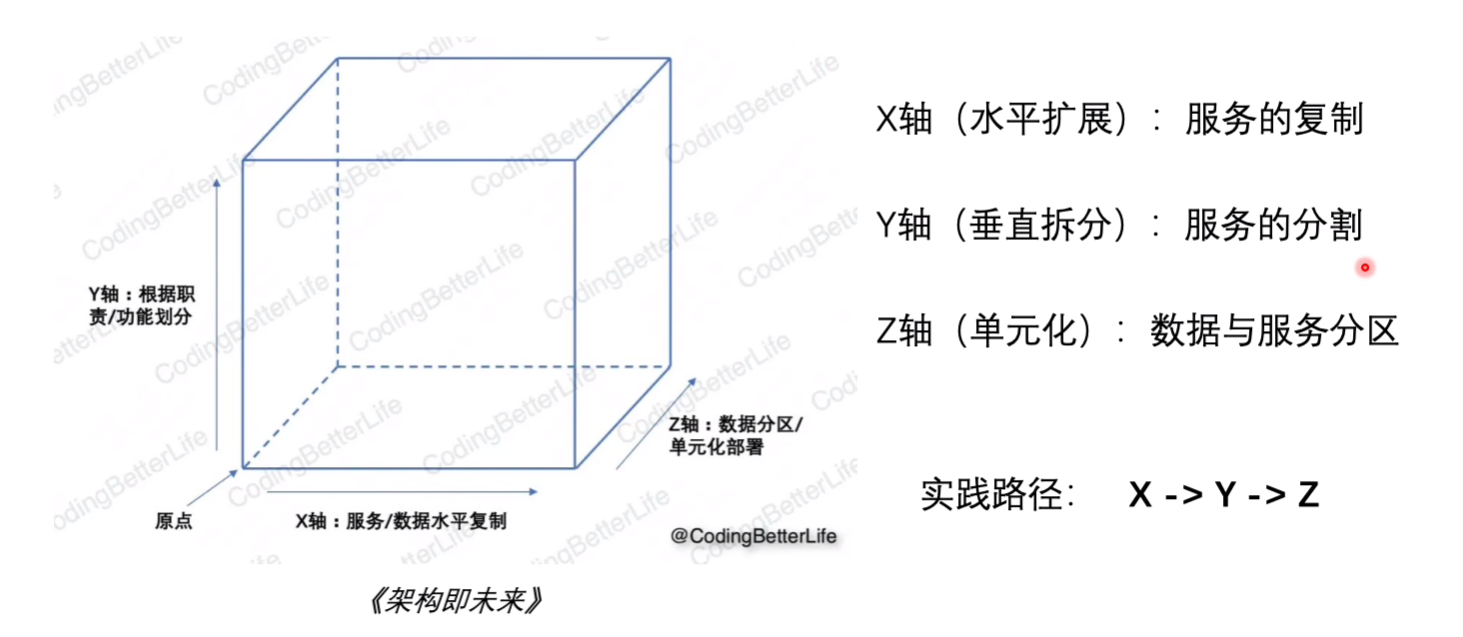
水平扩展
垂直拆分
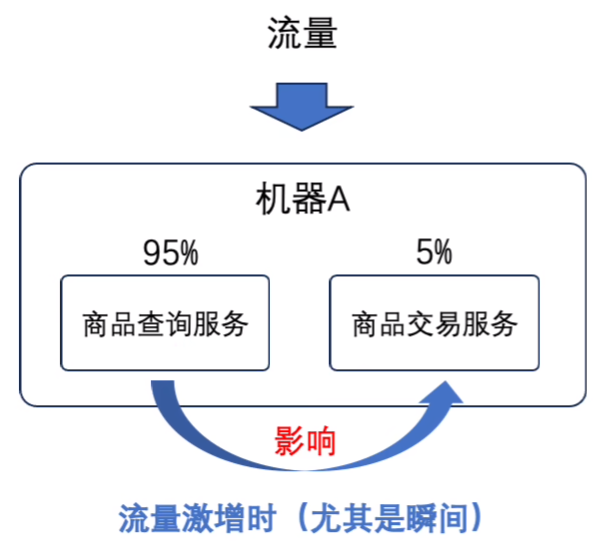
也就是微服务拆分,使得服务间不受到影响,隔离风险;灵活配置合理分配资源
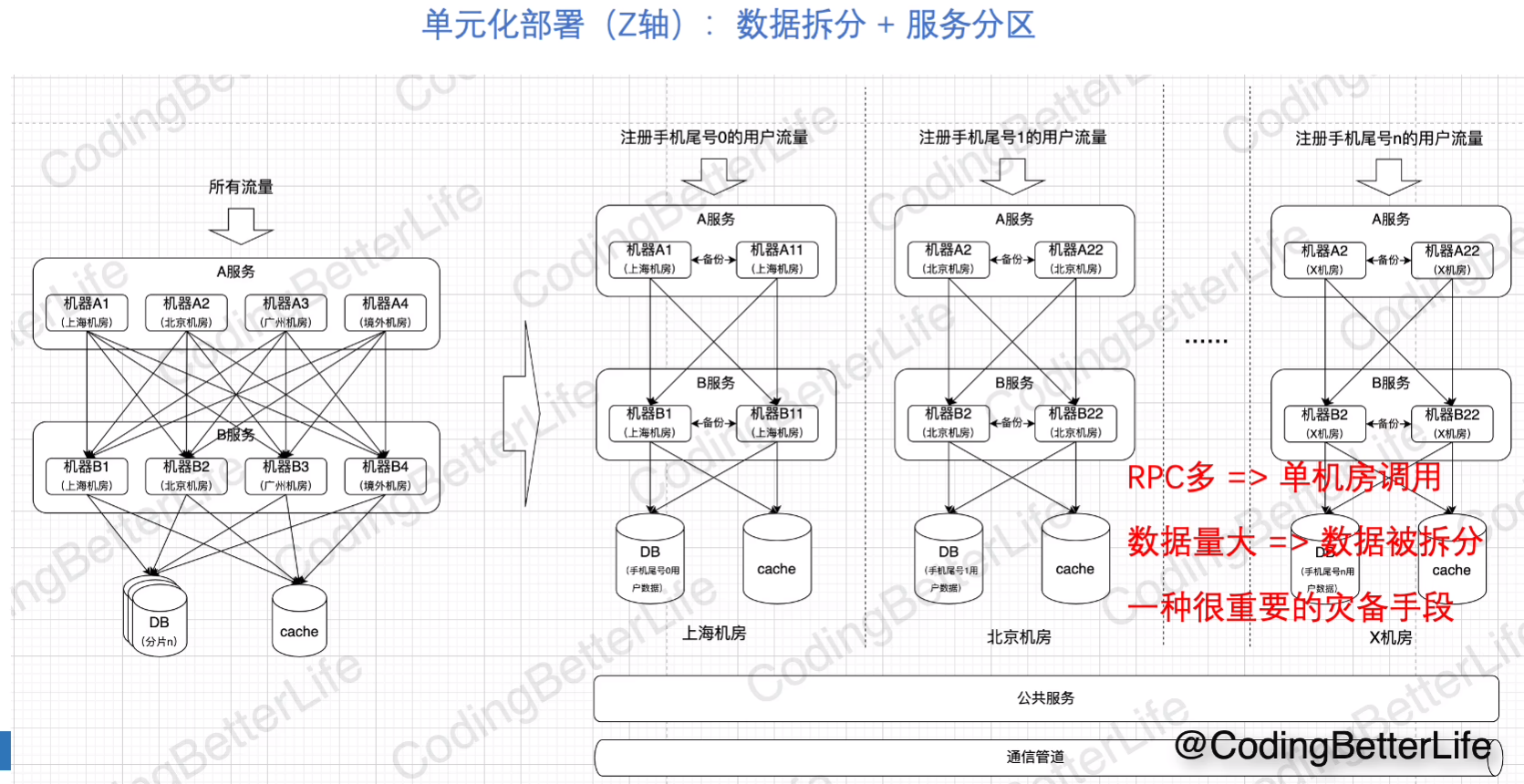
单元化部署
通常情况下前两种够了,但:

根据用户的id,在服务上以及数据(sharding)上都进行拆分
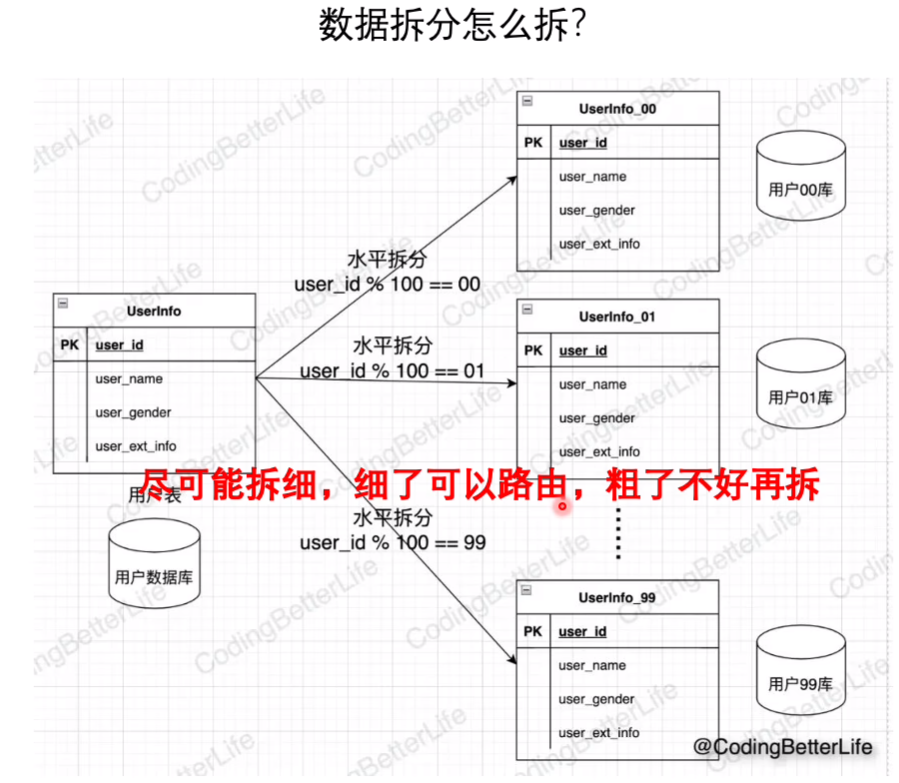
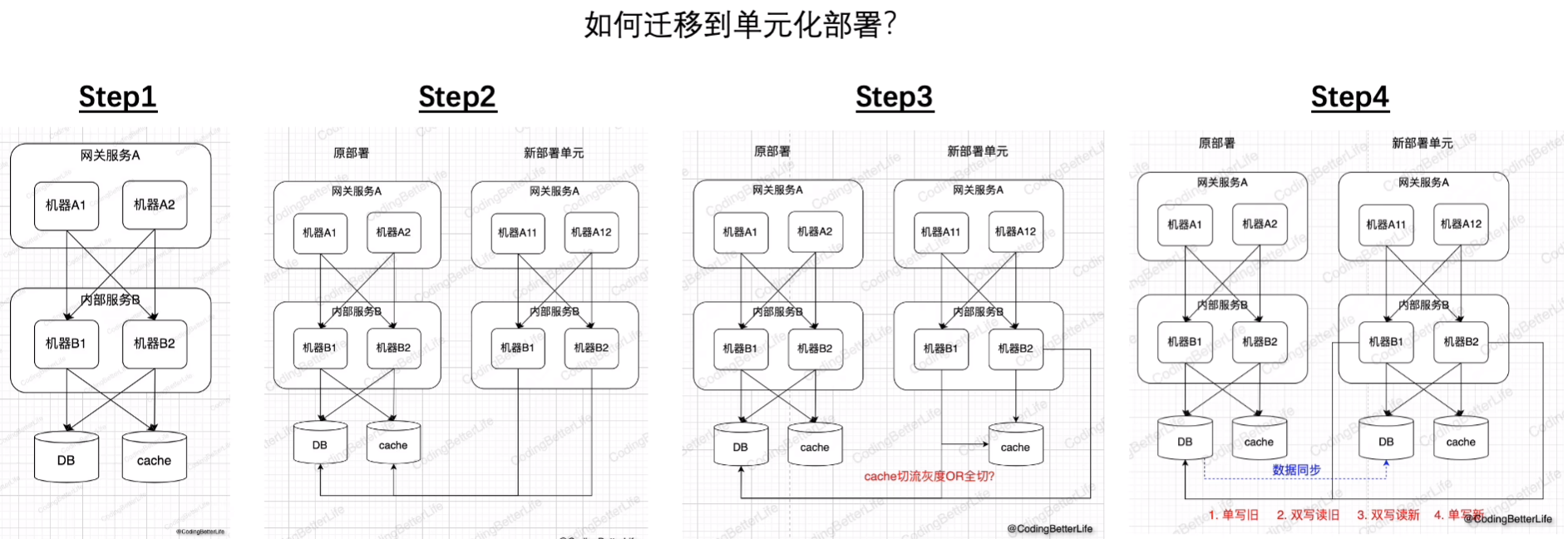
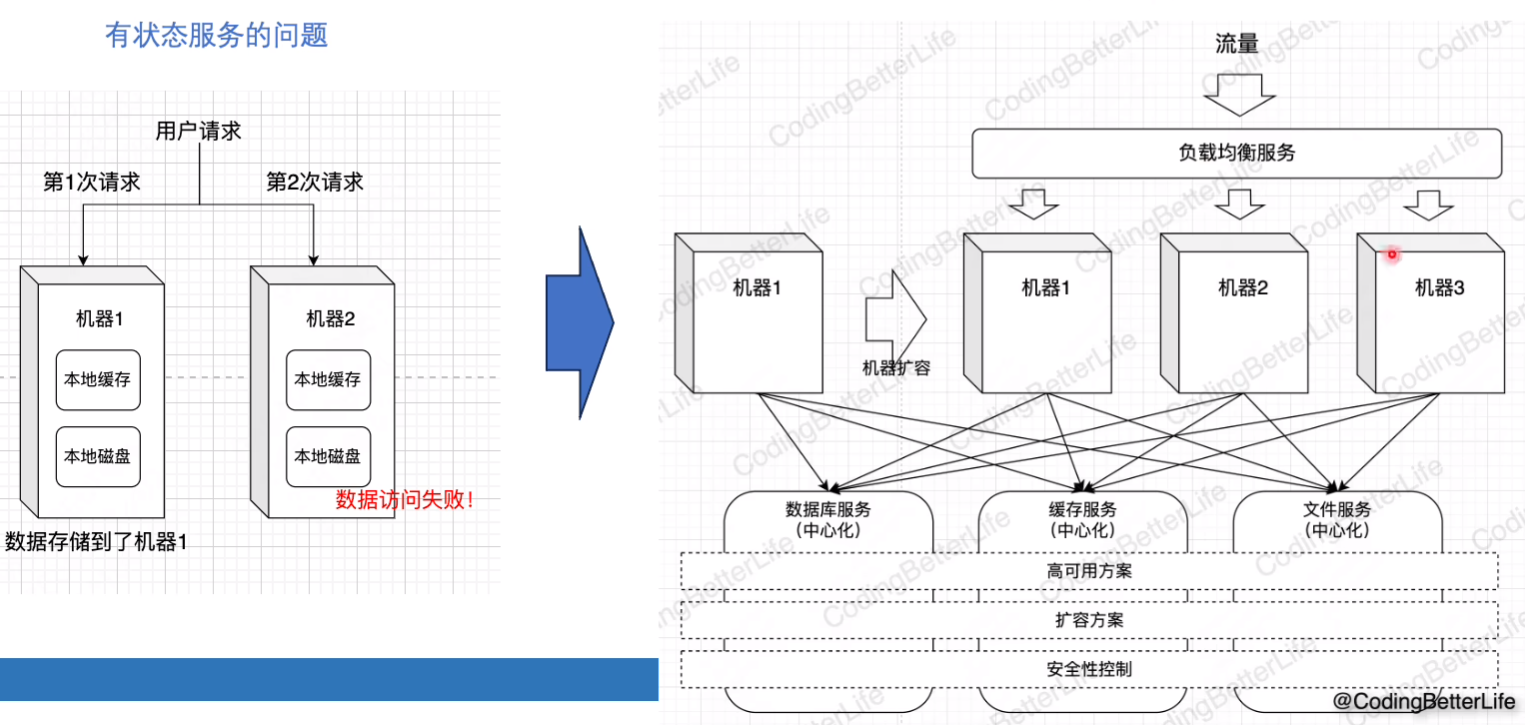
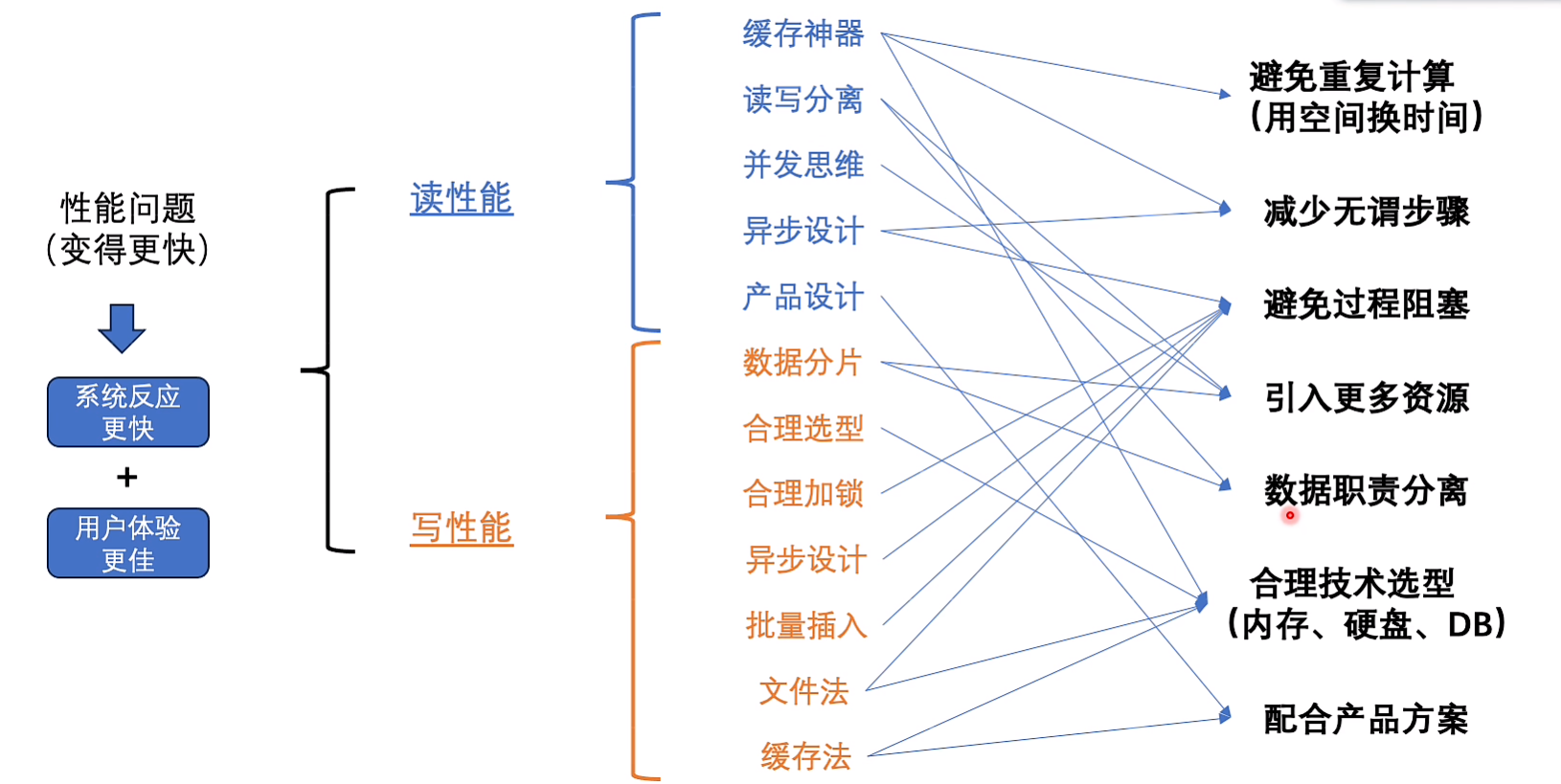
8.读的慢有妙招(性能)
后台服务高性能设计之道
性能:
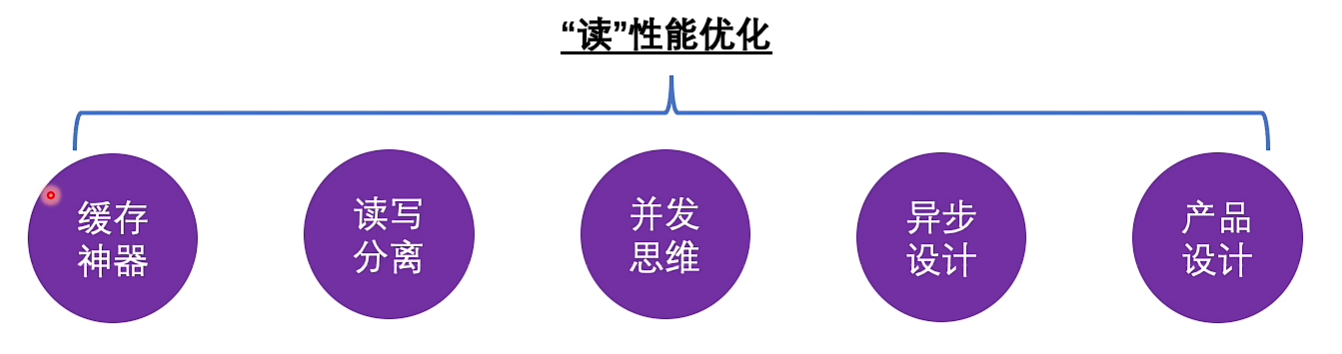
缓存
使用层面
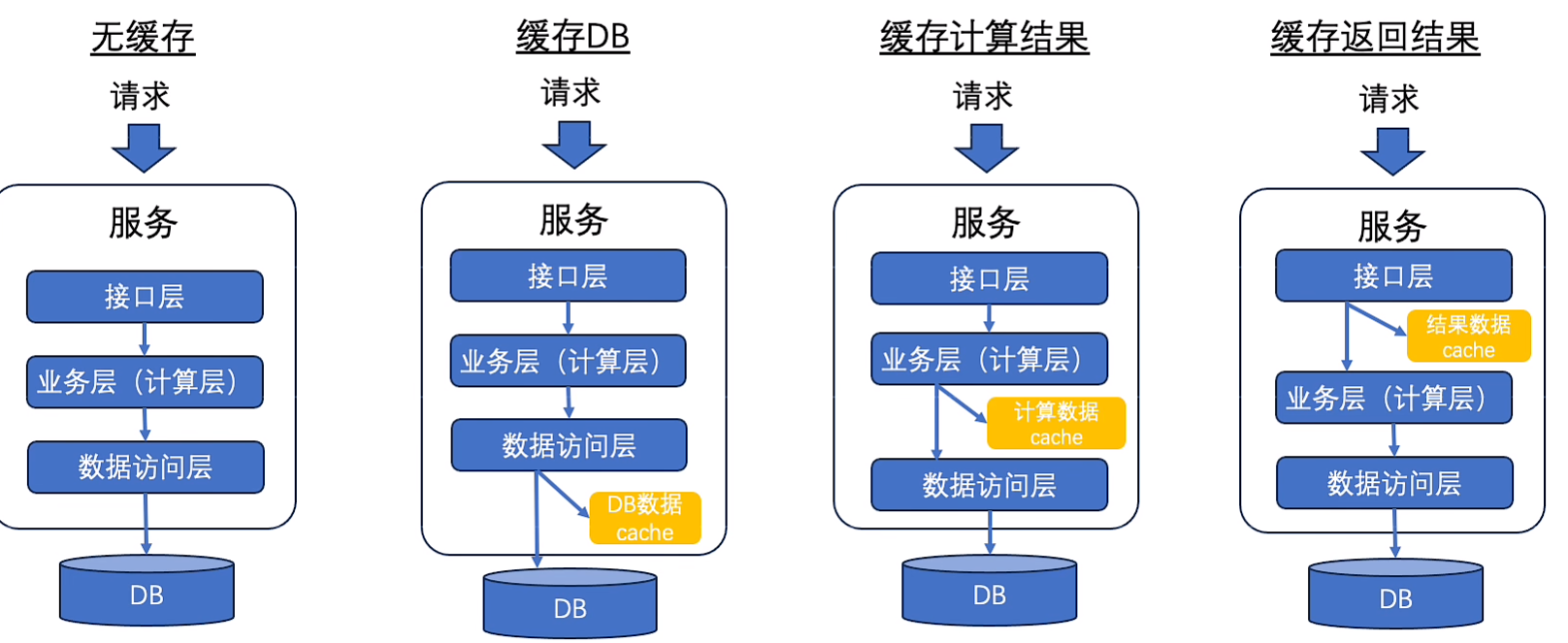
本地 vs 中心
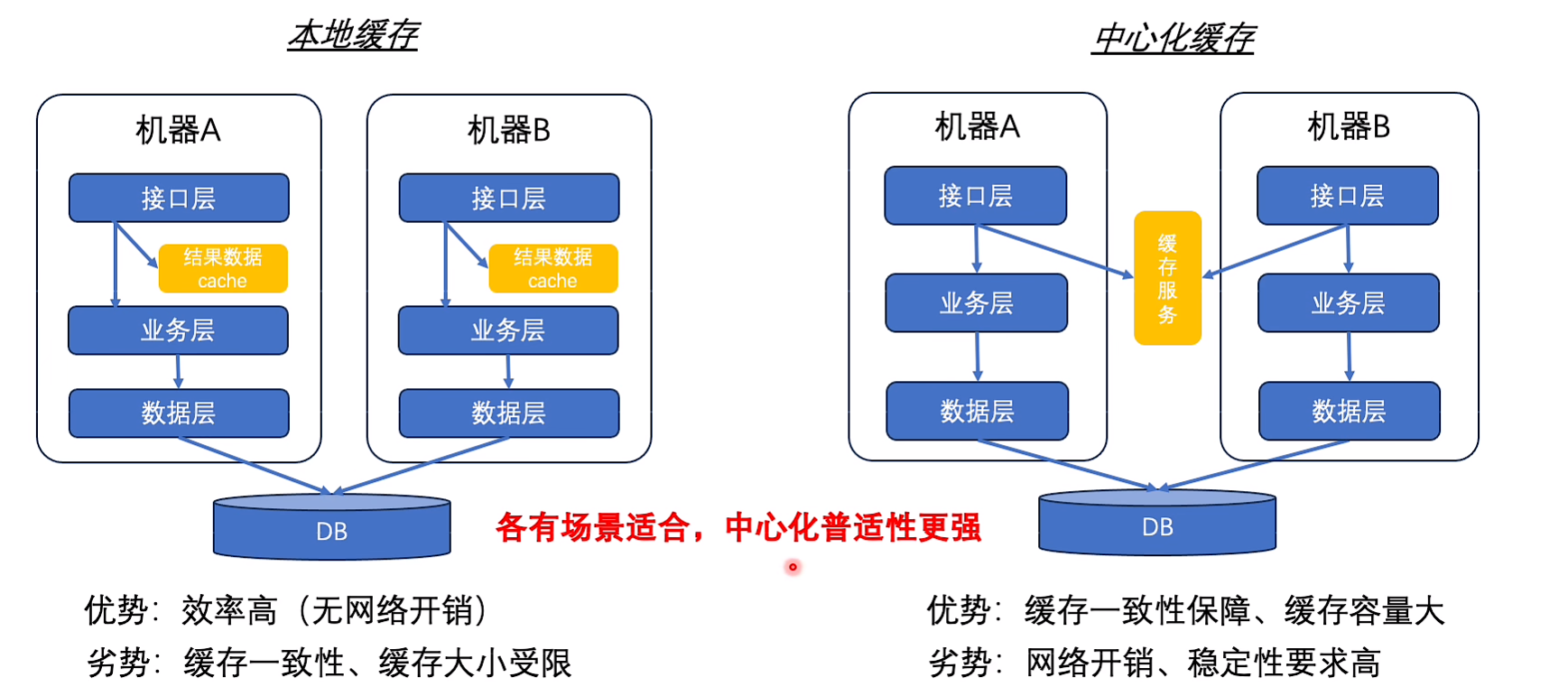
甚至于同时使用多级缓存
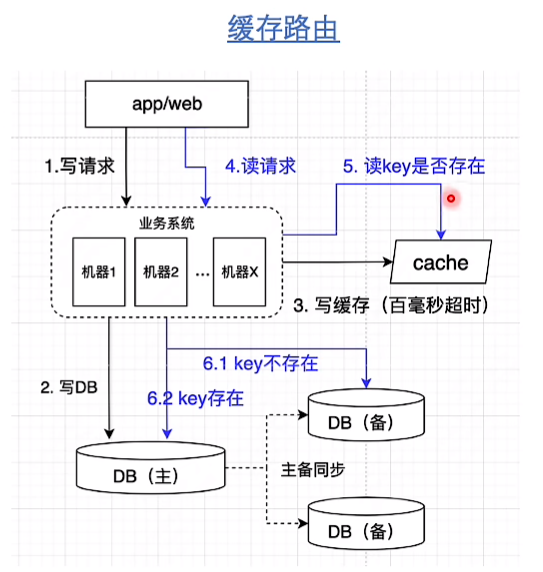
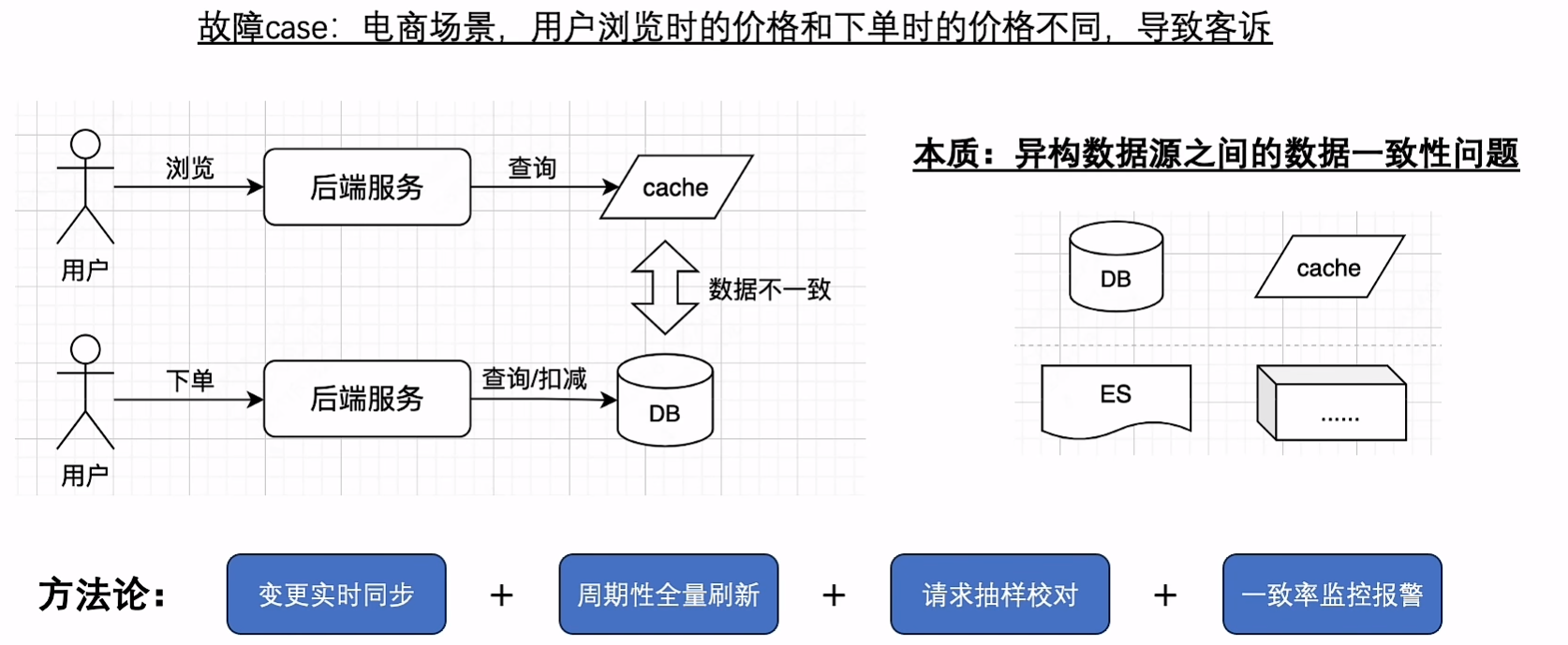
一致性问题
- 添加过期时间
- 先更新DB再删除缓存cache aside pattern(小概率:B来的时候没有缓存,B读取数据库,A更新数据并删除redis,B写脏数据到redis)
- 更新DB再更新缓存、更新缓存再更新db:
- 同时更新时顺序问题
- 多次更新时重复无效的更新
- 此外更新缓存再更新db,如果更新db失败,缓存不好回滚
- 删除缓存再更新db:A删完缓存来了查询B,B查询完成后写入脏数据到redis
- 延时双删:先更新DB再删除缓存,再异步删除 (实际上网上资料都是先删除缓存再更新DB,再异步删除)
- 缓存永不过期,并且周期性全量刷新
读写分离
DB的访问做读写分离,写在主,binlog等方式同步到从
一致性问题:
并发
一个通用的思路,针对性能问题通用解决方案
异步
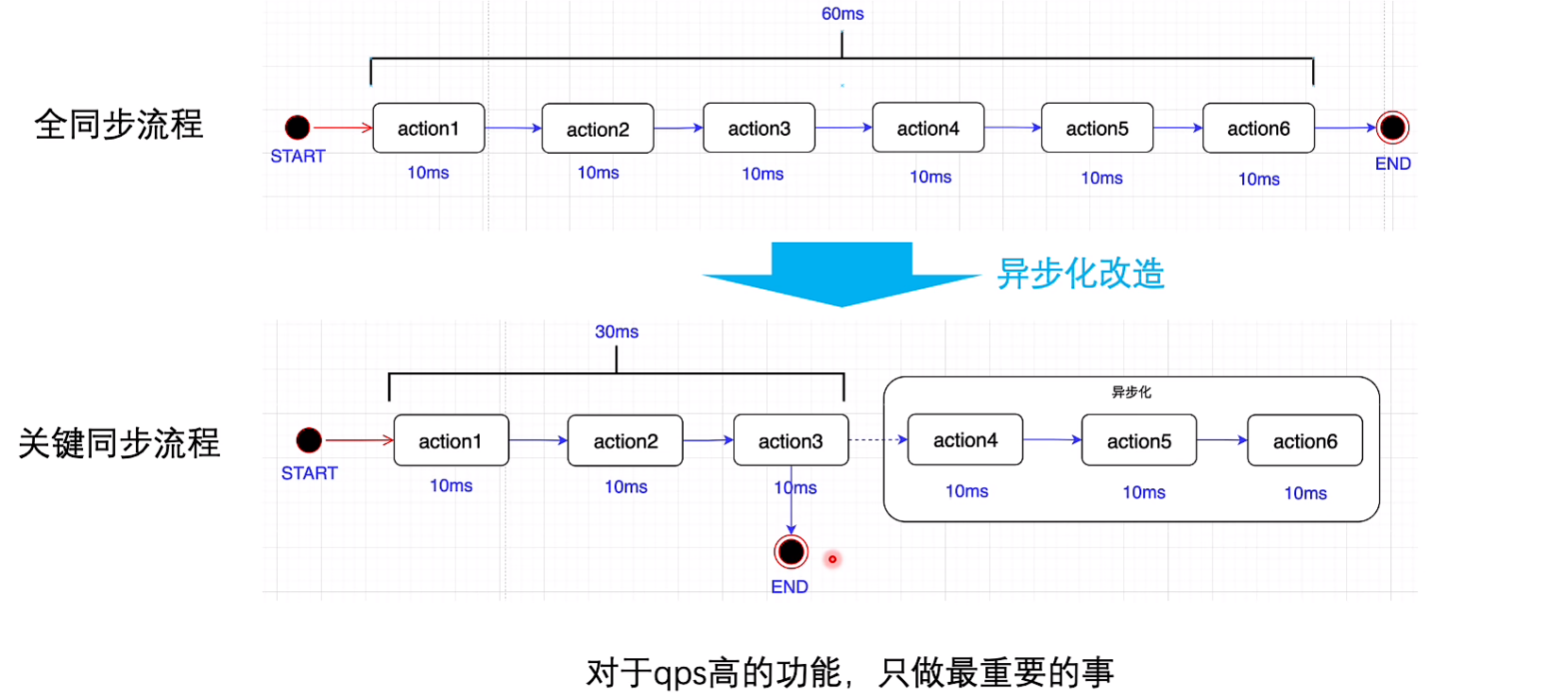
其实就是之前提到的转载后的打点使用异步线程池实现,主线程直接返回
产品设计
- 分页
- 递进展示
- 降低极致的准确性要求,允许短暂的不一致
- 峰值流量降级非重要功能
- 控制主动(点击重试)或被动(超时重试)重试
其他 优化协议、流量拦截、静态缓存、数据压缩等等
9.写性能难提升(性能)
为什么难?
- 写的丢失代价大
- 写必须要磁盘(可靠性场景),而读可以是缓存
- 写时常需要加锁
- 资损
选择数据库
合理加锁
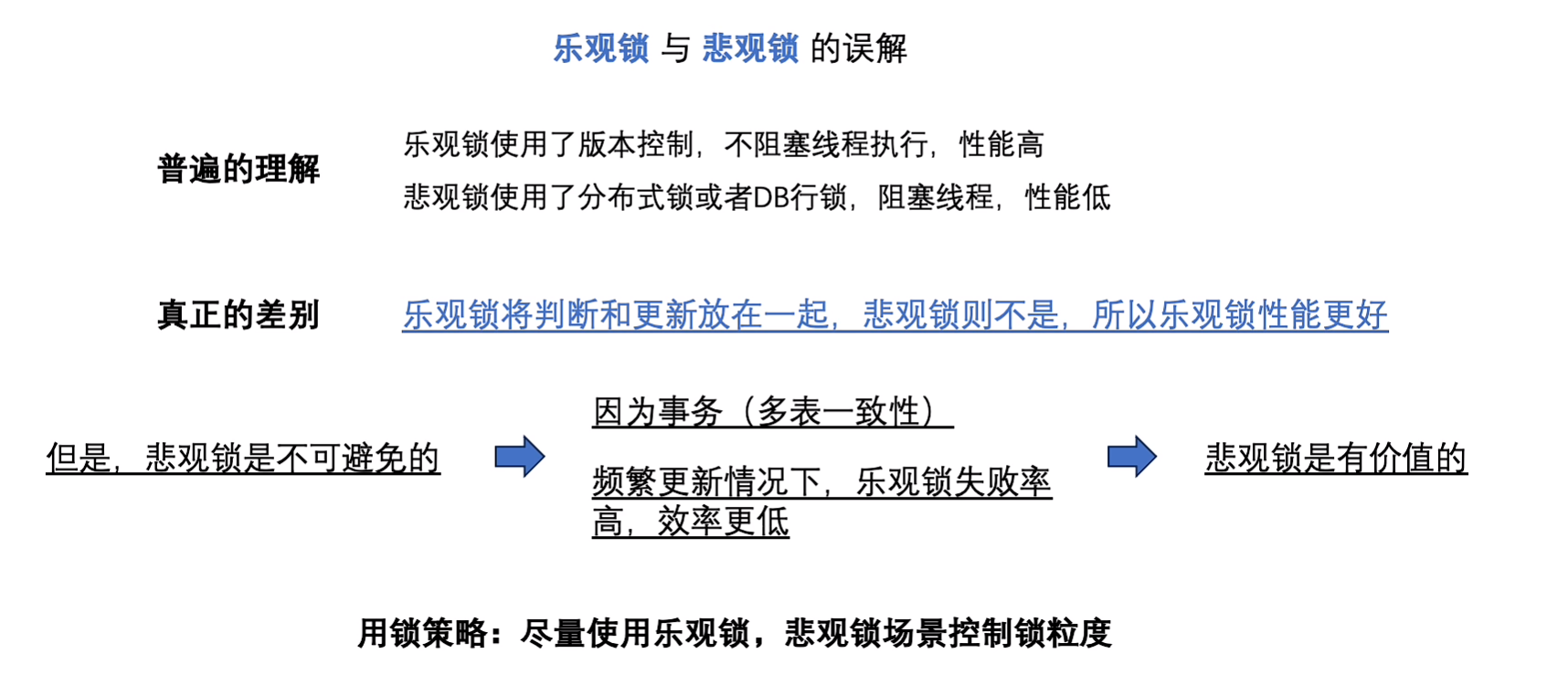
异步
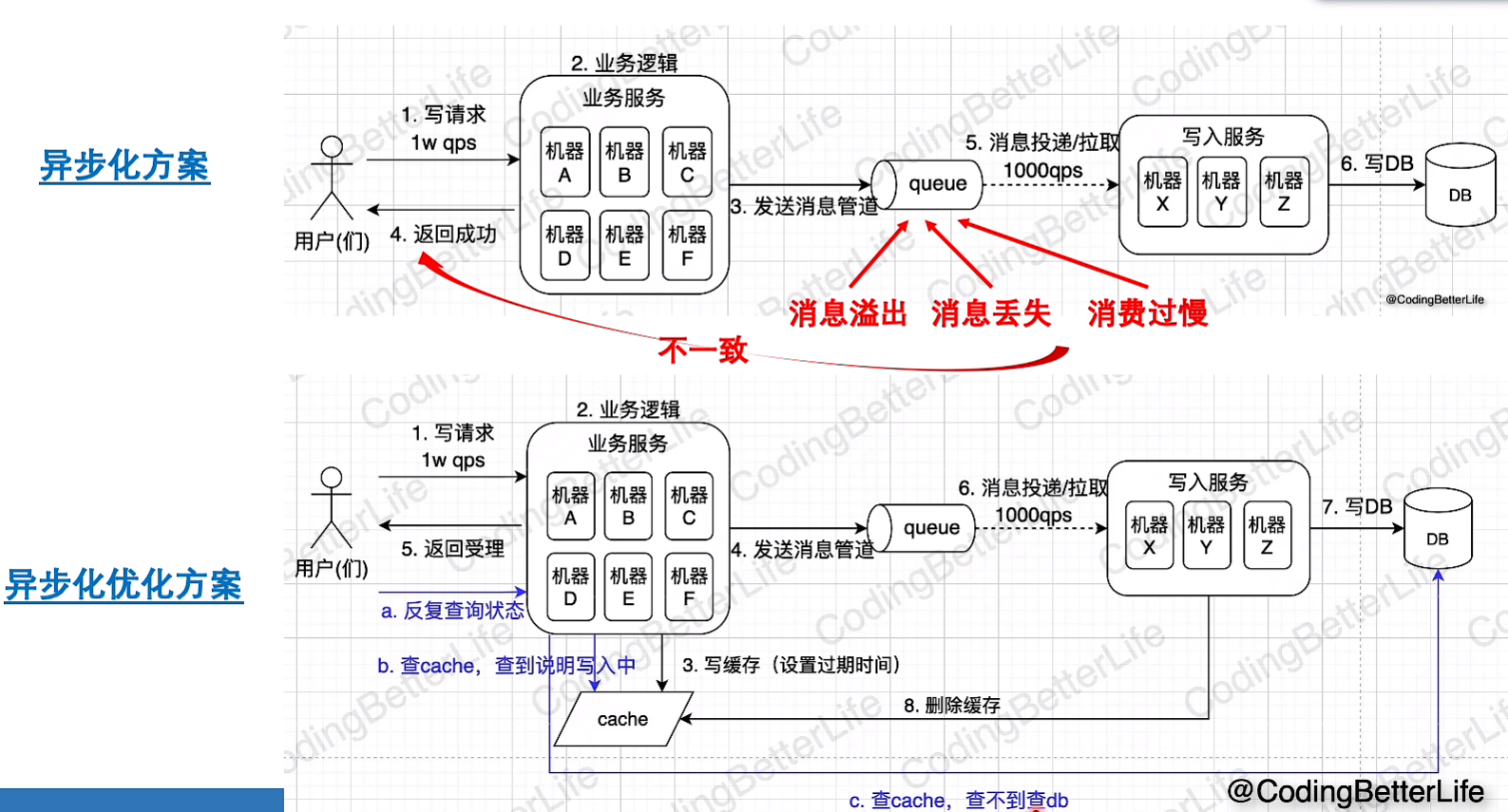
优化方案的轮询是查询缓存的,放置数据库压力过大
TODO:添加一个缓存标记,可以用在判题请求中,这样轮询时就不用查询数据库
批量插入
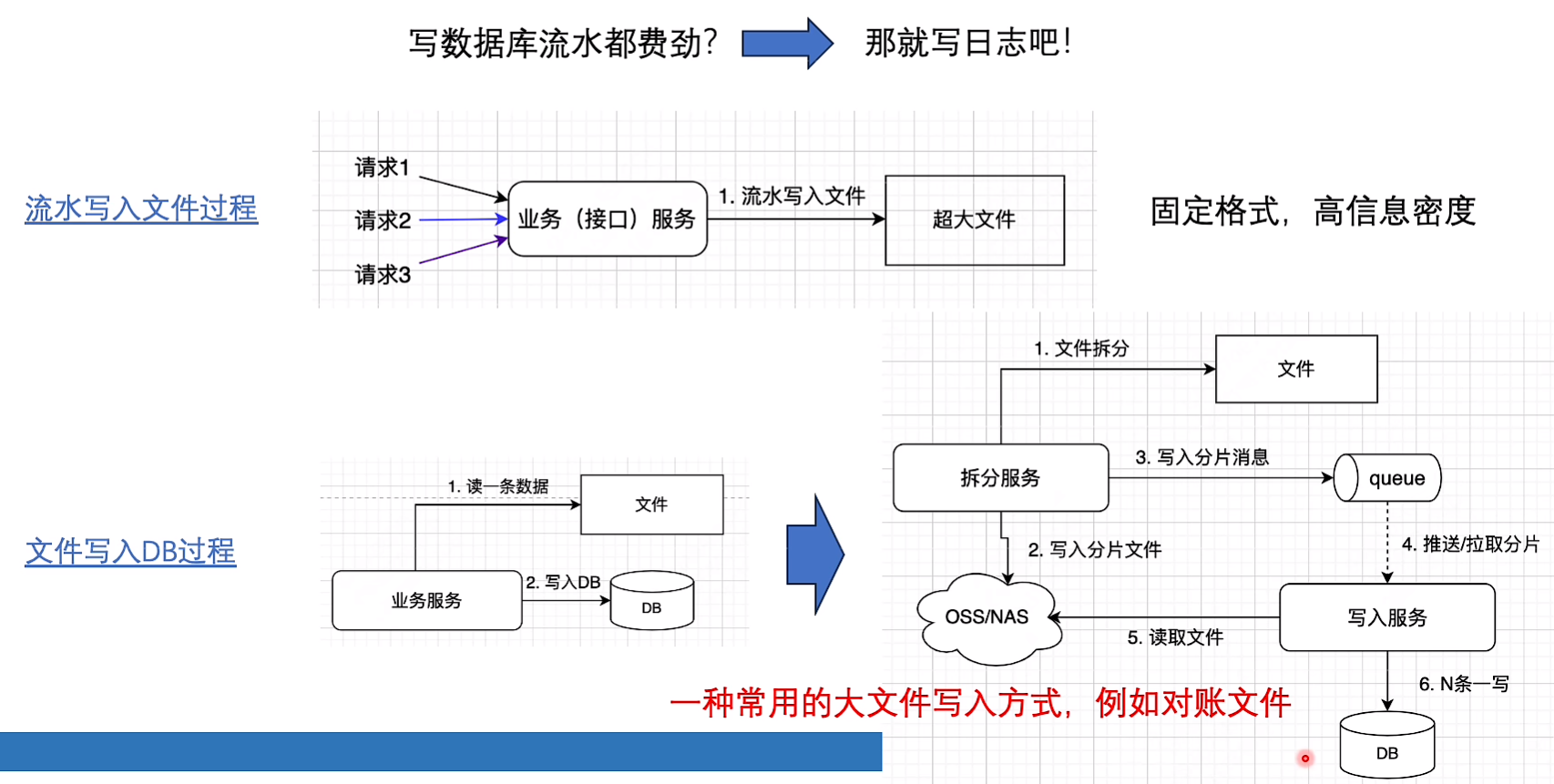
文件
文件系统的写入通常比数据库写入要快,之后再把文件同步到db,同步时可以使用拆分思想并发处理
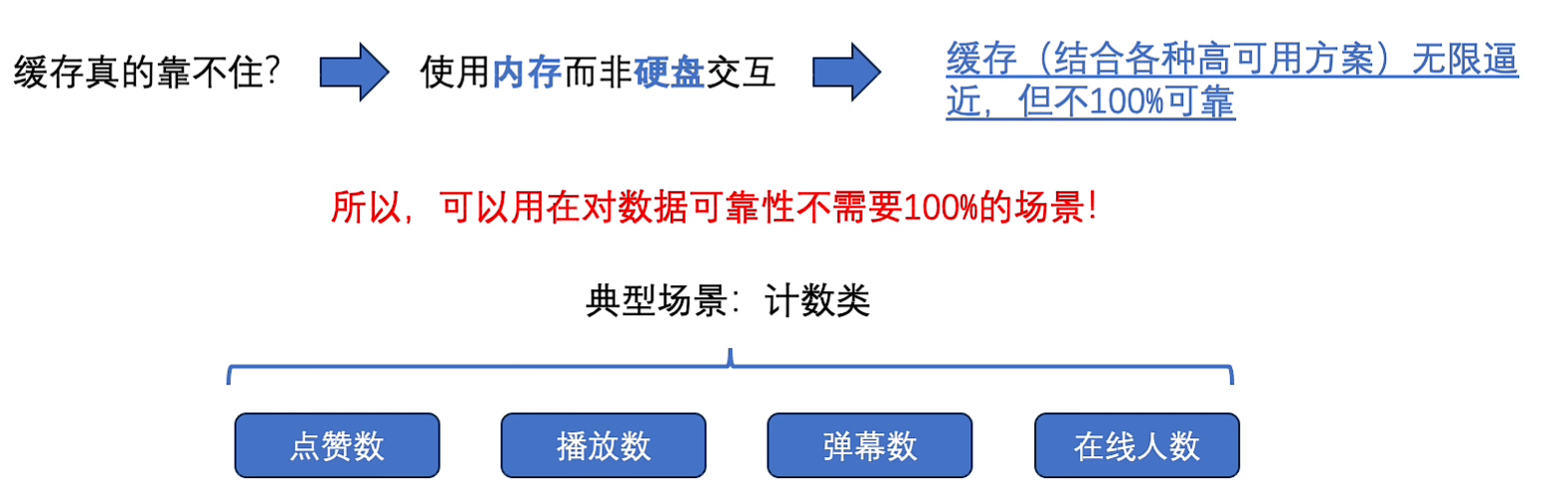
缓存
并不需要百分百正确,缓存挂了就捞取redis自带的持久化数据,或者自己定时任务捞取缓存持久化到数据库
总结
10.稳定性引入
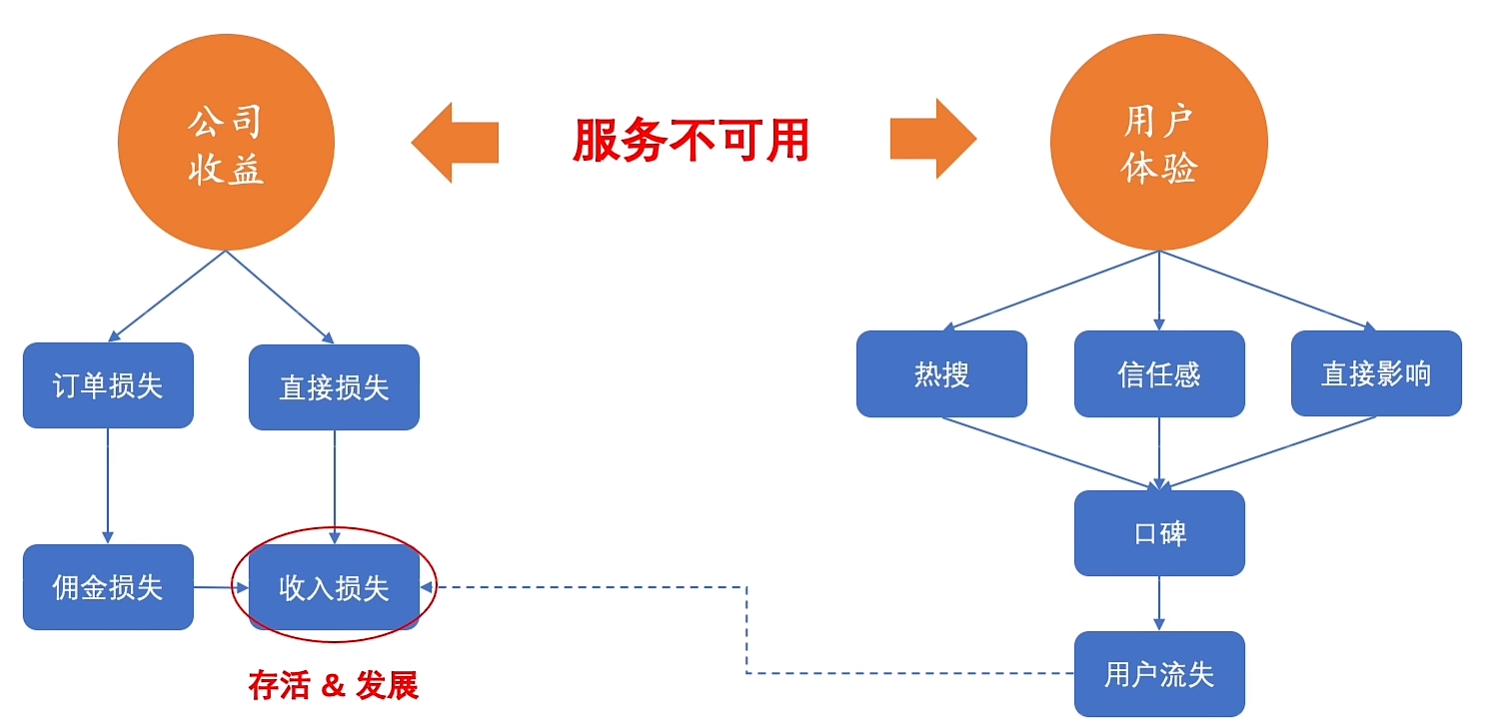
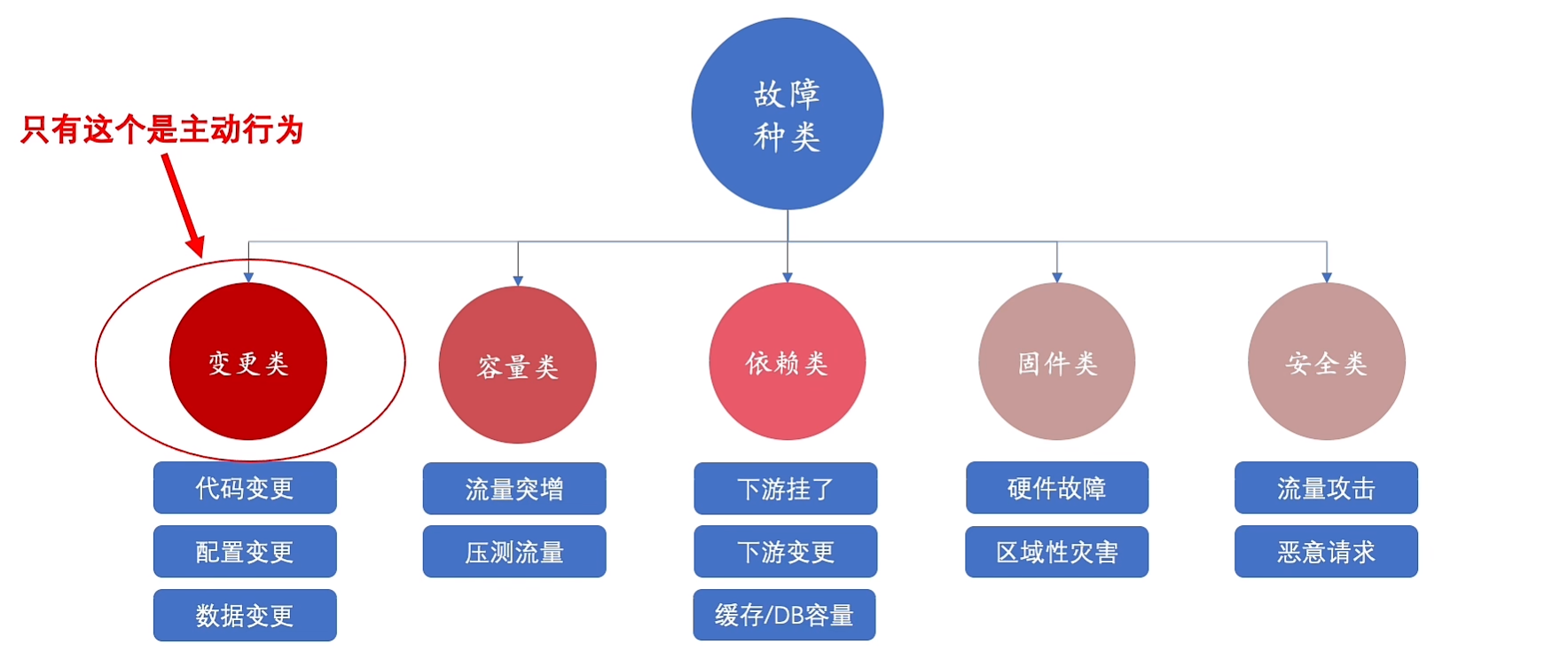
核心服务4个9:52.6 mins 一年不可用时间
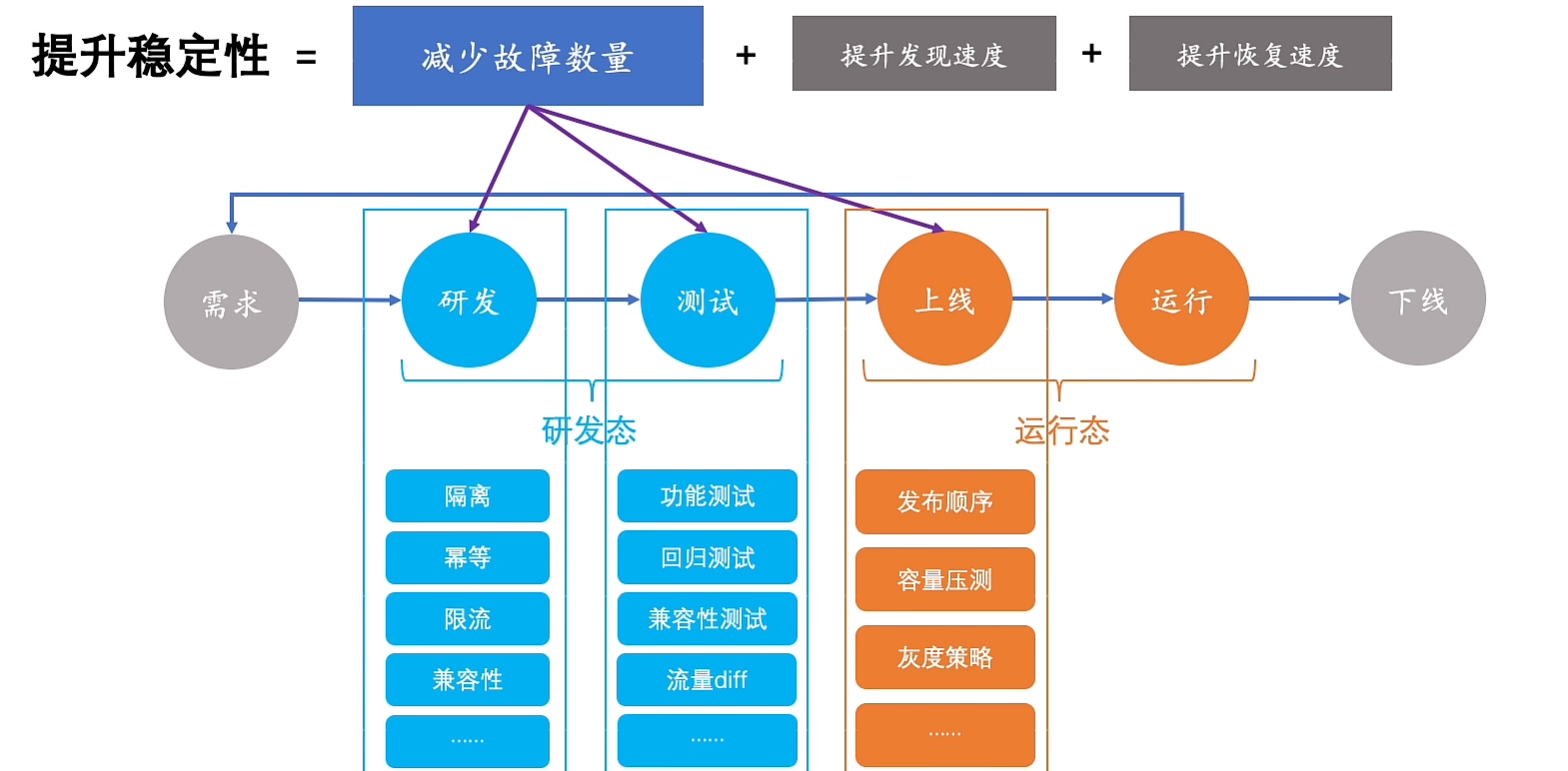
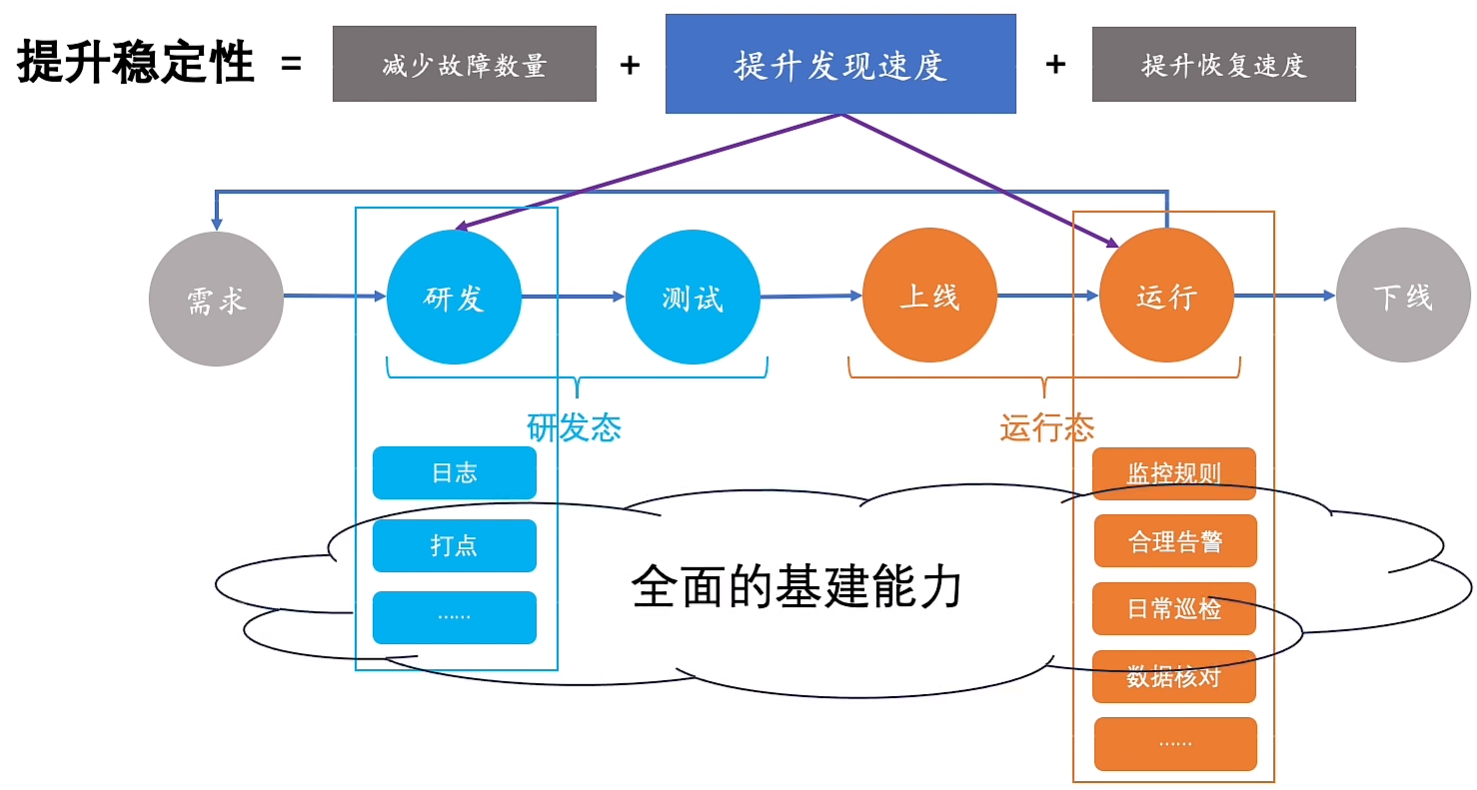
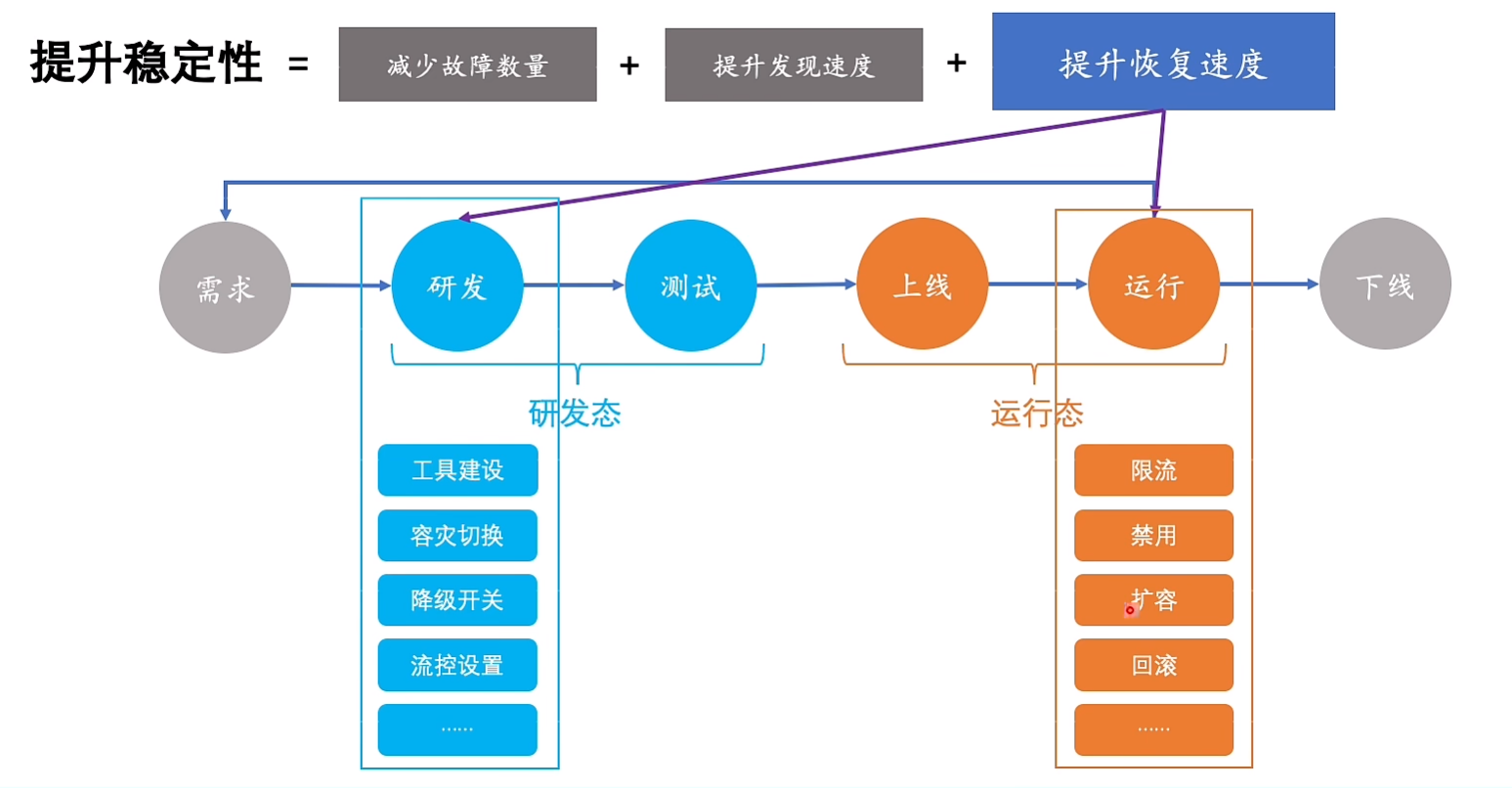
总结引入
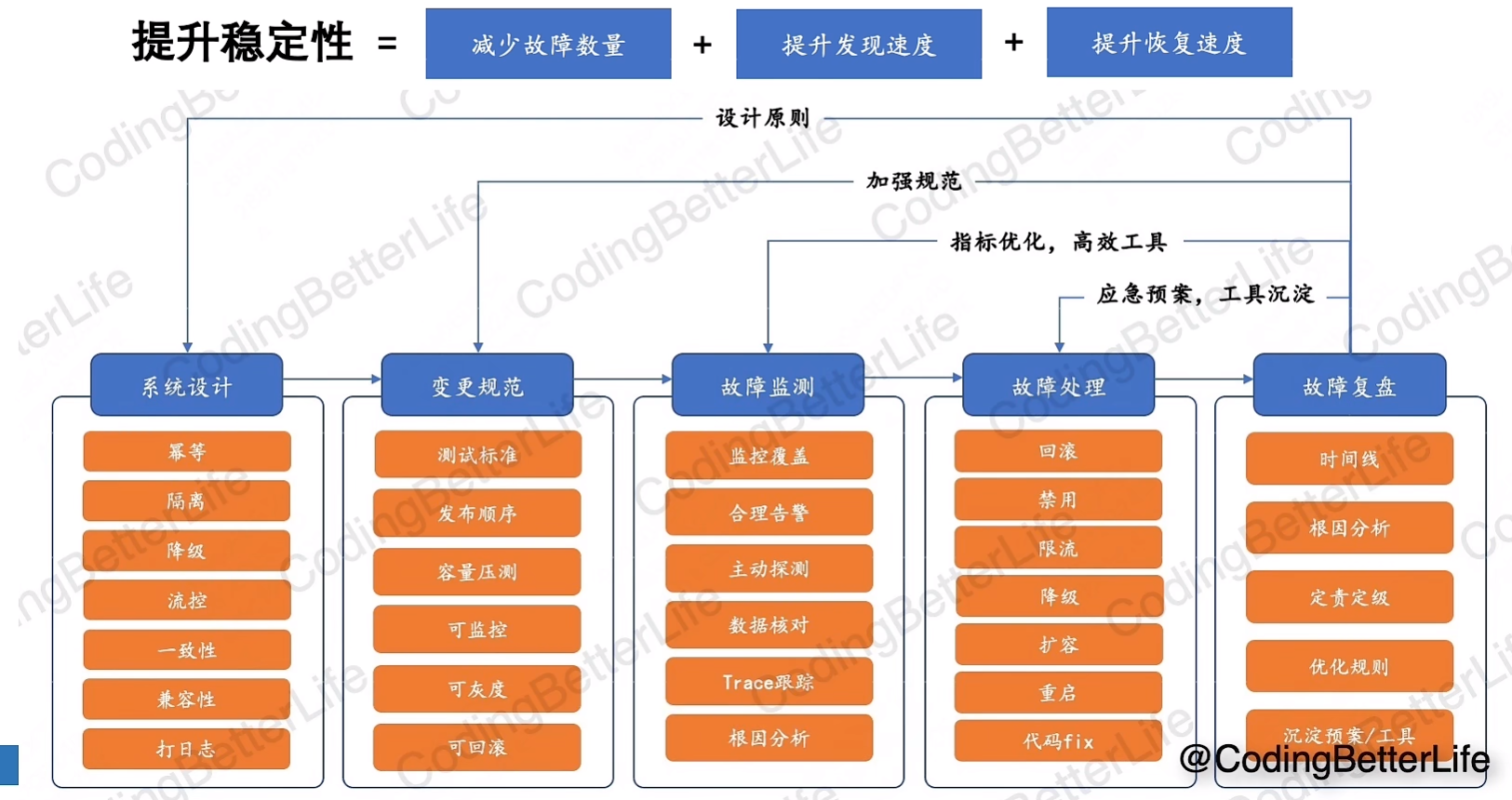
11.稳定性之设计时
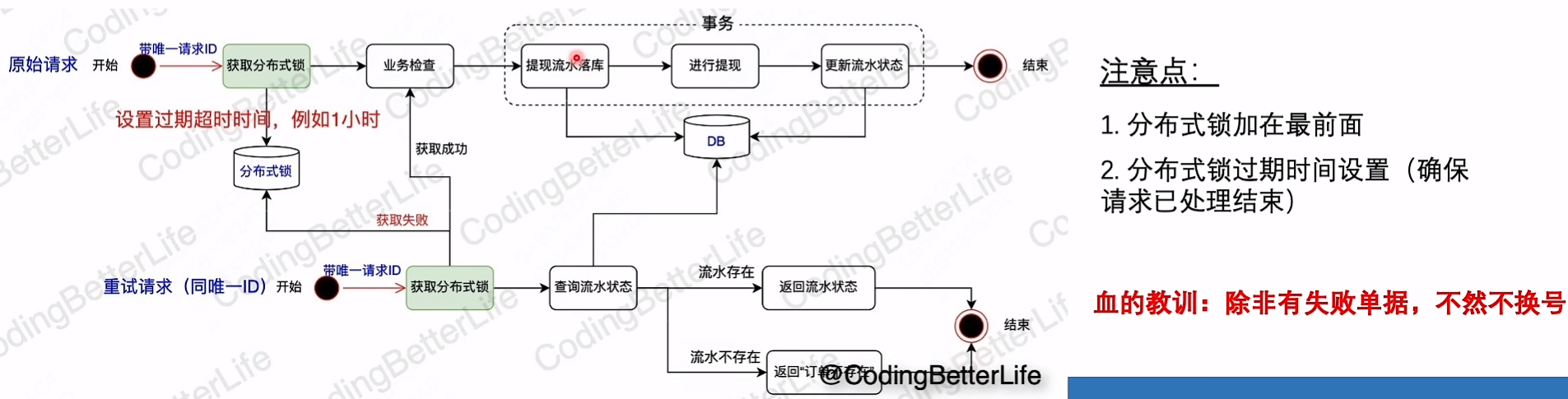
幂等
请求携带唯一ID(可以前端生成也可也后端生成返回)
后端流水数据库唯一ID key,业务前需要先落库流水数据库实现幂等
更进一步,添加分布式锁
隔离
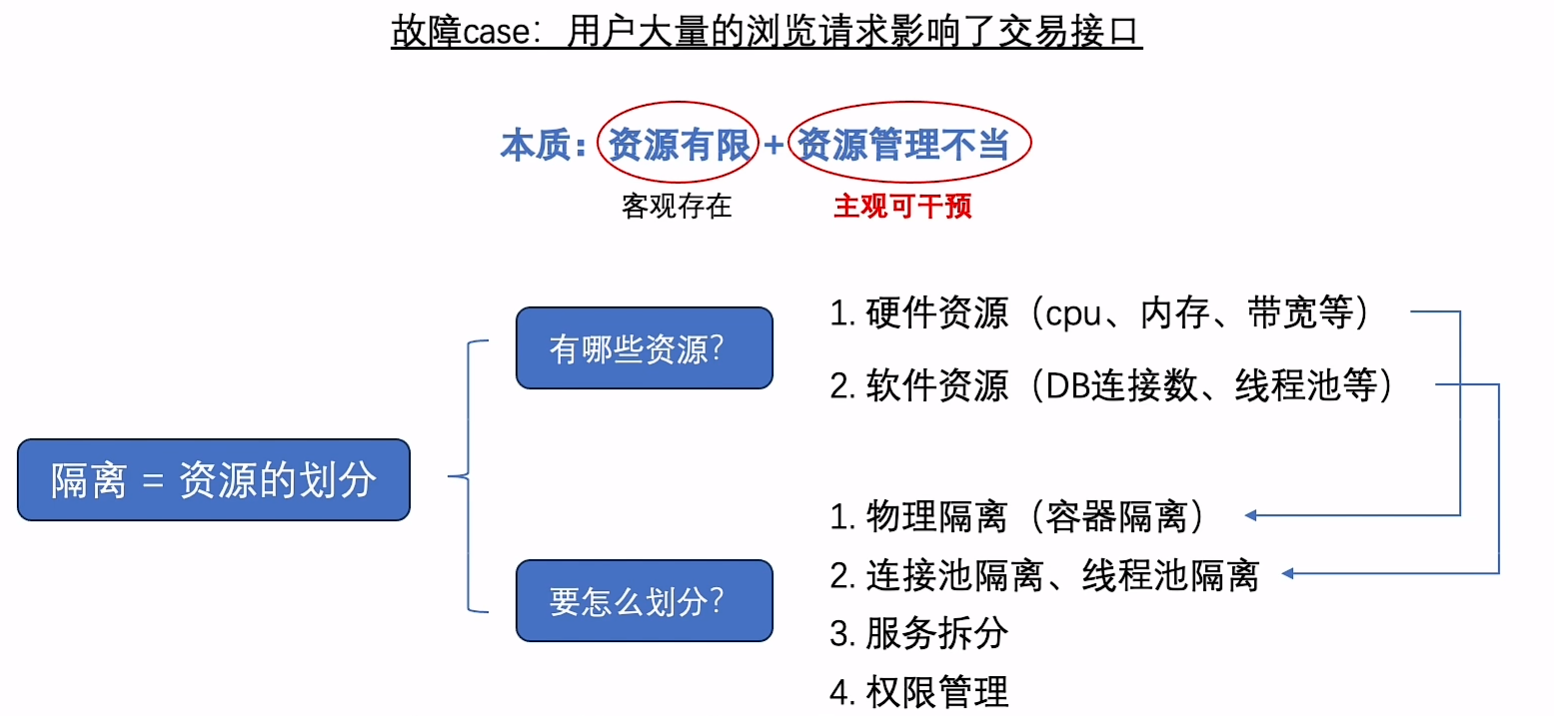
降级
避免被下游影响;强依赖变成弱依赖,账单服务失败不能影响查询余额接口;
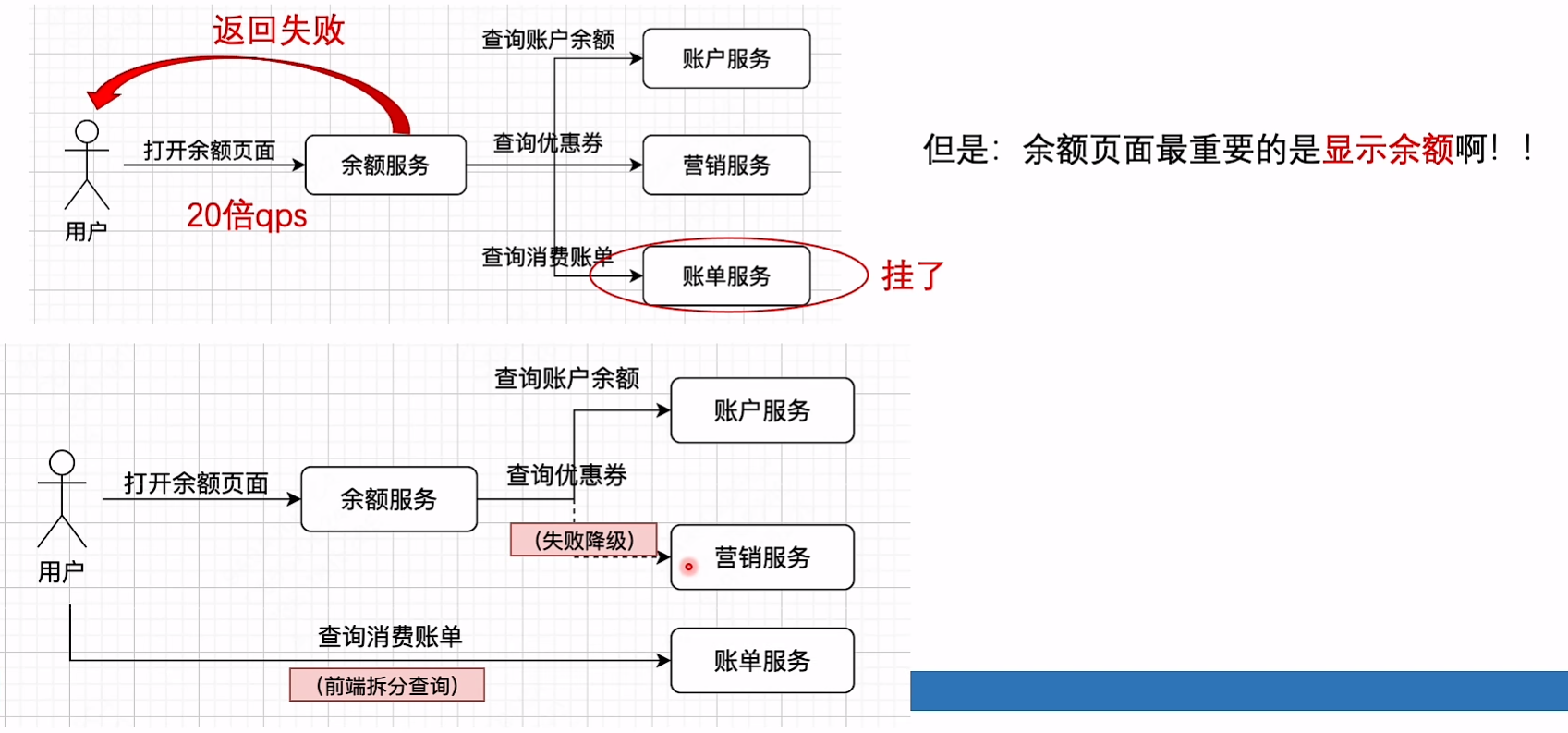
- 前端直接拆分成两个请求
- 直接try catch,这里还是会对下游发起请求,如果下游返回时间比较长,还需要等待
- 通过配置中心(一般会缓存到本地,配置变更再推送),根据配置决定是否请求
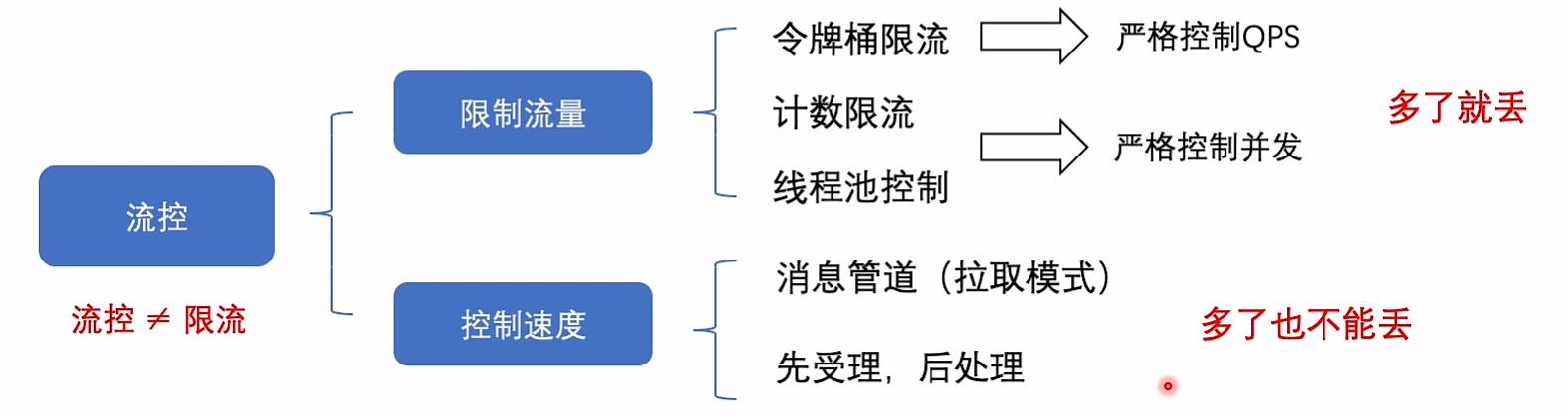
流控
避免被上游影响
一致性
兼容性
旧接口进行了改造,字段发生了变化
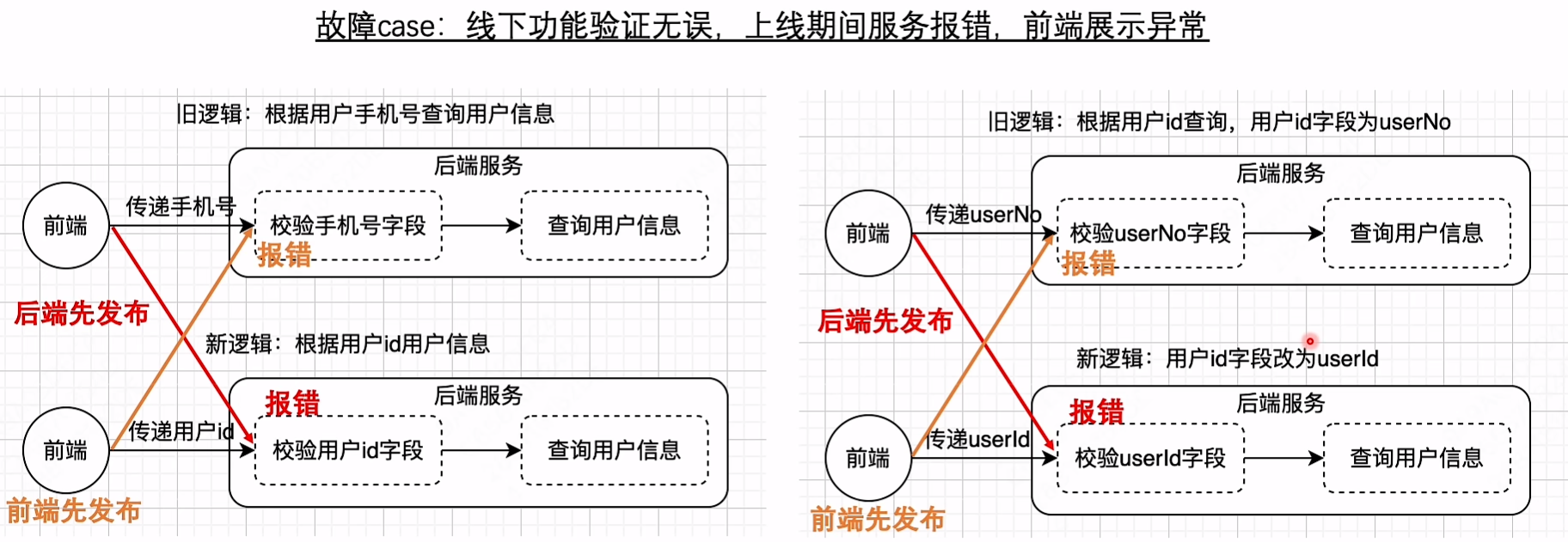
标准方法:后端逻辑需要兼容旧逻辑,前端字段冗余,新旧逻辑都要传递;之后定时清理
因此在该变更场景中,实际上是先新增一个字段,再清理时删除原字段
打日志
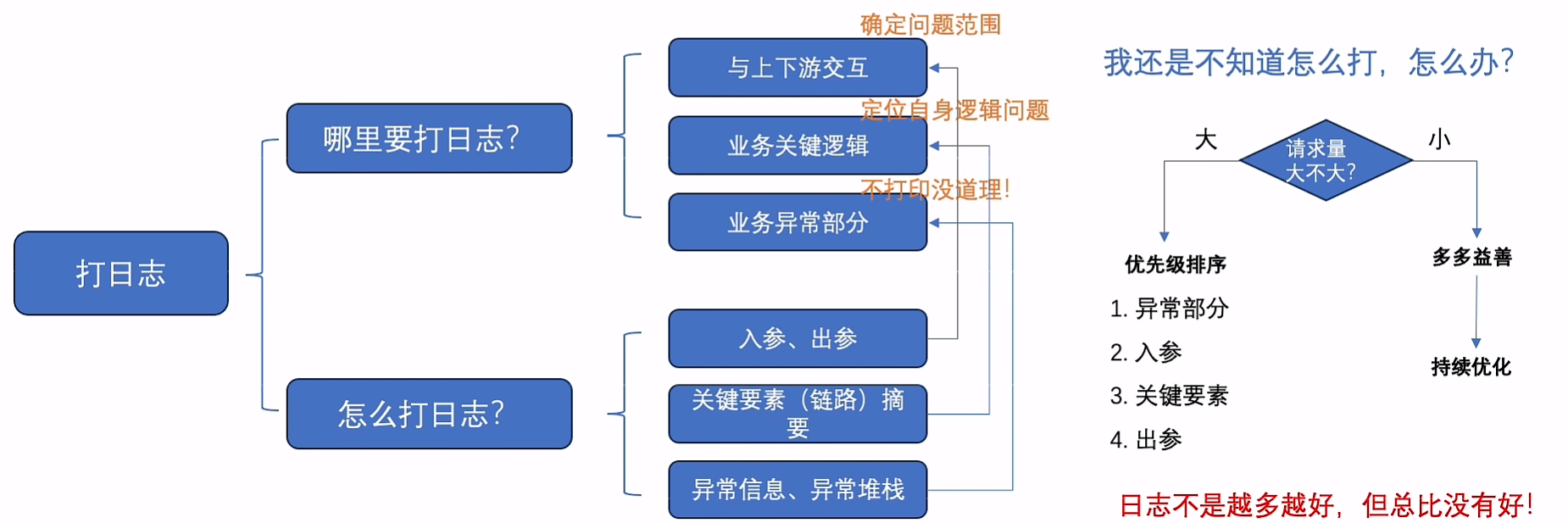
- 可以接受的错误,存在降级策略:warn
- 预期之外、会终端流程:error
- 大厂最佳实践通常是异步打印日志:磁盘 -> 发送到队列,由别的线程负责
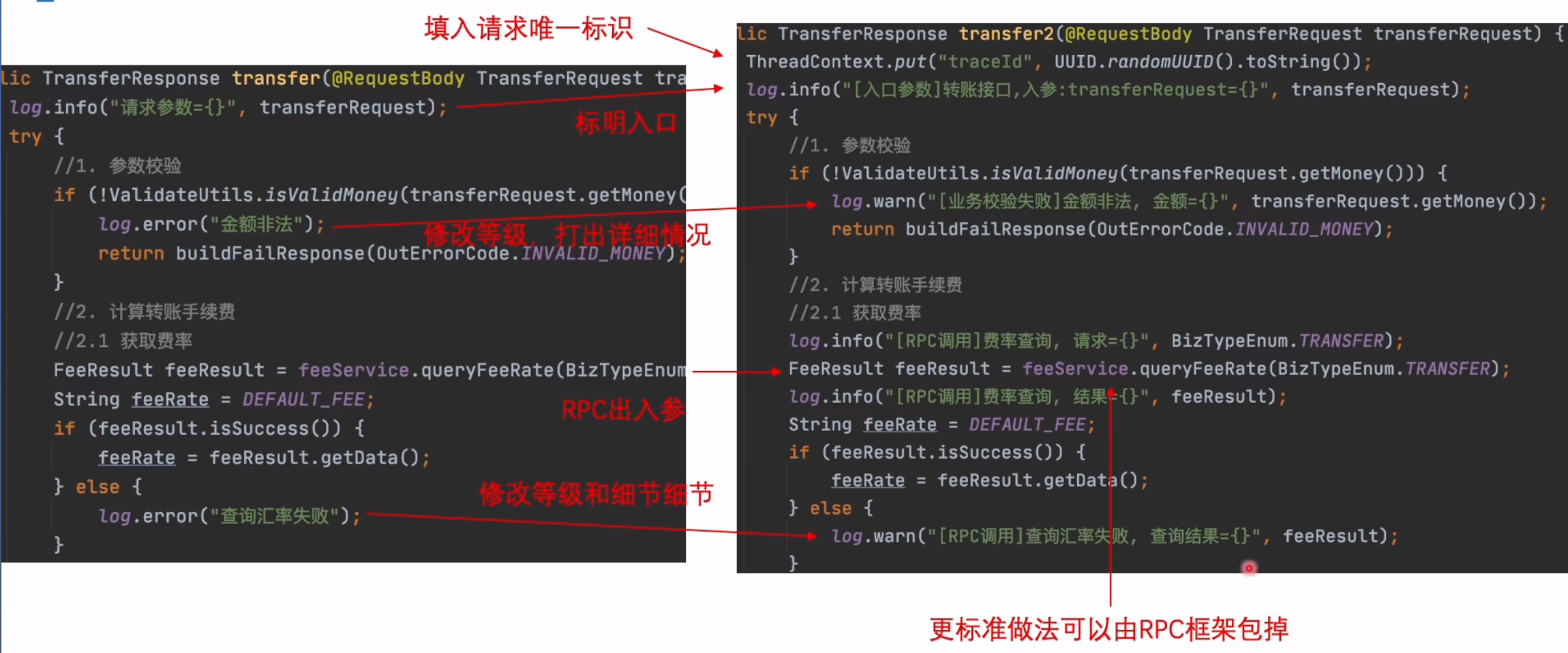

摘要日志
可以结合工具做统计,可视化等

12.稳定性之变更时
升级产品功能、修复产品缺陷;80%故障
测试
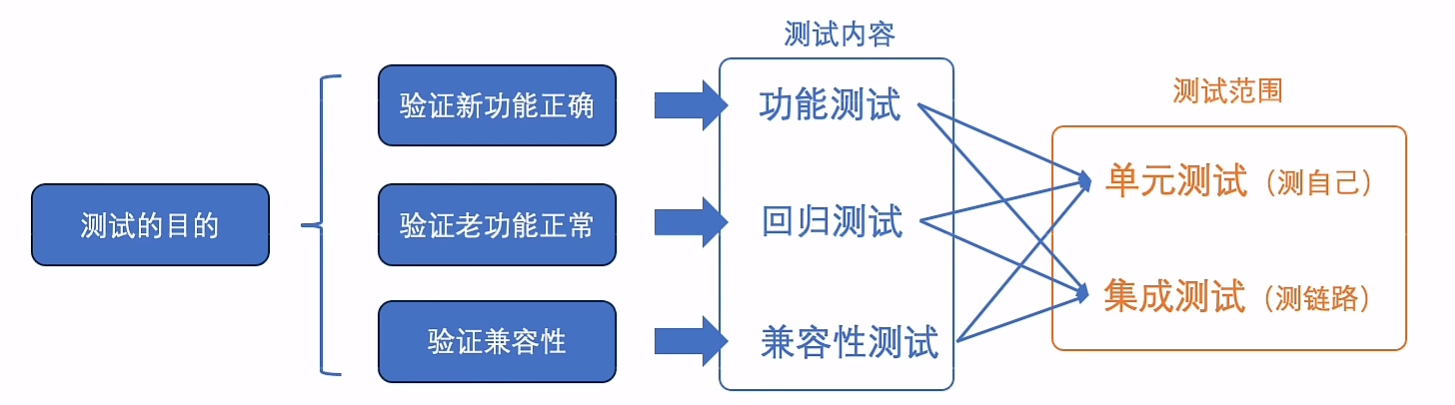
兼容性和前面说的类似,下游同时兼容上游新旧代码 a调用b:a旧-b新、a新-b新、甚至于a新-b旧
对比流量
流量复制
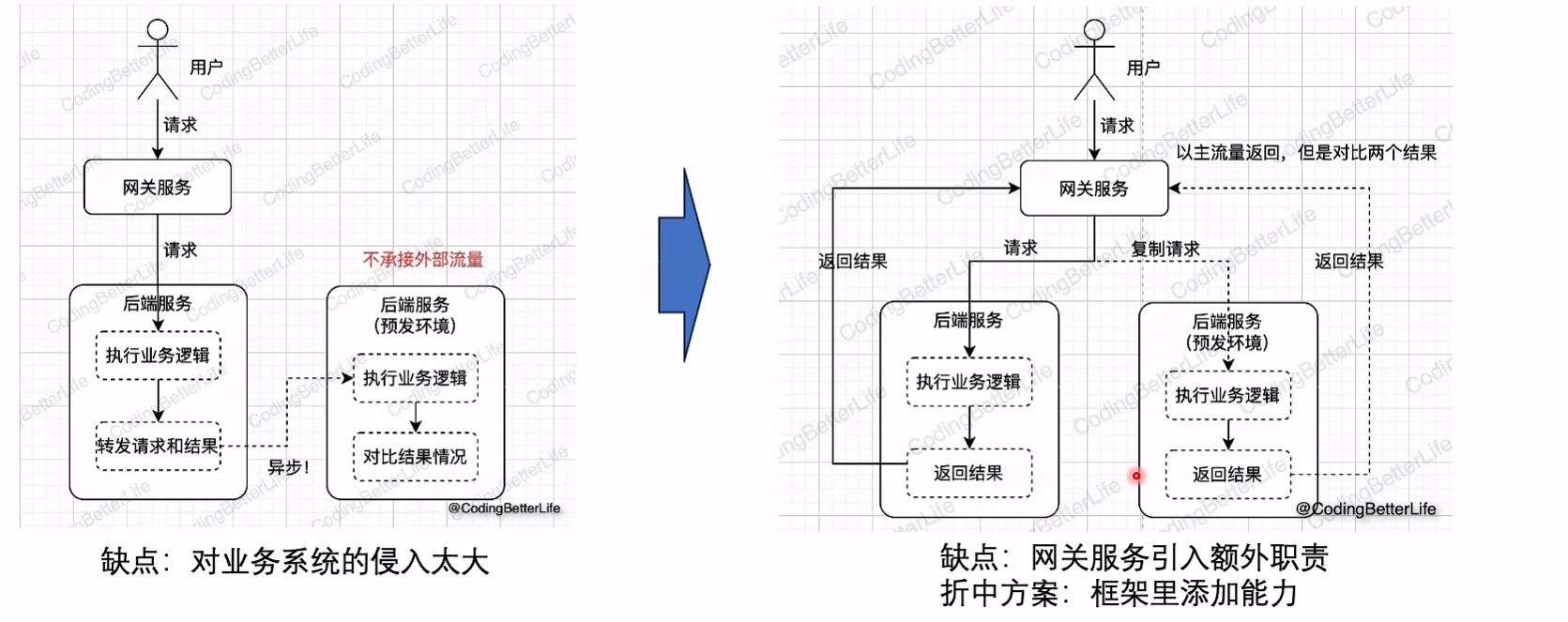
预发布环境DB、Cache相同,因此只能针对读服务
- 方法1. 线上在业务执行完成后转发到预发布环境,存在入侵
- 方法2. 在网关同时转发到两个环境
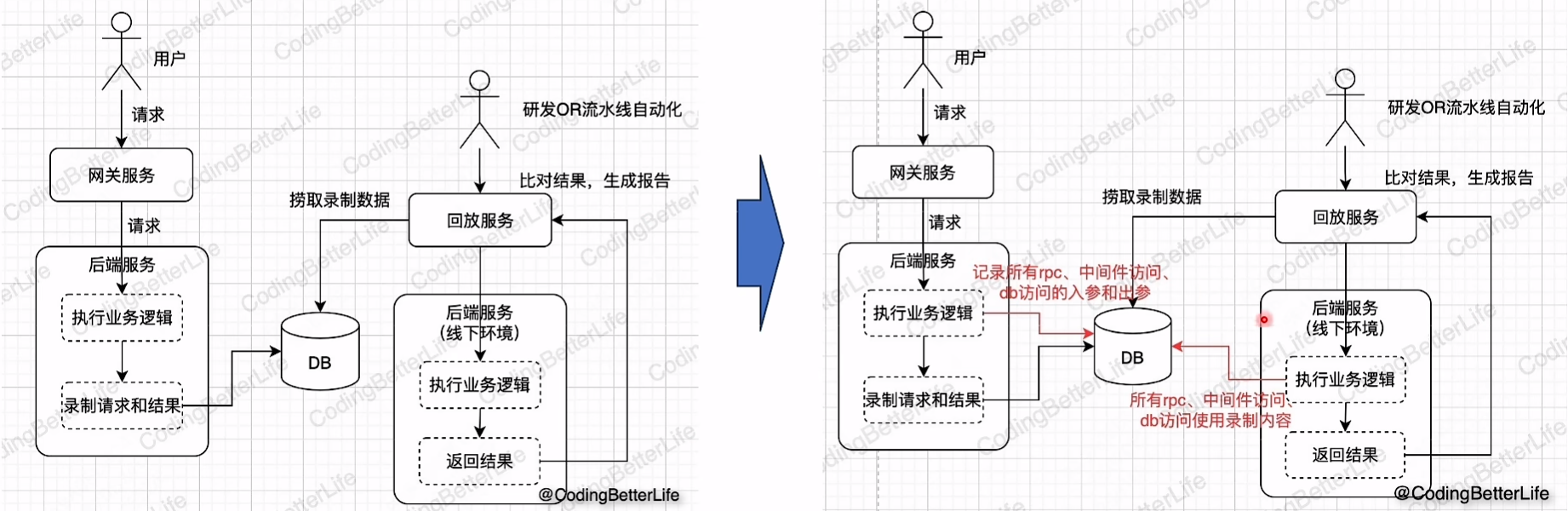
线下环境流量回放
- 将请求、RPC、中间件、DB都录制(框架实现线上录制功能,如果让你设计这个框架,如何实现?)
- 回放时全部mock掉
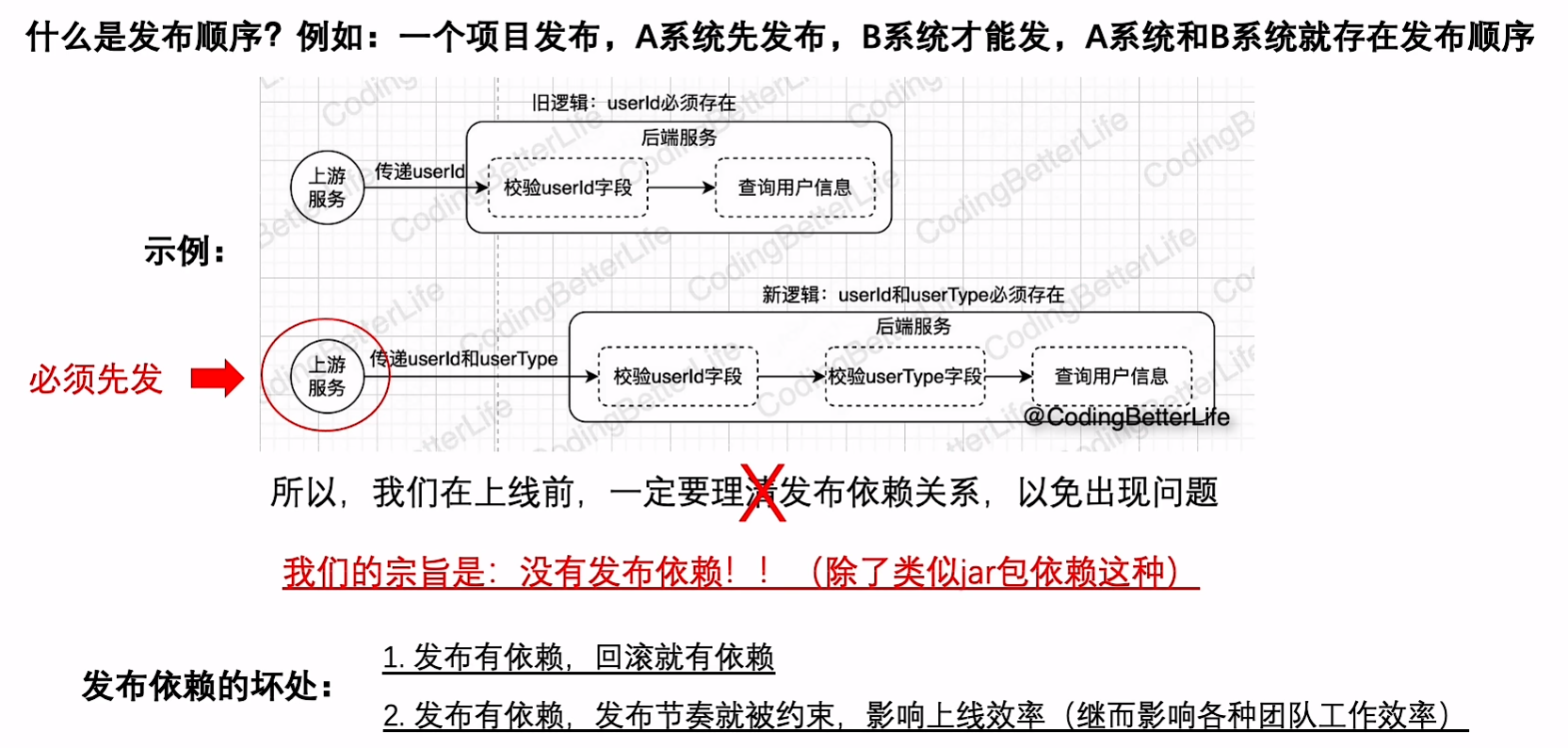
发布顺序
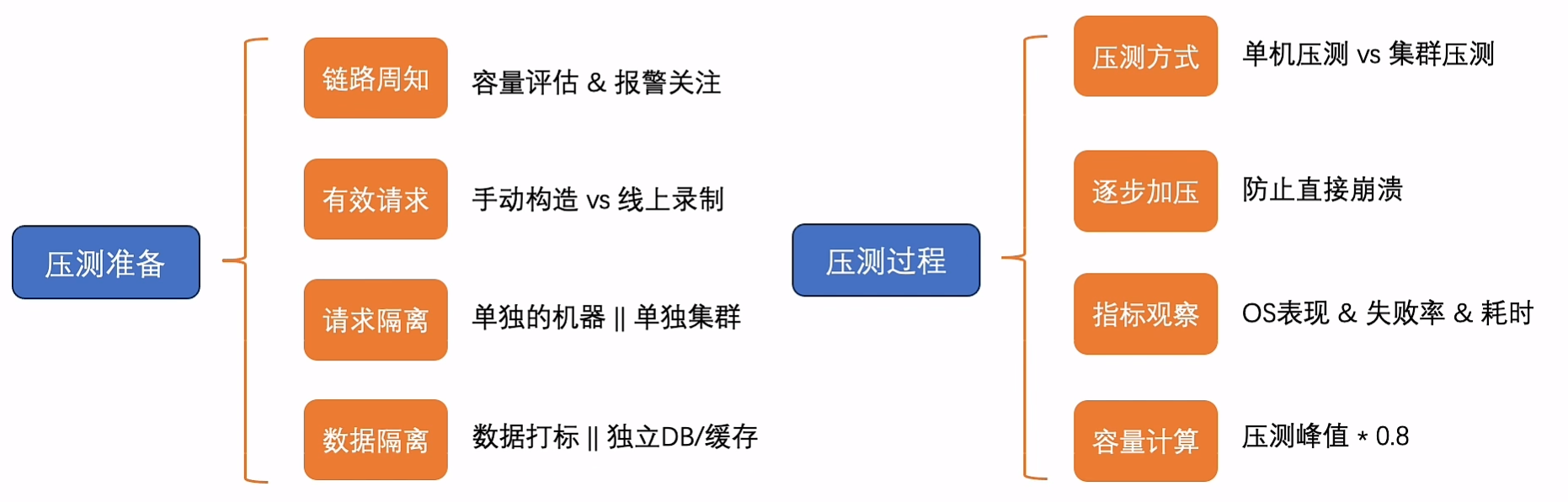
容量评估(压测)
唯一方法:压测
可监控
埋点、日志、异常、机器指标、成功率、RT
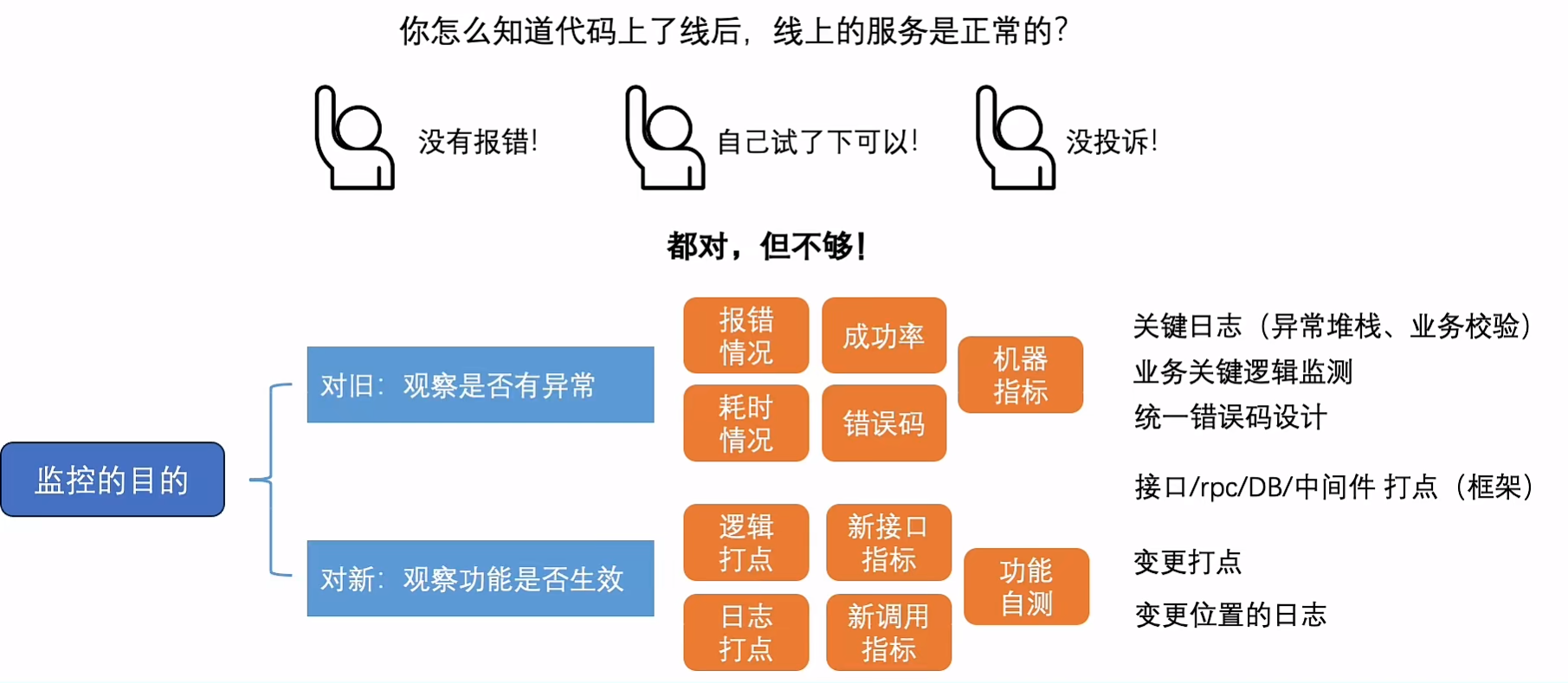
可灰度
变更逐步生效
实现灰度:用户ID后两位

陷阱
开关变量实现灰度,多次请求中途变更了开关
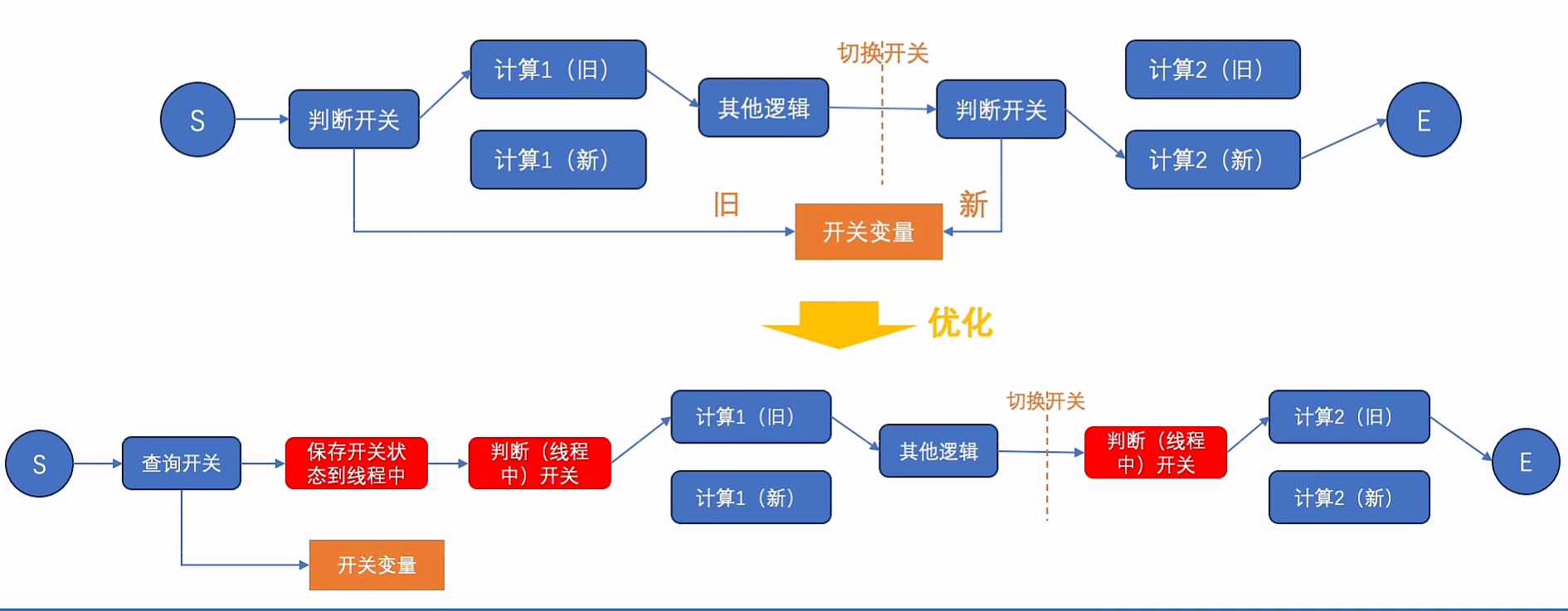
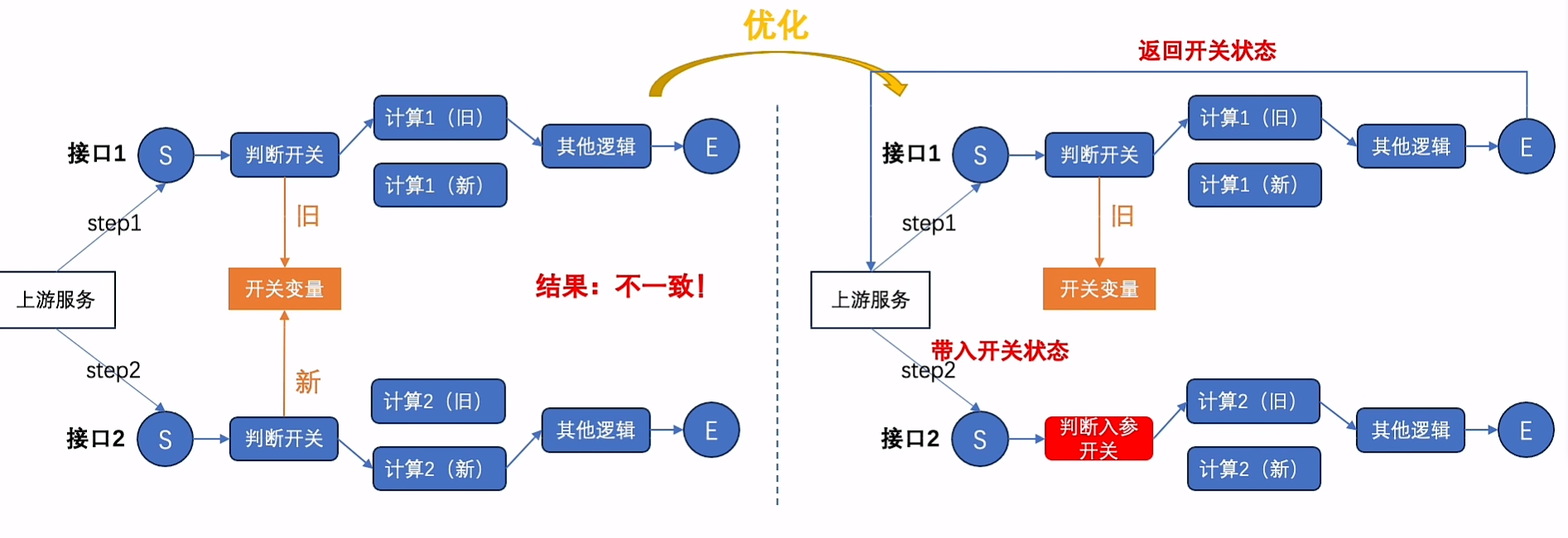
可回滚
回滚不难,如何快速回滚,并且有时候存在新数据了,旧代码是否能够兼容或者数据回滚
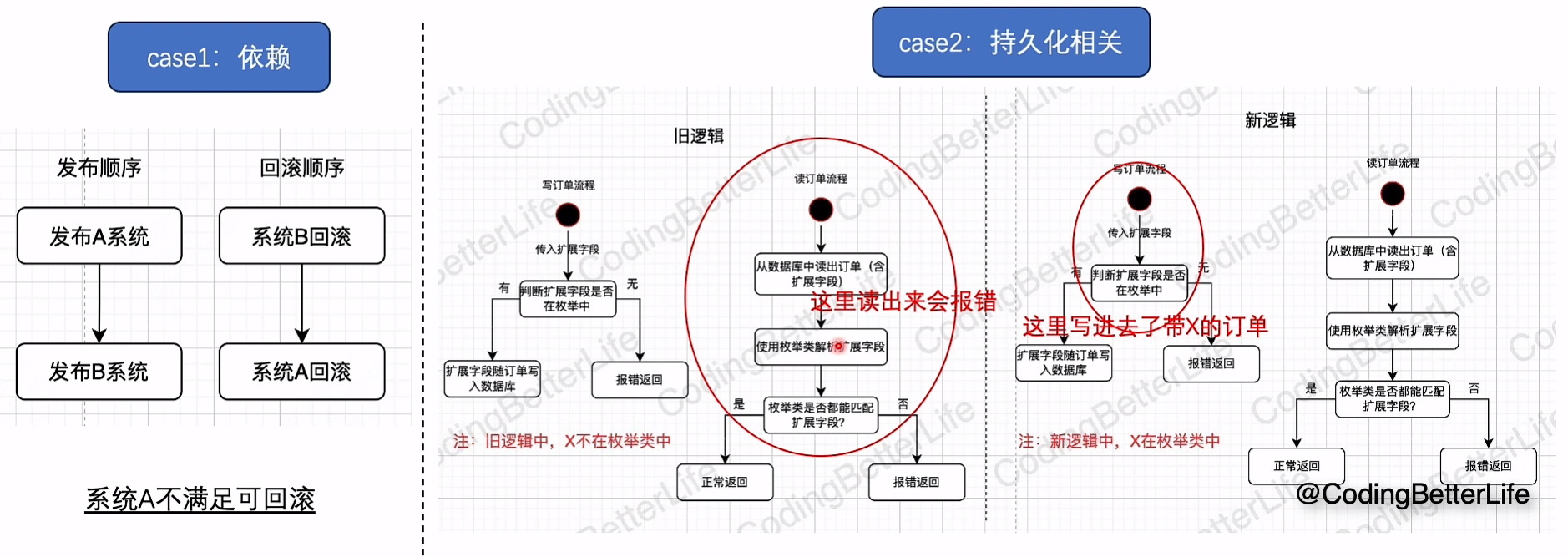
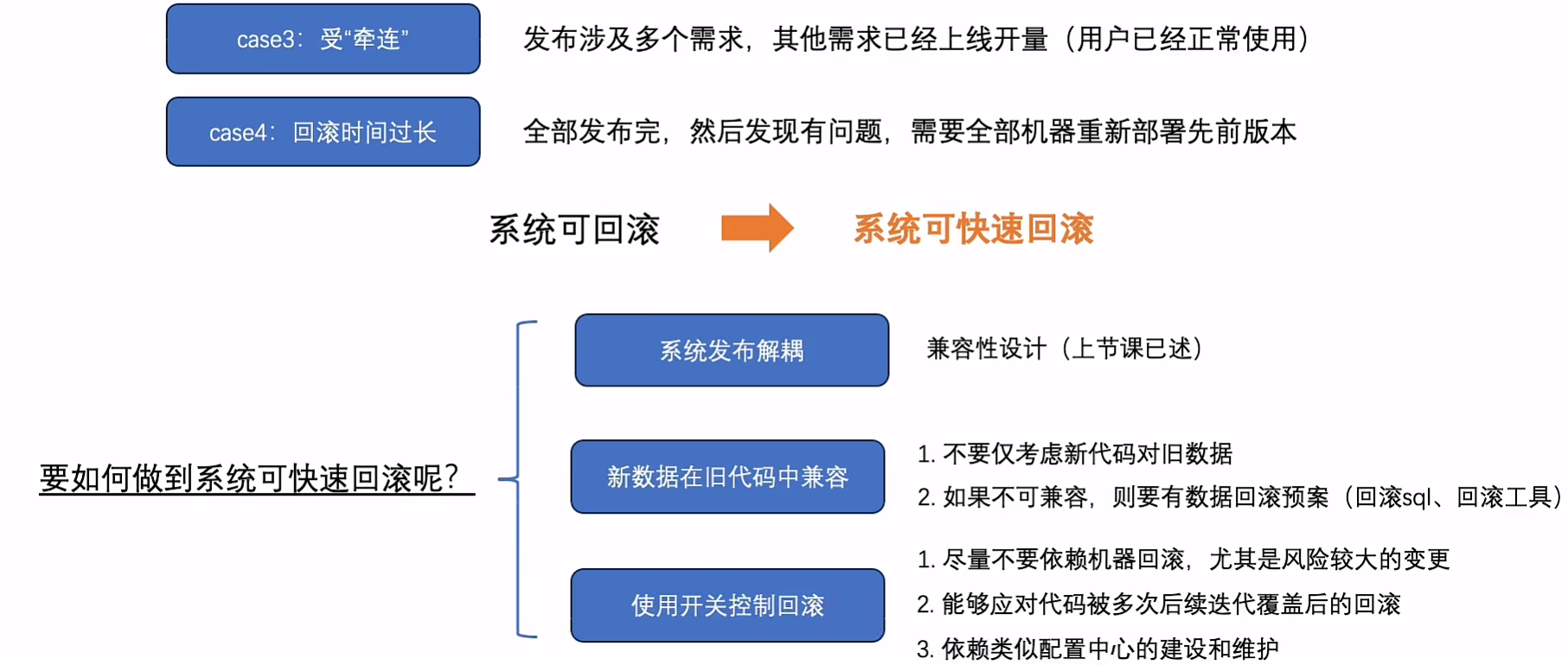
13.稳定性之运行时
跑着跑着出错了;真正故障时能做的事情很少,重点需要前期准备好
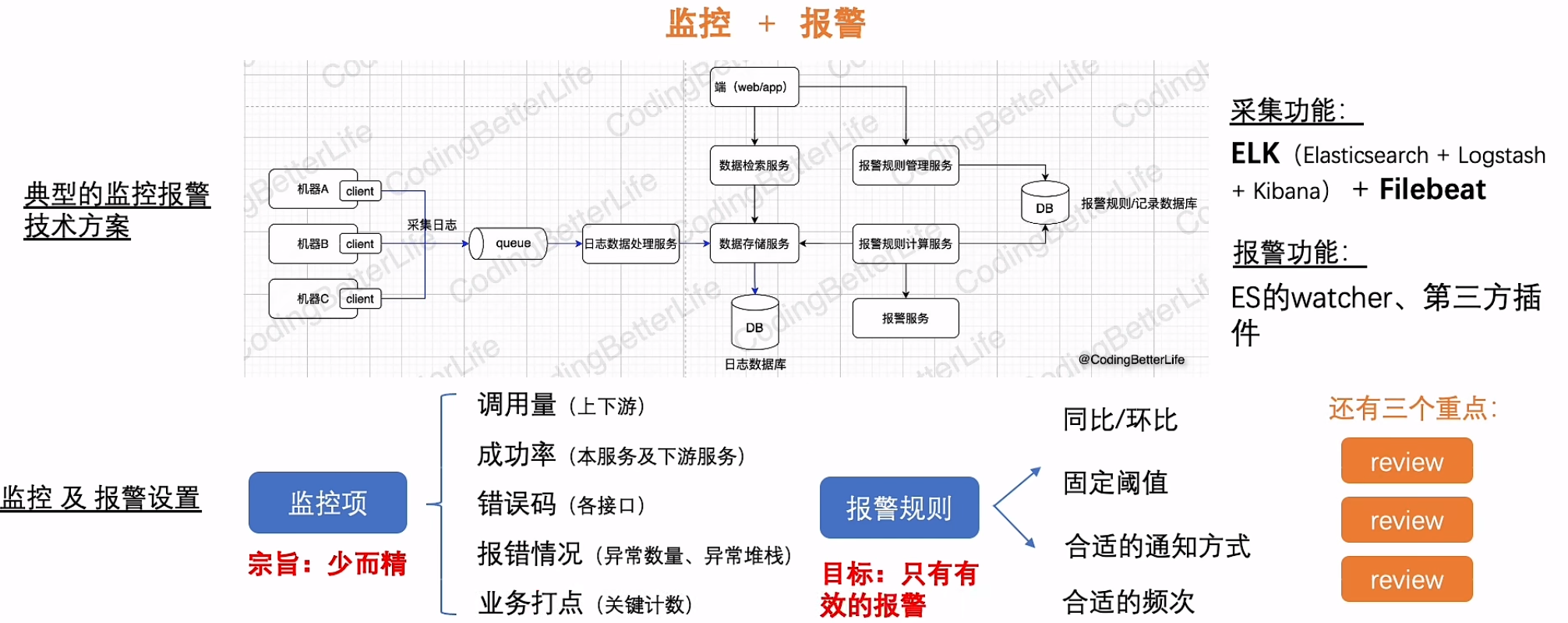
监控+报警
包含日志的采集 & 报警
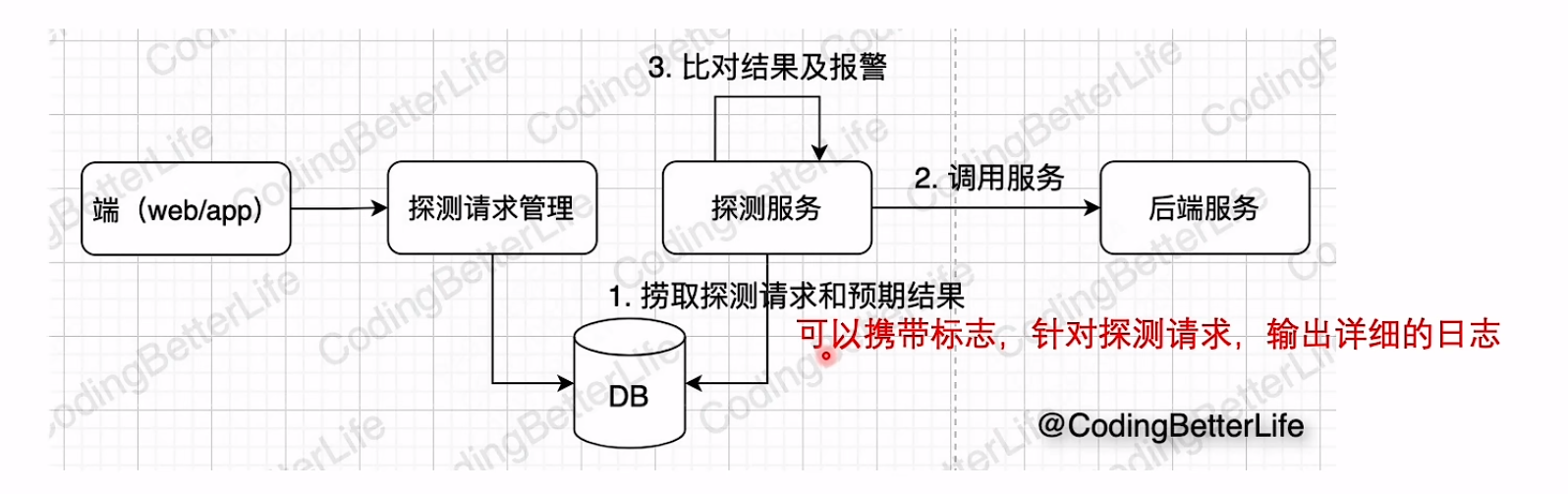
主动探测
主动模拟请求,周期性执行
对账系统
美团配送资金安全治理之对账体系建设 - 美团技术团队 (meituan.com)
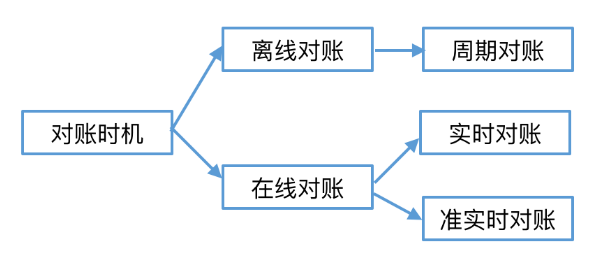
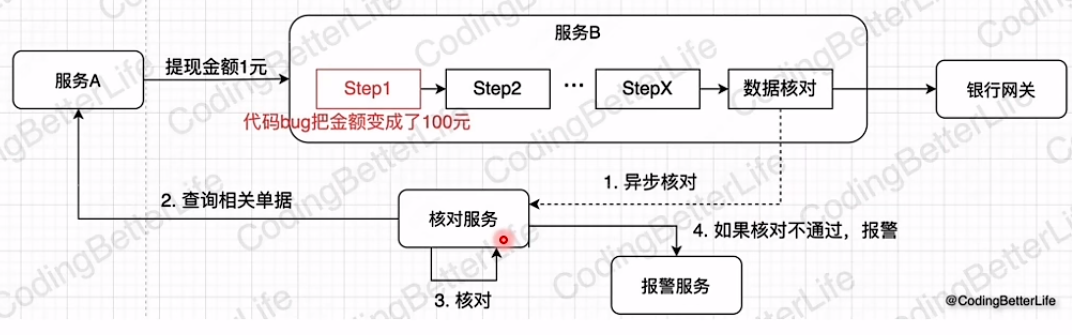
实时
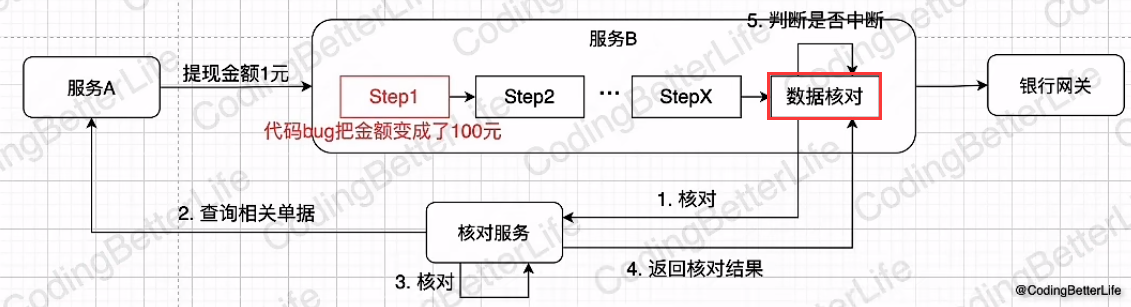
准实时
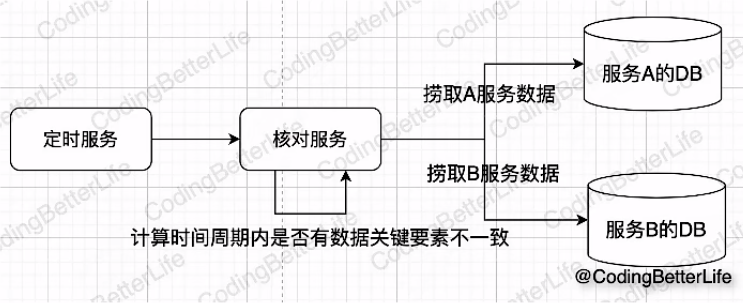
离线
定时拉取数据并做校验
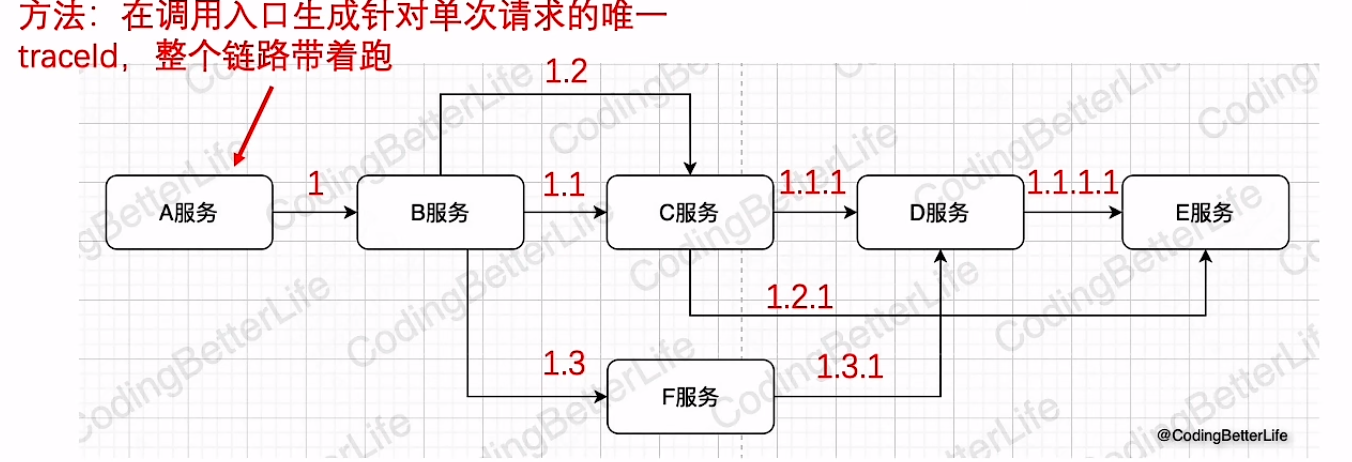
分布式trance
还原链路的调用关系
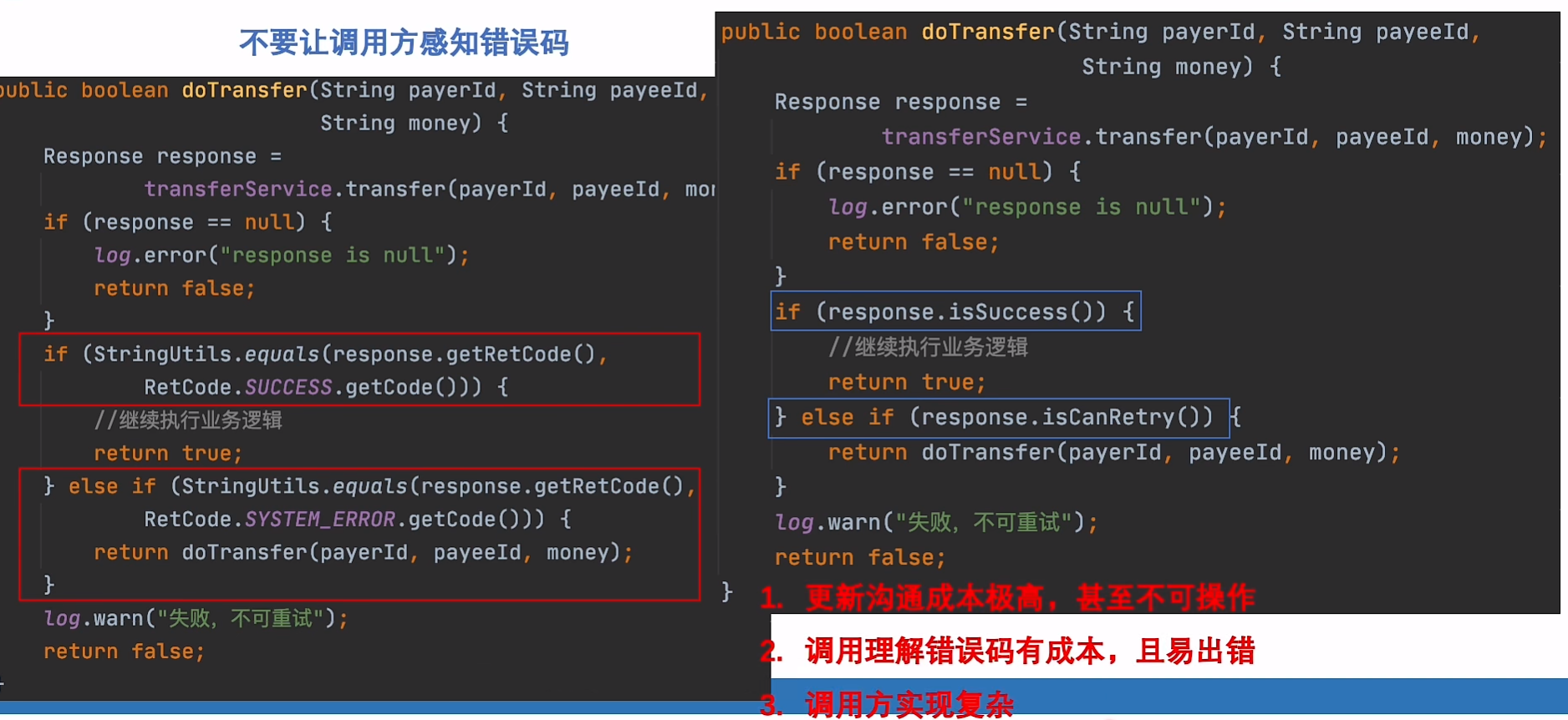
14.错误处理显真功(细节)
某些因素导致流程没有按照预期执行完成
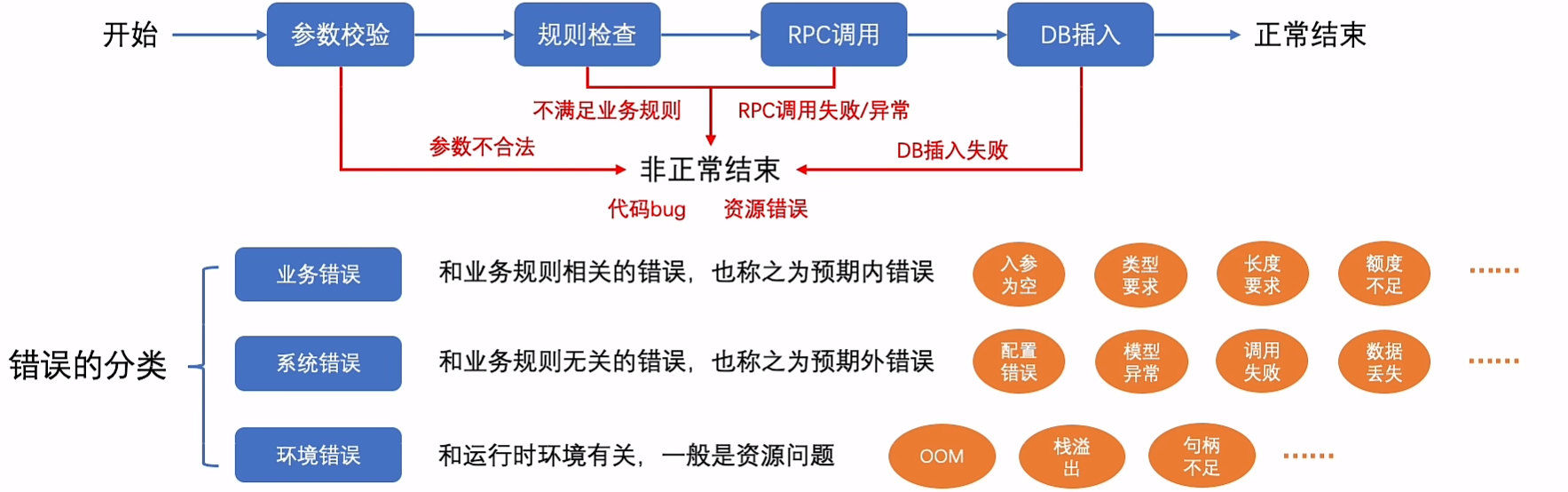
引入
- 入参校验(电话、金额)
- 中间用户信息结果判断
- 业务返回判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| public TransferResponse transfer(Transferparam transferparam) {
UserInfoResult payerUserInfoResult = userInfoService.queryUserInfo(transferParam.getPayerPhoneNo());
UserInfoResult payeeUserInfoResult = userInfoService.queryUserInfo(transferParam.getPayeePhoneNo());
TransferRequest transferRequest = TransferRequest.builder()
.payerId(payerUserInfoResult.getData().getUserId())
.payeeId(payeeUserInfoResult.getData().getUserId())
.money(transferParam.getMoney())
.build();
transferService.transfer(transferRequest);
quatoService.recordQuato(payerUserInfoResult.getData().getUserId(), transferParam.getMoney());
return TransferResponse.builder().retCode(SUCCESS_CODE).build();
}
public TransferResponse transfer(Transferparam transferparam) {
String payerPhoneNo = transferParam.getPayerPhoneNo();
String payeePhoneNo = transferParam.getPayeePhoneNo();
BigDecimal money = transferParam.getMoney();
if (!isValidPhoneNo(payerPhoneNo) || !isValidPhoneNo(payeePhoneNo)) {
throw new IllegalArgumentException("Invalid phone number");
}
if (money == null || money.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("Invalid transfer amount");
}
UserInfoResult payerUserInfoResult = userInfoService.queryUserInfo(payerPhoneNo);
UserInfoResult payeeUserInfoResult = userInfoService.queryUserInfo(payeePhoneNo);
if (payerUserInfoResult == null || payerUserInfoResult.getData() == null || payeeUserInfoResult == null || payeeUserInfoResult.getData() == null) {
throw new IllegalArgumentException("Invalid user information");
}
TransferRequest transferRequest = TransferRequest.builder()
.payerId(payerUserInfoResult.getData().getUserId())
.payeeId(payeeUserInfoResult.getData().getUserId())
.money(money)
.build();
boolean transferResult = transferService.transfer(transferRequest);
if (!transferResult) {
throw new RuntimeException("Transfer failed");
}
boolean recordResult = quatoService.recordQuato(payerUserInfoResult.getData().getUserId(), money);
if (!recordResult) {
throw new RuntimeException("Failed to record quota");
}
return TransferResponse.builder().retCode(SUCCESS_CODE).build();
}
|
错误处理方式
- 返回错误码 可以包含更加复杂的信息;无性能损耗
- 抛出异常 写起来简单 (目前主流rpc都支持异常传递)
- 都无法用于异步场景!
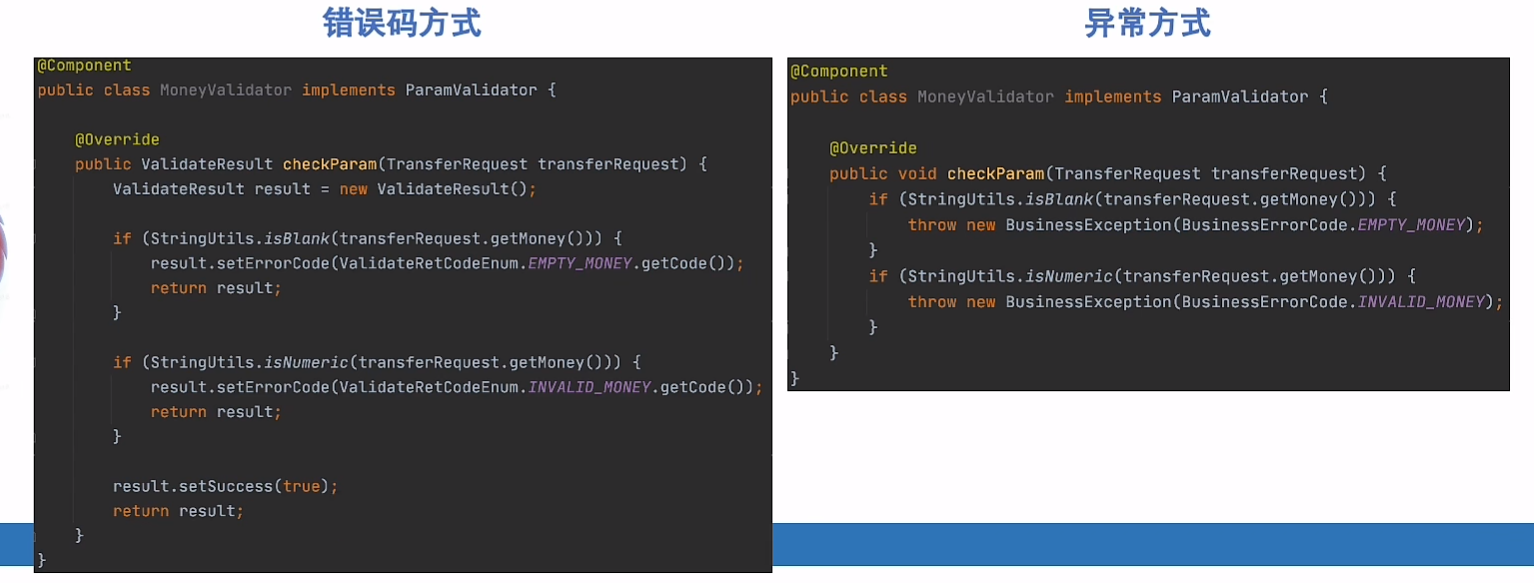
推荐:系统内使用中断,PRC接口交互错误码
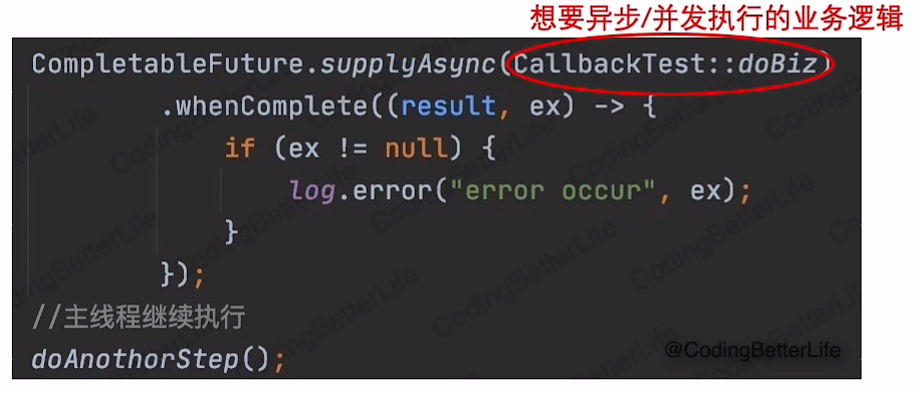
异步异常
错误码设计
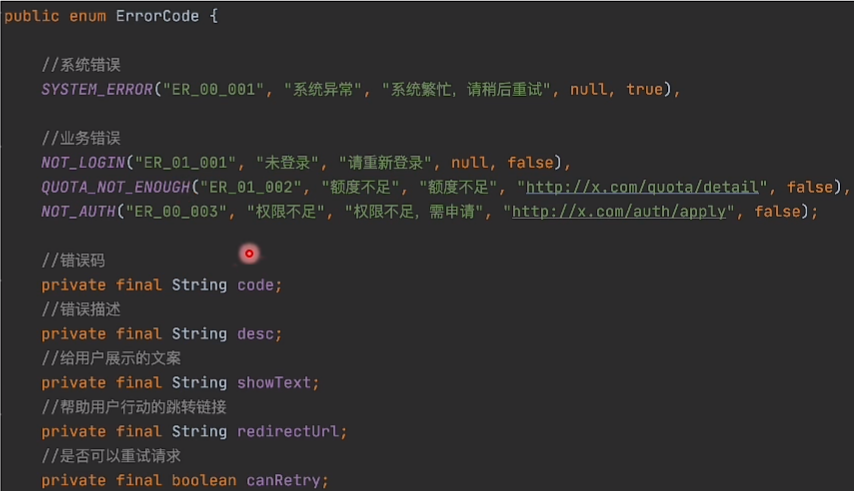
这里是代码写死,也可也配置中心配置
异常设计方式
CommonException+枚举
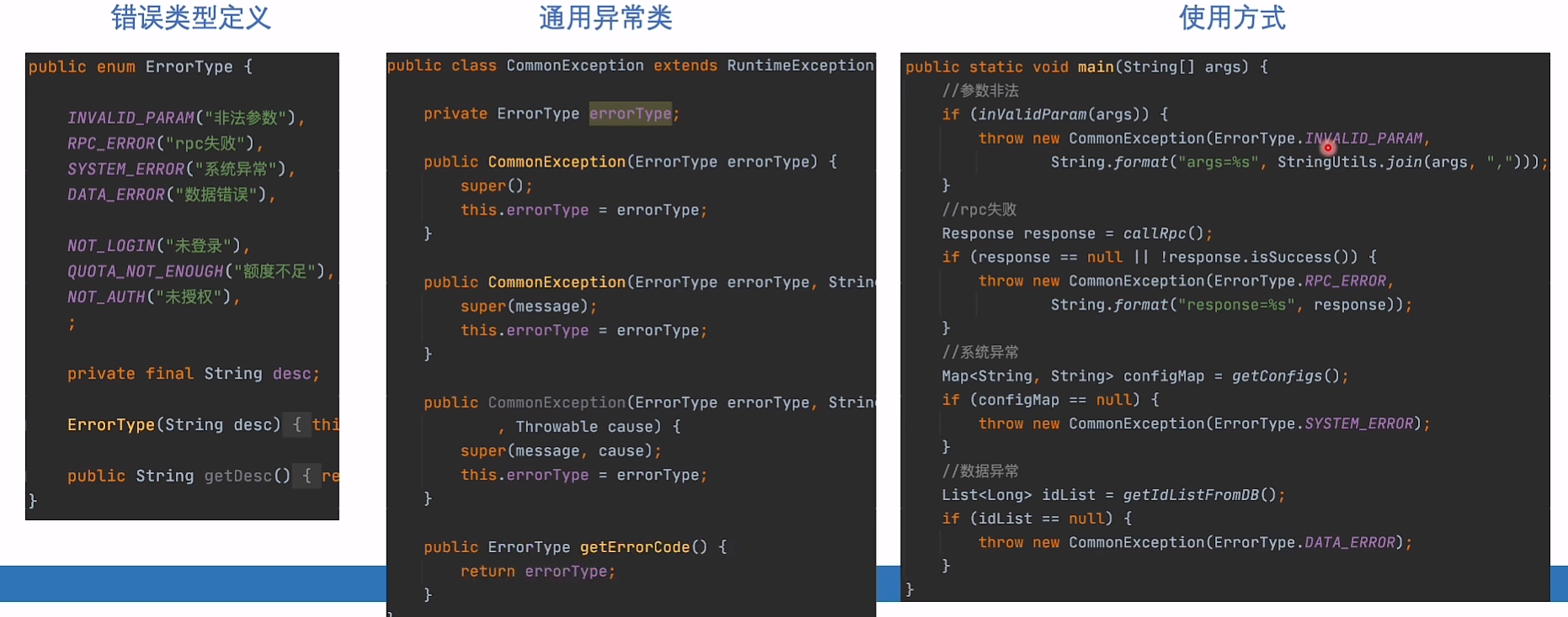
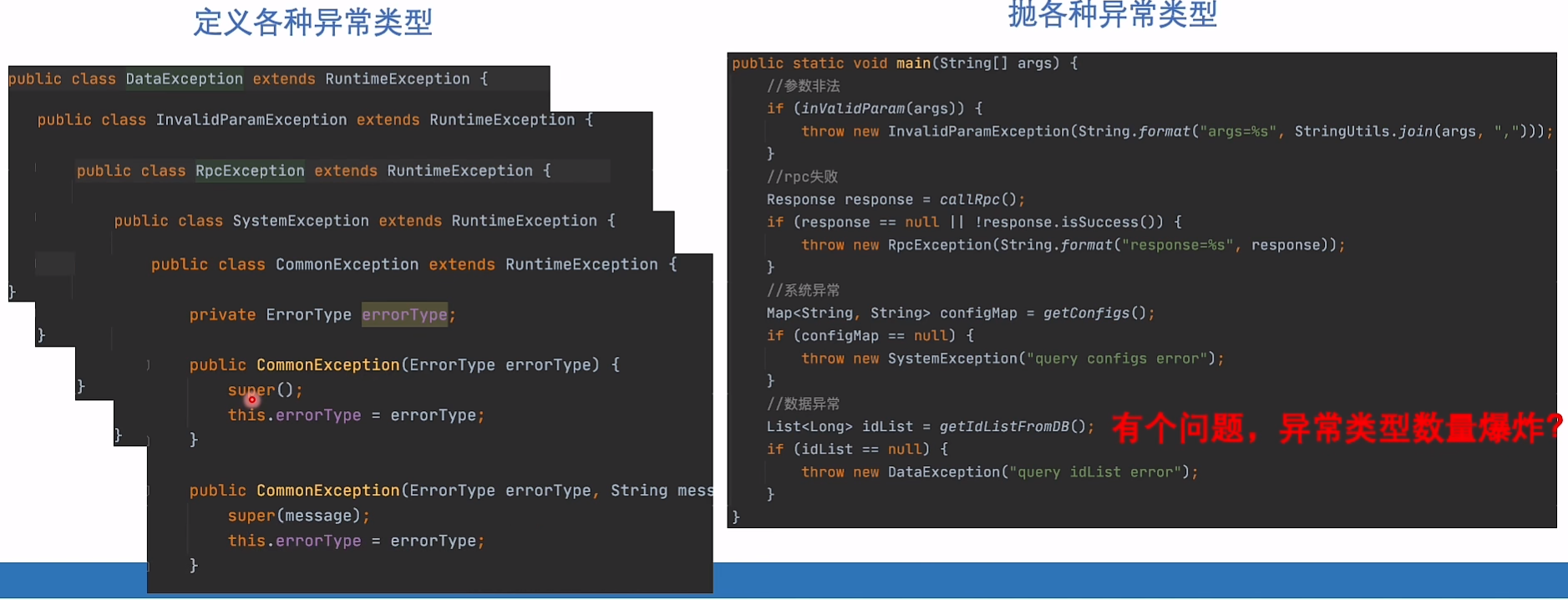
各种不同异常+上面:可以通过异常类型进行不同处理(降级等)
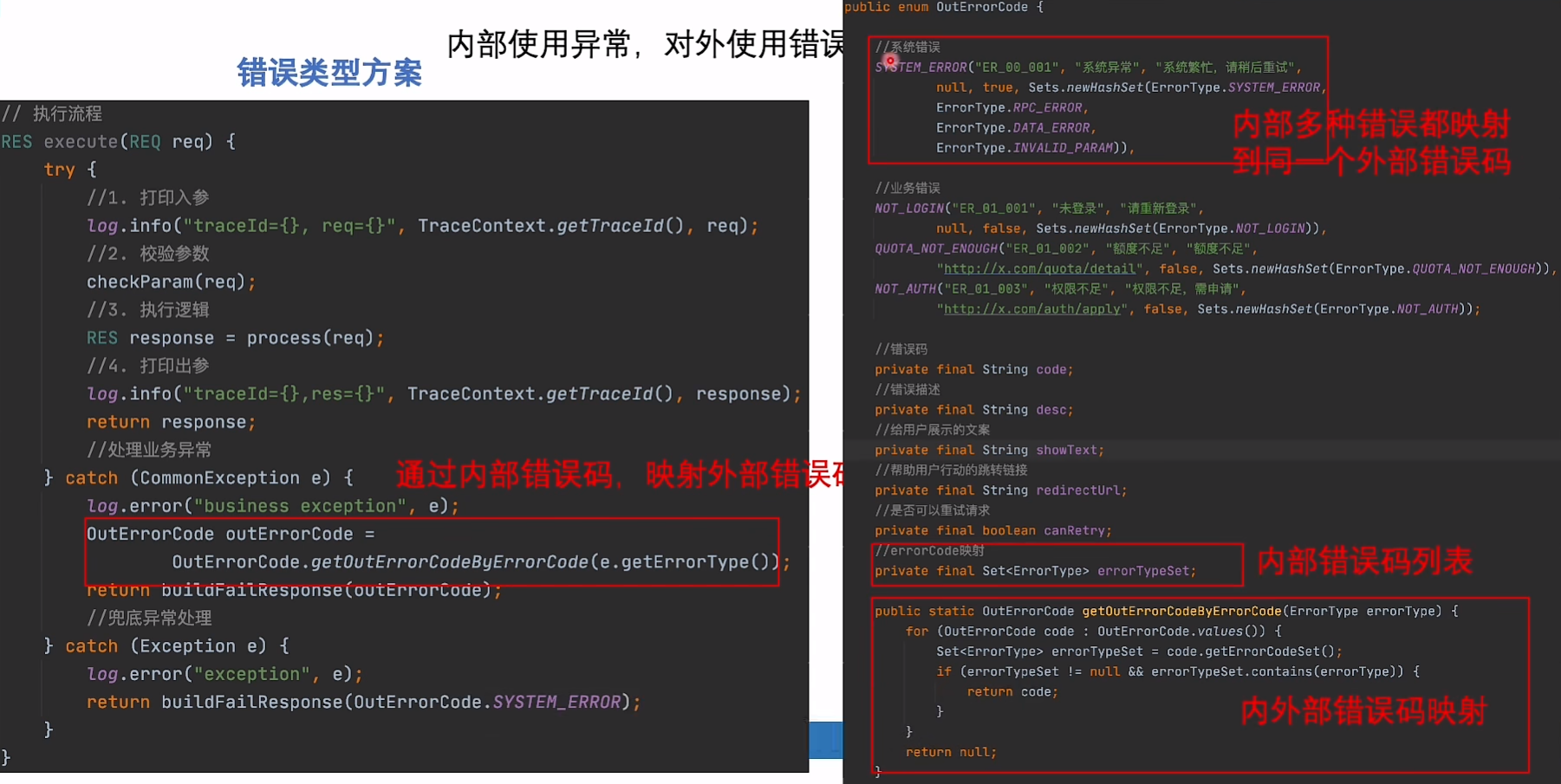
异常映射错误码
由于内部是使用异常,返回给上游是状态码,最后需要catch将异常转换为外部状态码
15.打日志是技术活
打日志
16.技术文档
目的:
- 确保方案可行
- 提早识别风险
- 对齐系统修改
- 评估工时投入
金币提现场景
https://www.yuque.com/codingbetterlife/lession/pka2nhb3yqoiqbhl?singleDoc
密码:wsg3
功能描述
功能点:用户提现金币到银行卡,有每天的限额
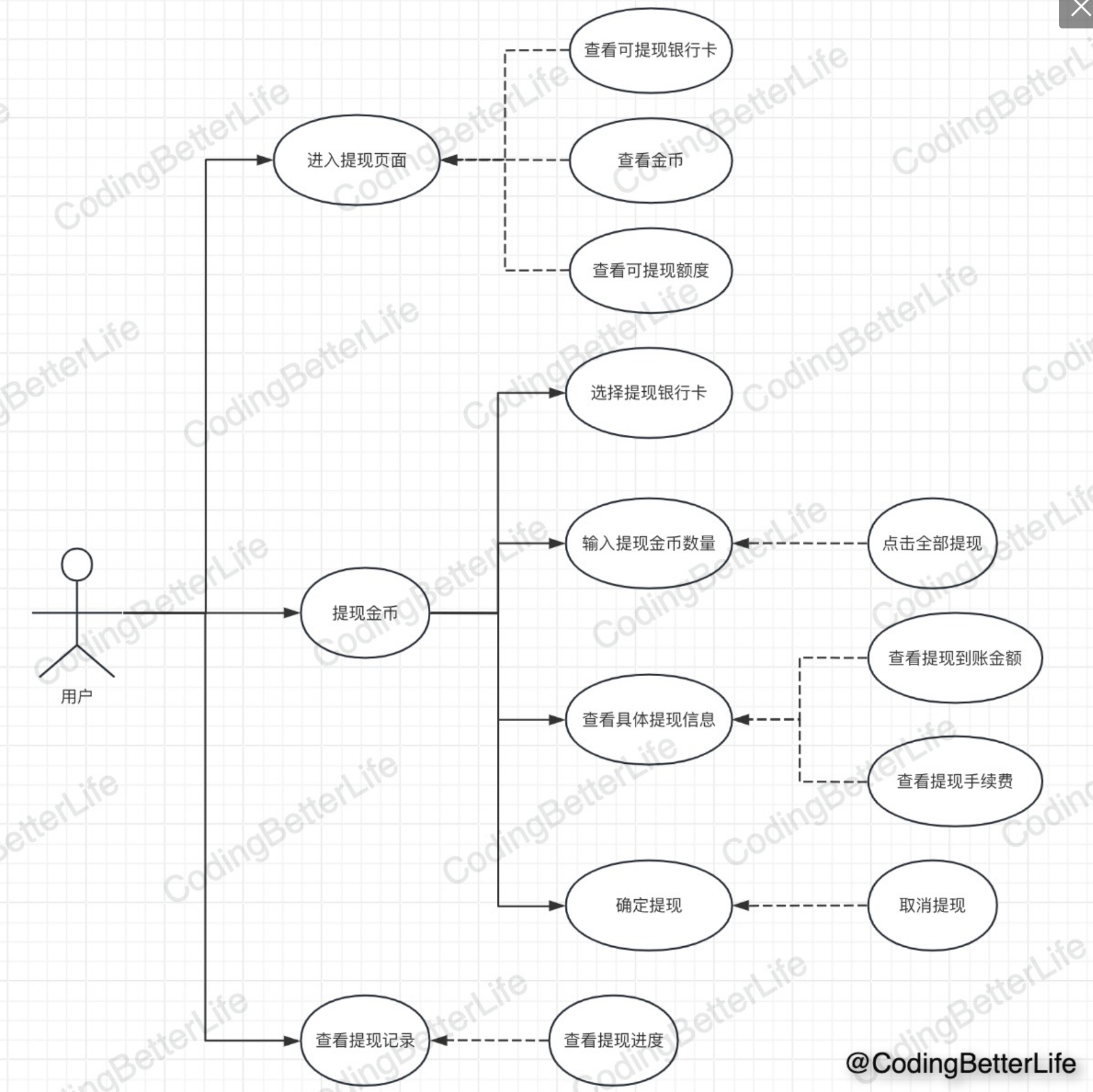
- 页面展示:总金币、可提现金币、额度、银行卡
- 准备提现:输入金额,并调取后端查询收费
- 确认提现:扣减金币到银行卡
核心流程
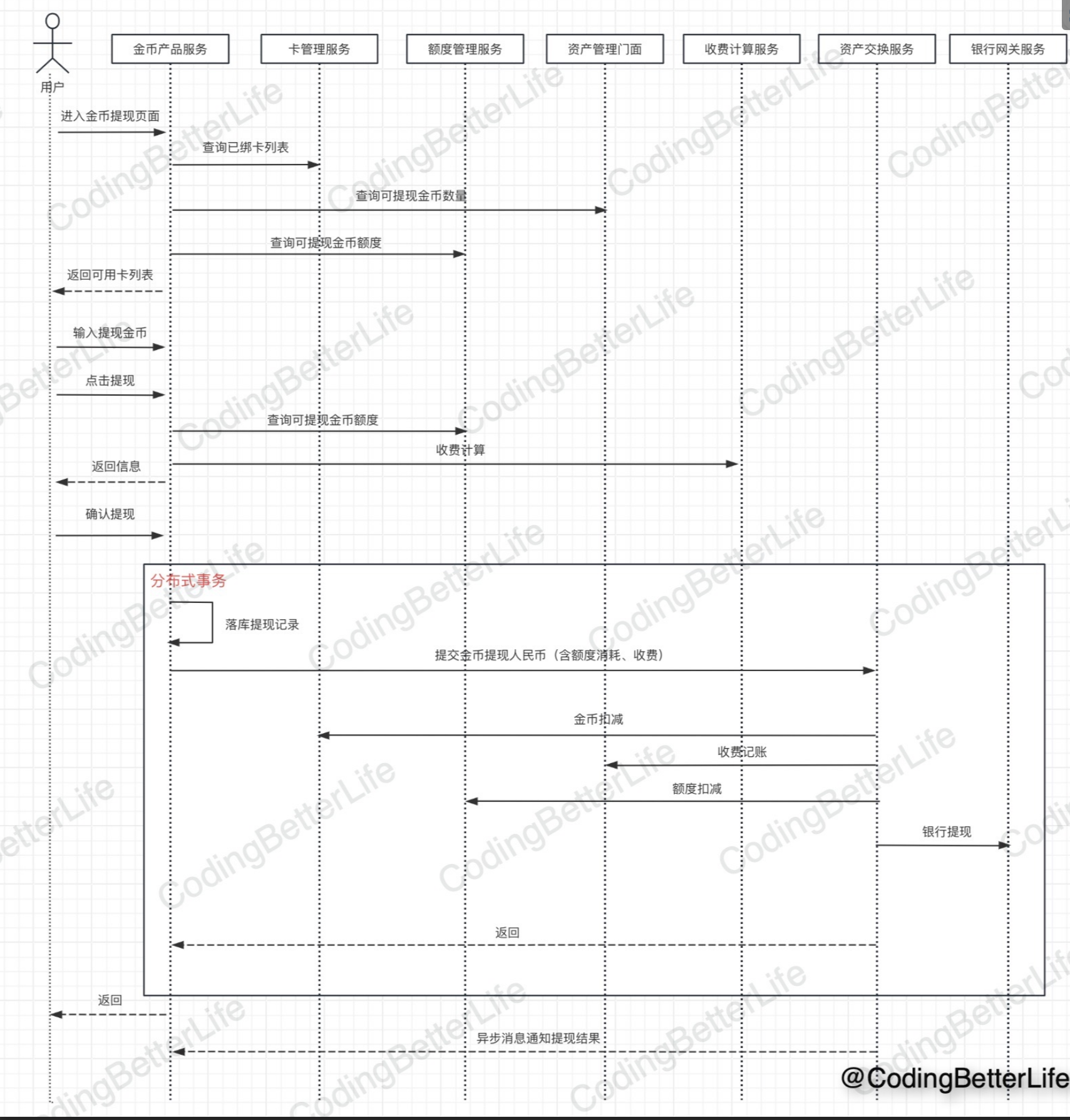
其中具体的每一个具体服务使用流程引擎实现