GPT摘要
这篇文章主要讲解了以下内容: 1. 内核态切换到用户态 :通过 move_to_user_mode 函数从内核态切换到用户态,利用中断返回机制模拟切换过程,确保代码在用户态下运行。 2. 进程创建(fork) :通过 fork 系统调用创建新进程: - find_empty_process 找到空闲的进程槽位。 - copy_process 复制当前进程的上下文(task_struct)、内存管理信息(页表、段表)以及寄存器状态。 - 新进程与父进程共享相同的物理内存,但通过写时复制(Copy-On-Write)机制确保修改时分配新内存。 3. 进程调度机制 : - 时间片轮转 :每个进程有一个时间片计数器(counter),时钟中断(10ms一次)减少计数器,归零时触发调度。 - 优先级调度 :进程的初始时间片由优先级(priority)决定,空闲时重新分配时间片。 - 任务状态 :进程可以是运行(TASK_RUNNING)、不可中断(TASK_UNINTERRUPTIBLE)等状态,确保合理调度。 4. 内存管理 : - 段式管理 :每个进程通过 LDT(局部描述符表)映射到独立的线性地址空间。 - 页式管理 :通过页表将线性地址映射到物理地址,fork 时复制父进程页表,但设置为只读以实现写时复制。 - 缺页中断 :写操作触发缺页中断,处理程序 do_wp_page 分配新物理页并更新页表。 5. 系统调用与中断 : - int 0x80 :用户态通过软中断进入内核,由 sys_call_table 根据 eax 调用处理函数(如 sys_fork)。 - 中断上下文切换 :保存寄存器状态并通过 TSS(任务状态段)恢复新进程的上下文。 总结 :文章详细描述了进程创建(fork)的完整流程,包括权限切换、内存复制、调度策略以及写时复制的实现机制,展示了操作系统如何管理多进程的并发执行和内存隔离。
引入 第一部分和第二部分,为我们这个第三部分做了充足的铺垫工作。
第一部分 进入内核前的苦力活
第二部分 大战前期的初始化工作
到了第三部分,简单说就是从内核态切换到用户态,然后通过 fork 创建出一个新的进程,再之后老进程进入死循环。
1 2 3 4 5 6 7 8 9 10 11 12 void main (void ) {if (!fork()) {for (;;) pause();
move_to_user_mode : 转为用户态,之后需要通过中断转为内核态fork :从进程0创建进程1init : 进程1加载根文件系统任务,创建进程2,进程2加载shellpause :暂停
move_to_user_mode
特权级的实现
首先从一个最大的视角来看,这一切都源于 CPU 的保护机制。CPU 为了配合操作系统完成保护机制这一特性,分别设计了分段保护机制 与分页保护机制 。
当我们在 第七回 | 六行代码就进入了保护模式 将 cr0 寄存器的 PE 位开启时,就开启了保护模式,也即开启了分段保护机制 。
如何保护的?
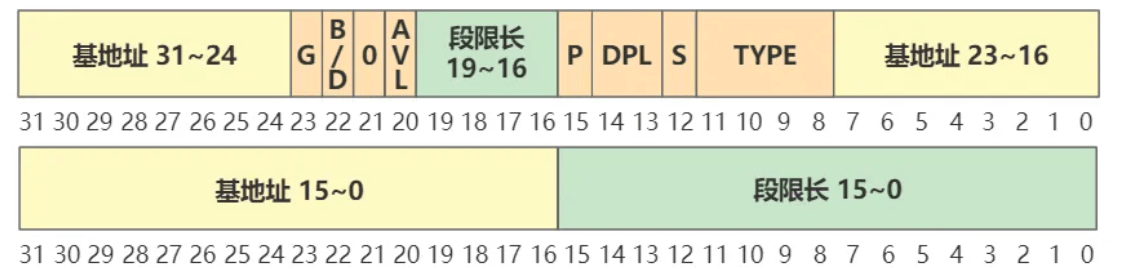
cs代码段选择子的最后几位
CPL代表当前的特权级别:11代表用户态
代码的跳转执行jmp时,yyy : xxx,这里的 yyy 就是q请求跳转的段选择子
在GDT中保存了yyy 的段描述符,其中定义了DPL指明了目标代码段特权级
在代码跳转时:CPL 必须等于DPL
在内存数据访问时:处于内核态的代码可以访问任何特权级的数据段,处于用户态的代码则只可以访问用户态的数据段
发送中断时,指向新的CS IP,CS中的CPL通常是0
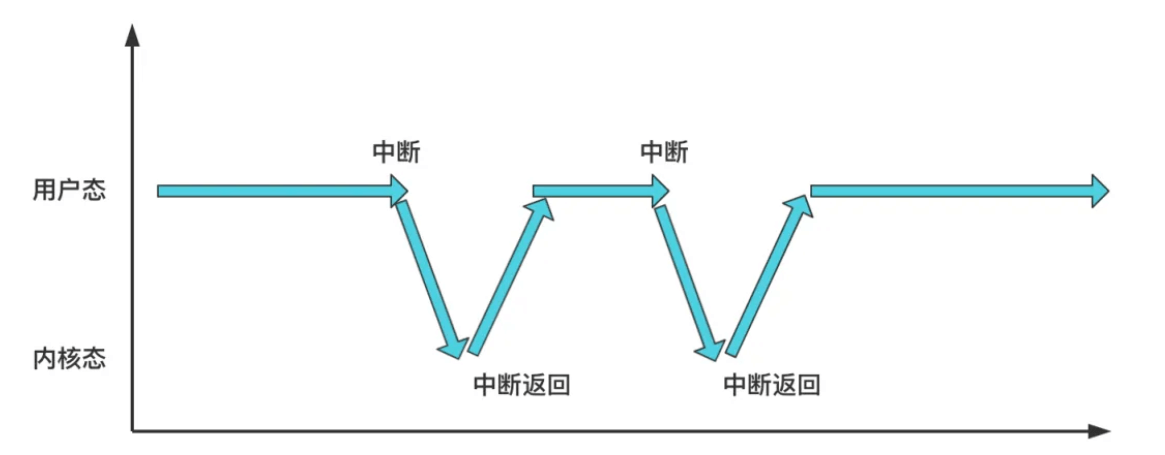
转化方式 中断和中断返回:int 0x80
没有中断也可也返回?
中断前通常会保存当前的cs ip,并在return时pop,所以这里我们return前先push,假装发生了中断,push的cs ip就是等下想去的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void main(void) {
注意SS、CS最后两位为1,代表切换到用户态
从LDT 拿转换关系:倒数第三位 TI 表示从 GDT 还是 LDT 中取,1 表示 LDT,也就是从局部描述符表中取。局部描述符具体是哪一个?也就是lldt 指向的是谁?
在 第18回 | 大名鼎鼎的进程调度就是从这里开始的 中,将 0 号 LDT 作为当前的 LDT 索引,记录在了 CPU 的 lldt 寄存器中。
1 2 3 4 5 6 7 #define lldt(n) __asm__("lldt %%ax" ::"a" (_LDT(n))) void sched_init (void ) {0 );
总结
特权的区别通过cs中的CPL和段描述符中的DPL定义,跳转时需要检查,使得用户下的代码和数据和内核下的区分开来
什么时候特权会转变:中断以及中断返回时
1 2 3 4 5 6 7 8 void main (void ) {if (!fork()) {for (;;) pause();
上一节中,成功切换到了用户态,现在我们先不考虑fork,先讲讲如何实现进程调度?
如何实现cpu一下运行这个线程,一下另外一个?
由一个不受任何程序控制的,第三方的不可抗力,每隔一段时间就中断一下 CPU 的运行,然后跳转到一个特殊的程序那里,这个程序通过某种方式获取到 CPU 下一个要运行的程序的地址,然后跳转过去。
这个每隔一段时间就中断 CPU 的不可抗力,就是由定时器触发的时钟中断 。
当前线程被换下去后,肯定需要保存当前任务的现场,比如它上一次执行到哪里了,要不 CPU 就算决定好了要跳转到你这个进程上运行,具体跳到哪一行运行,总得有个地方存吧?
1 2 3 struct task_struct {
上下文 每个程序最终的本质就是执行指令。这个过程会涉及寄存器 ,内存 和外设端口 。
内存还有可能设计成相互错开的,互不干扰,比如进程 1 你就用 01K 的内存空间,进程 2 就用 1K2K 的内存空间,咱谁也别影响谁。
但寄存器只有那么多,如果当前线程切换掉了,切换前就要存储下来,否者就别别人删了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct task_struct {struct tss_struct tss ;struct tss_struct {long back_link; long esp0;long ss0; long esp1;long ss1; long esp2;long ss2; long cr3;long eip;long eflags;long eax,ecx,edx,ebx;long esp;long ebp;long esi;long edi;long es; long cs; long ss; long ds; long fs; long gs; long ldt; long trace_bitmap; struct i387_struct i387 ;
cr3 : cr3 寄存器是指向页目录表首地址的,每一个进程不同,说明了线性地址到物理地址的映射关系不同。当前进程来了,就把当前进程的cr3设置上,代表当前线程在运行
操作系统来复制建立不同的页目录表 并替换 cr3 寄存器即可,可以实现内存的不冲突或者共享
什么时候切换 每次时钟都切换?太频繁了
给进程一个属性,叫剩余时间片 ,每次时钟中断来了之后都 -1 ,如果减到 0 了,就触发切换进程的操作。
1 2 3 4 5 6 struct task_struct {long counter;struct tss_struct tss ;
每次中断都–,并检查一下
1 2 3 4 5 6 7 void do_timer (long cpl) {if ((--current->counter)>0 ) return ;
优先级 如何区分进程的优先级,其实就是counter的初始值,用一个priority保存
1 2 3 4 5 6 7 struct task_struct {long counter;long priority;struct tss_struct tss ;
进程状态 刚才的进程是都要运行的,有没有不在运行的情况?
一个进程读取磁盘,需要阻塞好久,这个时候调度cpu给他也没用,就需要主动放弃CPU执行权力 ,用state 记录下进程的状态。
1 2 3 4 5 6 7 8 9 10 11 12 struct task_struct {long state;long counter;long priority;struct tss_struct tss ;#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define TASK_ZOMBIE 3 #define TASK_STOPPED 4
现在就可以完成简单的任务了:表示状态的 state ,表示剩余时间片的 counter ,表示优先级的 priority ,和表示上下文信息的 tss 。
小结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct task_struct {long state; long counter;long priority;long signal;struct sigaction sigaction [32];long blocked; int exit_code;unsigned long start_code,end_code,end_data,brk,start_stack;long pid,father,pgrp,session,leader;unsigned short uid,euid,suid;unsigned short gid,egid,sgid;long alarm;long utime,stime,cutime,cstime,start_time;unsigned short used_math;int tty; unsigned short umask;struct m_inode * pwd ;struct m_inode * root ;struct m_inode * executable ;unsigned long close_on_exec;struct file * filp [NR_OPEN ];struct desc_struct ldt [3];struct tss_struct tss ;
进程调度的开始,要从一次定时器滴答来触发,通过时钟中断处理函数走到进程调度函数,然后去进程的结构 task_struct 中取出所需的数据,进行策略计算,并挑选出下一个可以得到 CPU 运行的进程,跳转过去。
上回我们说了进程调度需要的数据结构,现在我们来看下具体的调度过程
还记得我们在 第18回 | 大名鼎鼎的进程调度就是从这里开始的 sched_init 的时候,开启了定时器 吧?这个定时器每隔一段时间就会向 CPU 发起一个中断信号。
这个间隔时间被设置为 10 ms,也就是 100 Hz。
1 2 3 schedule.c#define HZ 100
发起的中断叫时钟中断 ,其中断向量号被设置为了 0x20 。
同时我们在 sched_init 里设置的时钟中断和对应的中断处理函数吧?
1 2 3 4 5 6 7 8 9 10 11 12 13 schedule.cset_intr_gate (0x20 , &timer_interrupt) ;
1 2 3 4 5 6 7 void do_timer (long cpl) {if ((--current->counter)>0 ) return ;
schedule 找出剩余时间片最大的线程(state=TASK_RUNNING ),如果都没有时间就counter = counter/2 + priority
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void schedule (void ) {int i, next, c;struct task_struct ** p ;while (1 ) {-1 ;0 ;while (--i) {if (!*--p)continue ;if ((*p)->state == TASK_RUNNING && (*p)->counter > c)if (c) break ;for (p = &LAST_TASK ; p > &FIRST_TASK ; --p)if (*p)1 ) +
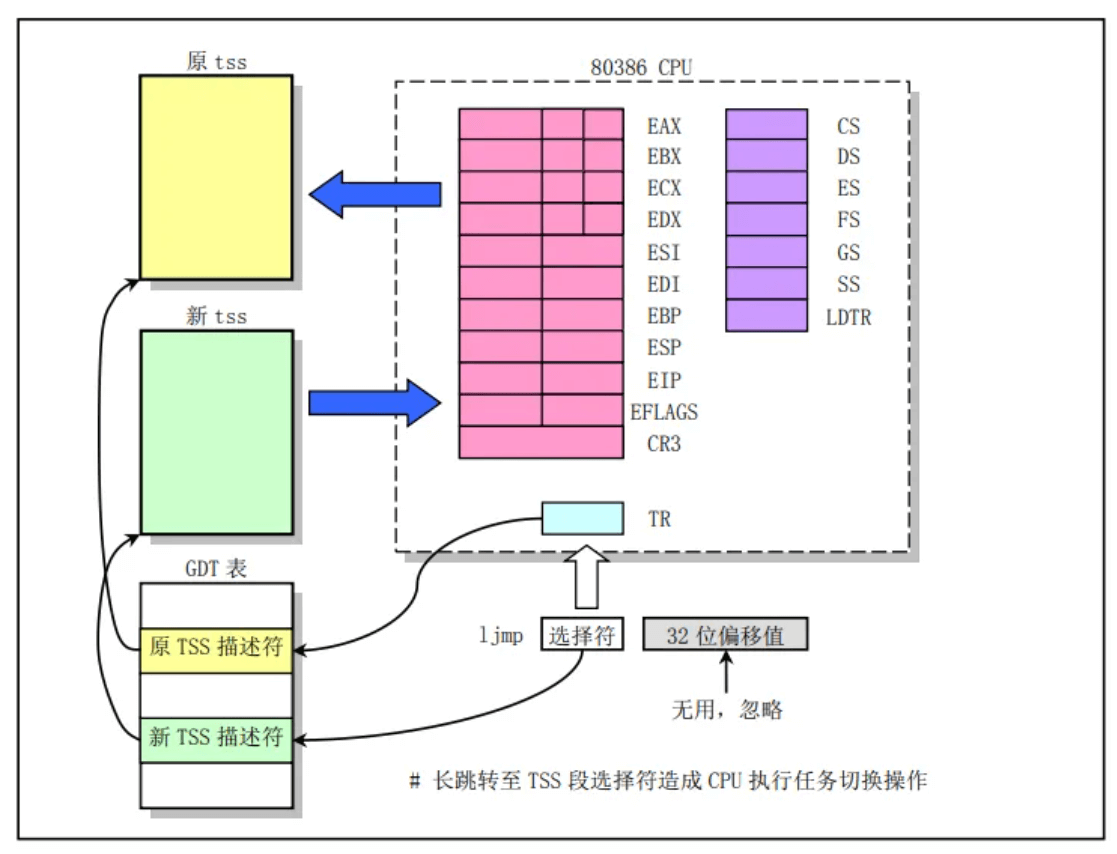
switch_to 进程切换,其实就是切换上一章中我们定义的数据结构,我们需要保存当前的上下文到tss中,并将新的线程的上下文加载
ljmp :指令后面跟的是一个 tss 段,那么,会由硬件将当前各个寄存器的值保存在当前进程的 tss 中,并将新进程的 tss 信息加载到各个寄存器。
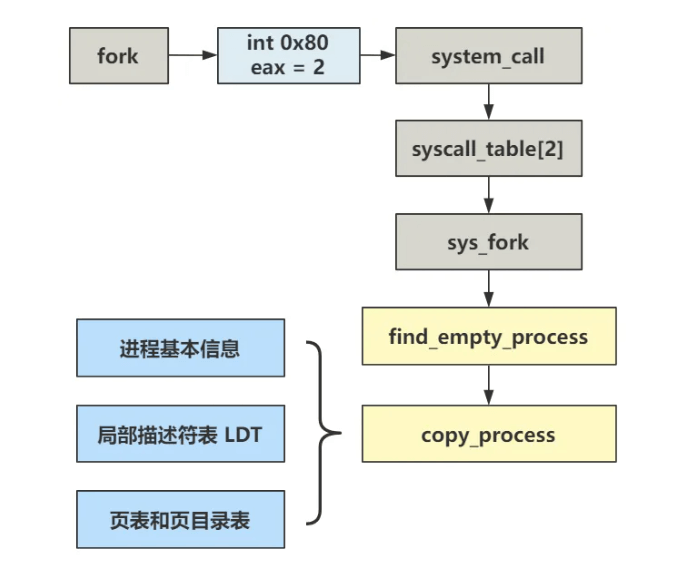
回到我们的fork命令
1 2 3 4 5 6 7 8 void main (void ) {if (!fork()) {for (;;) pause();
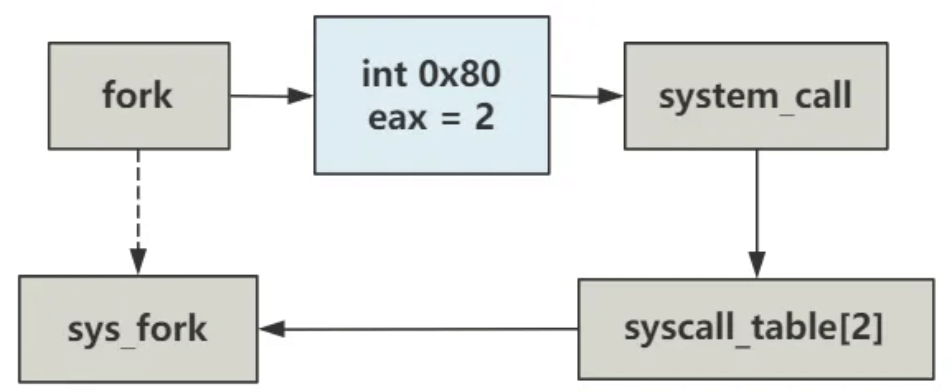
伪代码:这里其实是触发了一次中断,具体处理函数由eax决定,并去sys_call_table(操作系统提供给用户全部的系统调用功能)找
1 2 3 4 5 6 7 8 9 10 11 12 int fork (void ) {volatile long __res;int 80 hif (__res >= 0 )return (void ) __res;return -1 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 set_system_gate(0x80 , &system_call);4 ]
系统调用也可能有参数,刚刚产生哪个系统调用是通过eax 传递,其他的参数可以通过ebx ecx edx 传递
1 2 3 4 #define _syscall0(type,name) #define _syscall1(type,name,atype,a) #define _syscall2(type,name,atype,a,btype,b) #define _syscall3(type,name,atype,a,btype,b,ctype,c)
全貌:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 _system_call:-1 ,%eax# push %ebx,%ecx,%edx as parameters # to the system call 0x10 ,%edx # set up ds,es to kernel space 0x17 ,%edx # fs points to local data space 4 )0 ,state(%eax) # state 0 ,counter(%eax) # counter # task[0] cannot have signals 3f 0x0f ,CS(%esp) # was old code segment supervisor ? 3f 0x17 ,OLDSS(%esp) # was stack segment = 0x17 ? 3f signal (%eax) ,%ebxblocked (%eax) ,%ecxsignal (%eax)
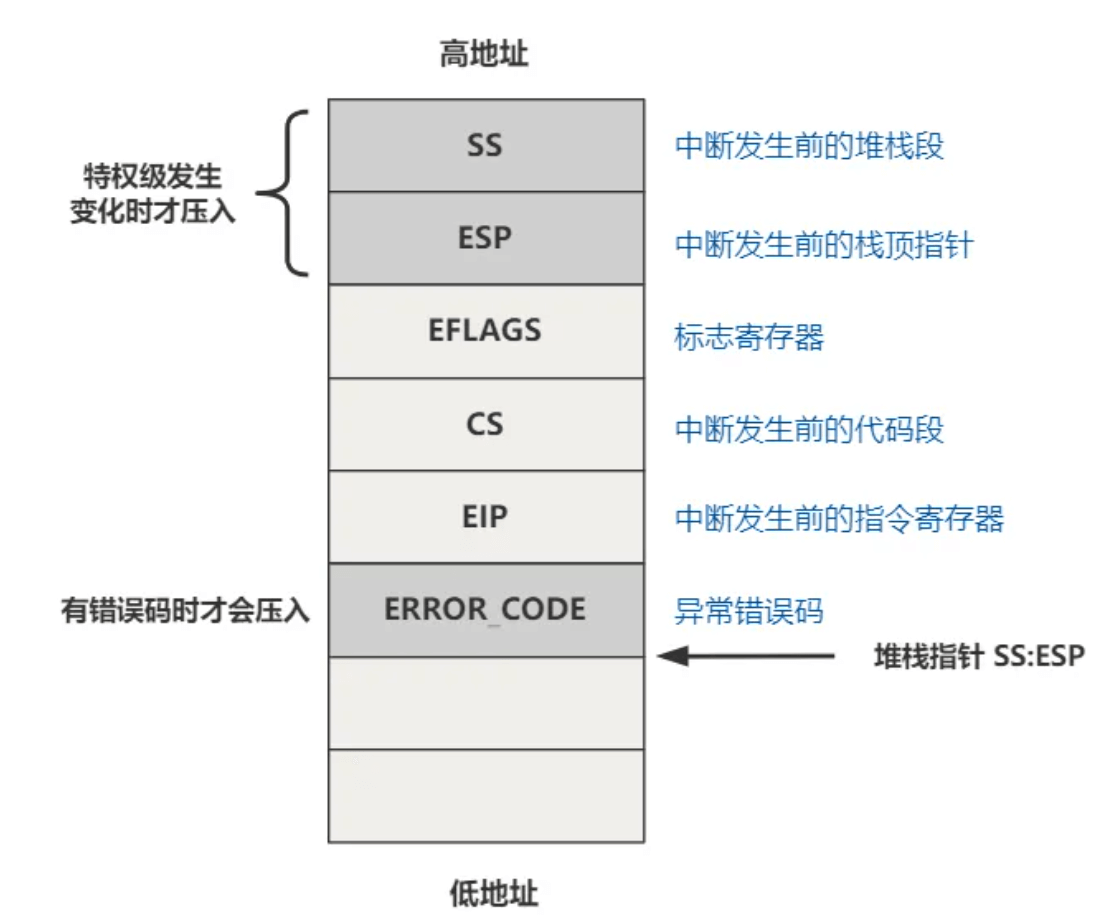
因为 system_call 是通过 int 80h 这个软中断进来的,所以也属于中断的一种,具体说是属于特权级发生变化的,且没有错误码情况的中断,所以在这之前栈已经被压了 SS、ESP、EFLAGS、CS、EIP 这些值。
接下来 system_call 又压入了一些值,具体说来有 ds、es、fs、edx、ecx、ebx、eax 。
所以之后,中断处理程序如果有需要的话,就可以从这里取出它想要的值,包括 CPU 压入的那五个值,或者 system_call 手动压入的 7 个值。
比如 sys_execve 这个中断处理函数,一开始就取走了位于栈顶 0x1C 位置处的 EIP 的值。
1 2 3 4 5 6 7 EIP = 0x1C 4 ,%esp
随后在 do_execve 函数中,又通过 C 语言函数调用的约定,取走了 filename,argv,envp 等参数。
1 2 3 4 5 6 7 8 int do_execve ( unsigned long * eip, long tmp, char * filename, char ** argv, char ** envp) {
回到fork函数,sys_fork 具体干了什么
1 2 3 4 5 6 7 8 9 10 11 _sys_fork:
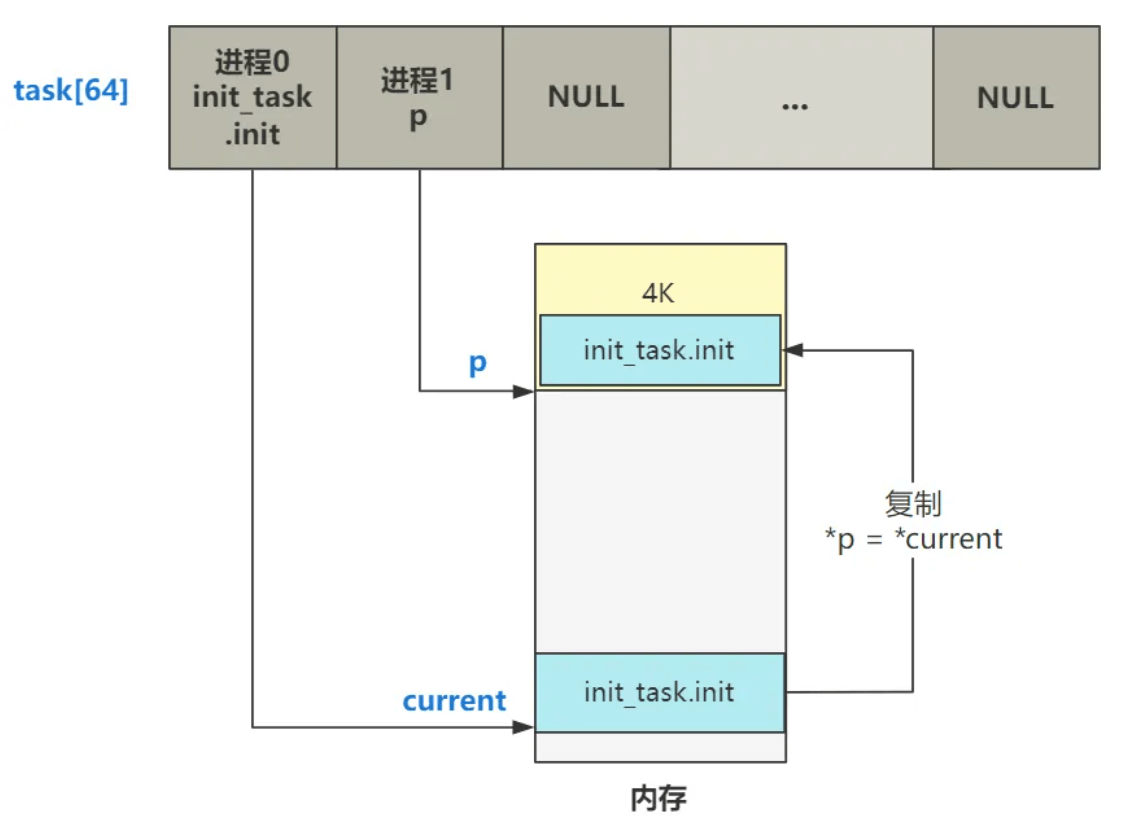
find_empty_process ,就是找到空闲的进程槽位。 task[64]
1 2 3 4 5 6 7 8 9 10 11 12 13 long last_pid = 0 ;int find_empty_process (void ) {int i;if ((++last_pid)<0 ) last_pid=1 ;for (i=0 ; i<64 ; i++)if (task[i] && task[i]->pid == last_pid) goto repeat;for (i=1 ; i<64 ; i++)if (!task[i])return i;return -EAGAIN;
copy_process ,就是复制进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) {struct task_struct p =struct task_struct *) get_free_page();1 )+FIRST_TSS_ENTRY,&(p->tss));1 )+FIRST_LDT_ENTRY,&(p->ldt));return last_pid;
设置独特值:一部分是 state ,pid ,counter 这种进程的元信息 ,另一部分是 tss 里面保存的各种寄存器的信息,即上下文 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int copy_process (int nr, ...) {long ) p;0x10 ;
ss0 和 esp0,这个表示 0 特权级也就是内核态时的 ss:esp 的指向。
根据代码我们得知,其含义是将代码在内核态时使用的堆栈栈顶指针指向进程 task_struct 所在的 4K 内存页的最顶端,而且之后的每个进程都是这样被设置的。
接下来将是进程页表和段表的复制,这将会决定进程之间的内存规划问题,很是精彩,也是 fork 真正的难点所在。
上一节中完成了task内存分配以及基本信息的复制,这里讲copy_mem
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int copy_mem (int nr,struct task_struct * p) {unsigned long old_data_base,new_data_base,data_limit;unsigned long old_code_base,new_code_base,code_limit;0x0f );0x17 );0x4000000 ;0x4000000 ;1 ],new_code_base);2 ],new_data_base);1 ]);2 ]);return 0 ;
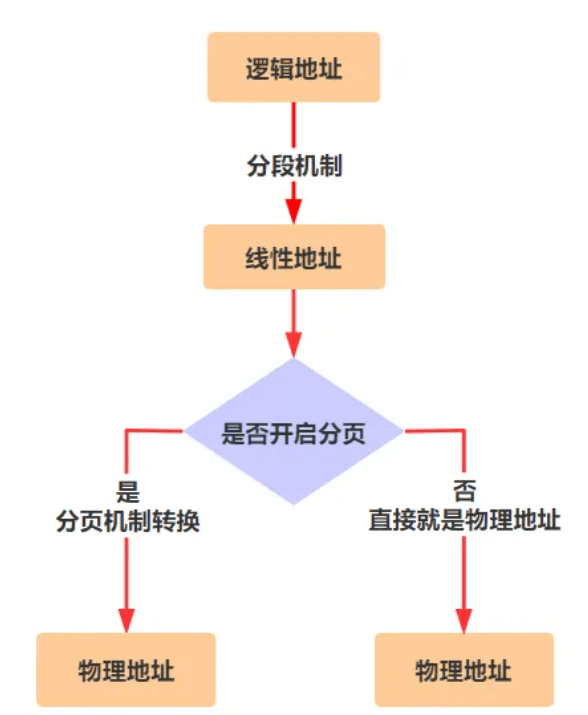
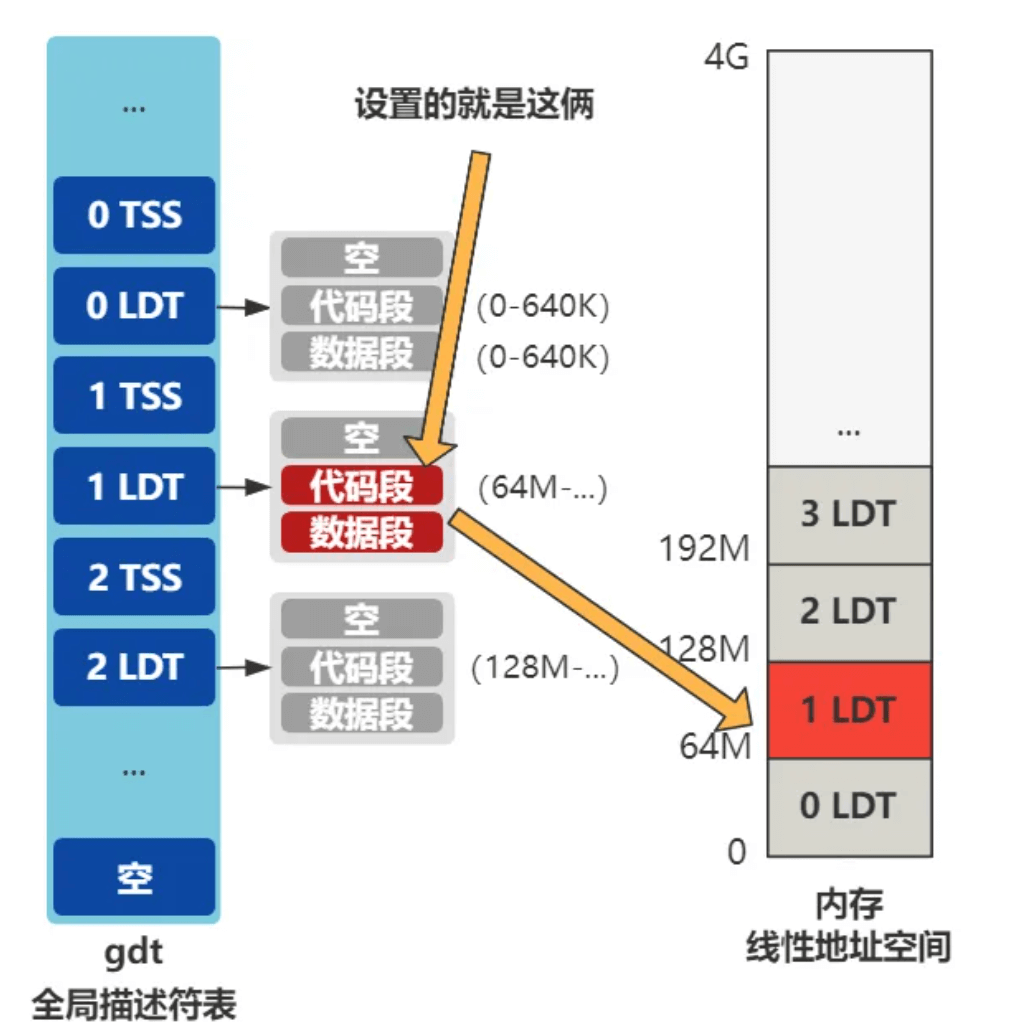
地址转换过程:需要进过分段和分页
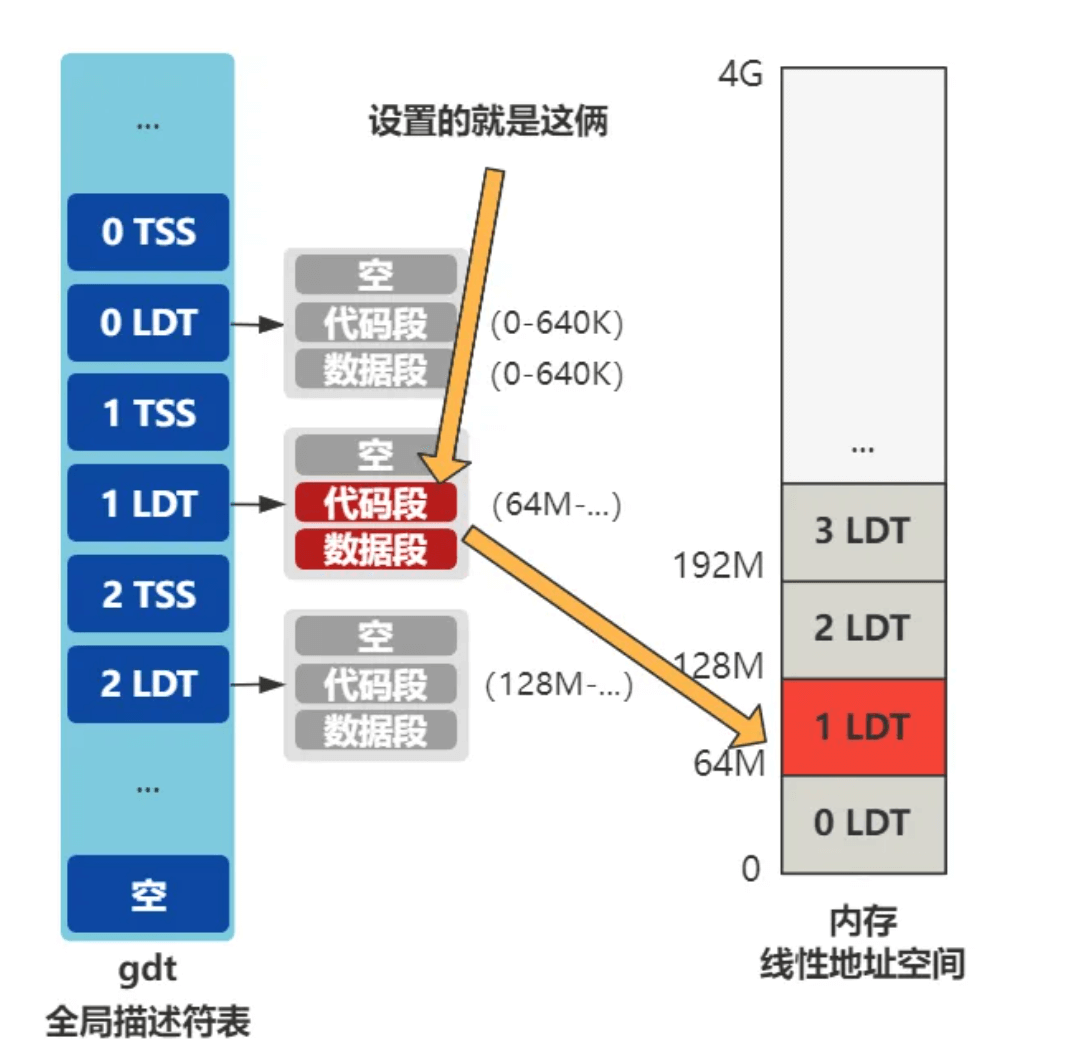
LDT 分段查看的就是当前进程的LDT,我们给进程 0 准备的 LDT 的代码段和数据段,段基址都是 0,段限长是 640K。给进程 1,也就是我们现在正在 fork 的这个进程,其代码段和数据段还没有设置。
所以第一步,局部描述符表 LDT 的赋值 ,就是给上图中那两个还未设置的代码段和数据段赋值。
其中段限长 ,就是取自进程 0 设置好的段限长,也就是 640K。
1 2 3 4 5 6 int copy_mem (int nr,struct task_struct * p) {0x0f );0x17 );
而段基址 有点意思,是取决于当前是几号进程,也就是 nr 的值。
1 2 3 4 5 6 int copy_mem (int nr,struct task_struct * p) {0x4000000 ; 0x4000000 ;
也就是说,今后每个进程通过段基址的手段,分别在线性地址空间中占用 64M 的空间(暂不考虑段限长),且紧挨着。
接着就把 LDT 设置进了 LDT 表里。
1 2 3 4 5 6 int copy_mem (int nr,struct task_struct * p) {1 ],new_code_base);2 ],new_data_base);
进程0的线性地址空间是064M,1 是64128M
经过以上的步骤,就通过分段的方式,将进程映射到了相互隔离的线性地址空间里,这就是段式 管理。
页表的复制 页表项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 int copy_page_tables (unsigned long from,unsigned long to,long size) unsigned long * from_page_table;unsigned long * to_page_table;unsigned long this_page;unsigned long * from_dir, * to_dir;unsigned long nr;unsigned long *) ((from>>20 ) & 0xffc );unsigned long *) ((to>>20 ) & 0xffc );unsigned ) (size+0x3fffff )) >> 22 ;for ( ; size-->0 ; from_dir++,to_dir++) {if (!(1 & *from_dir))continue ;unsigned long *) (0xfffff000 & *from_dir);unsigned long *) get_free_page() unsigned long ) to_page_table) | 7 ;0 )?0xA0 :1024 ;for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {if (!(1 & this_page))continue ;2 ; if (this_page > LOW_MEM) {12 ;return 0 ;
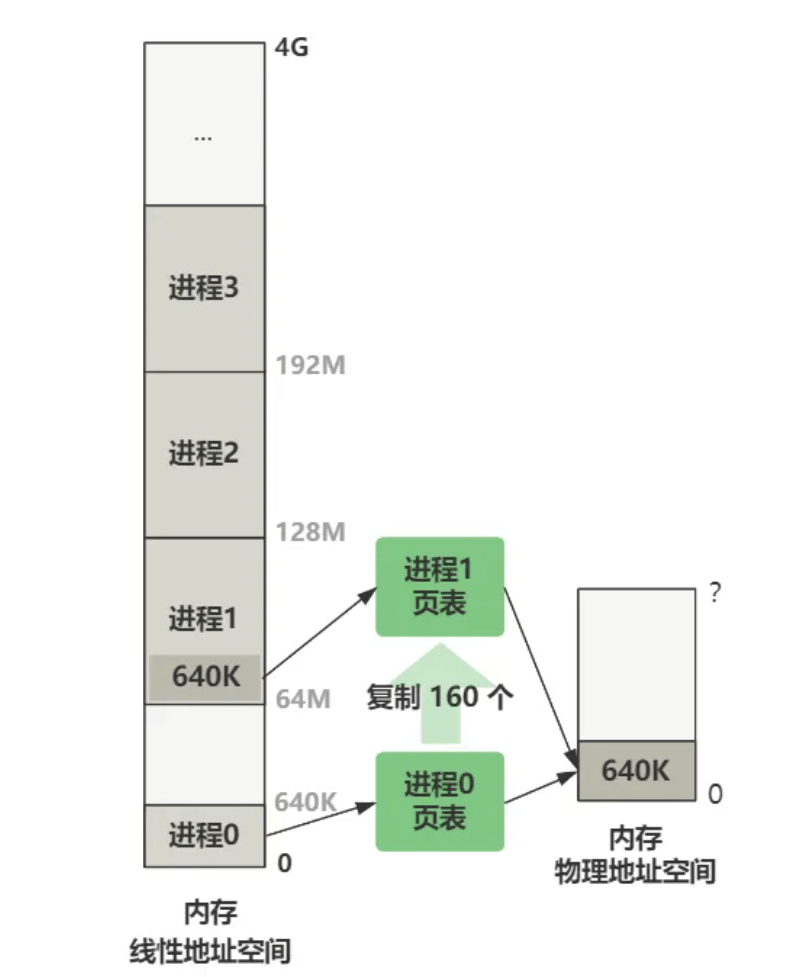
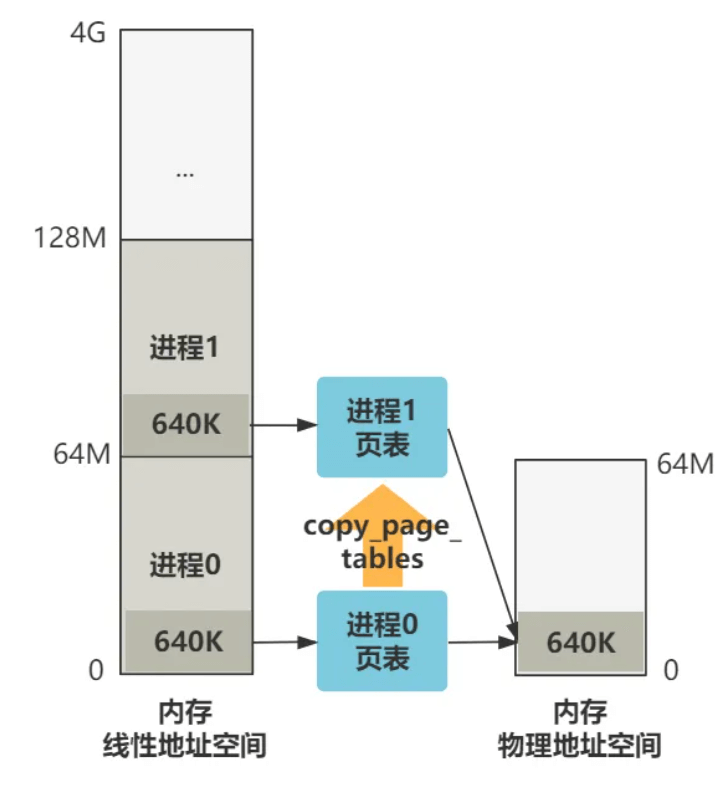
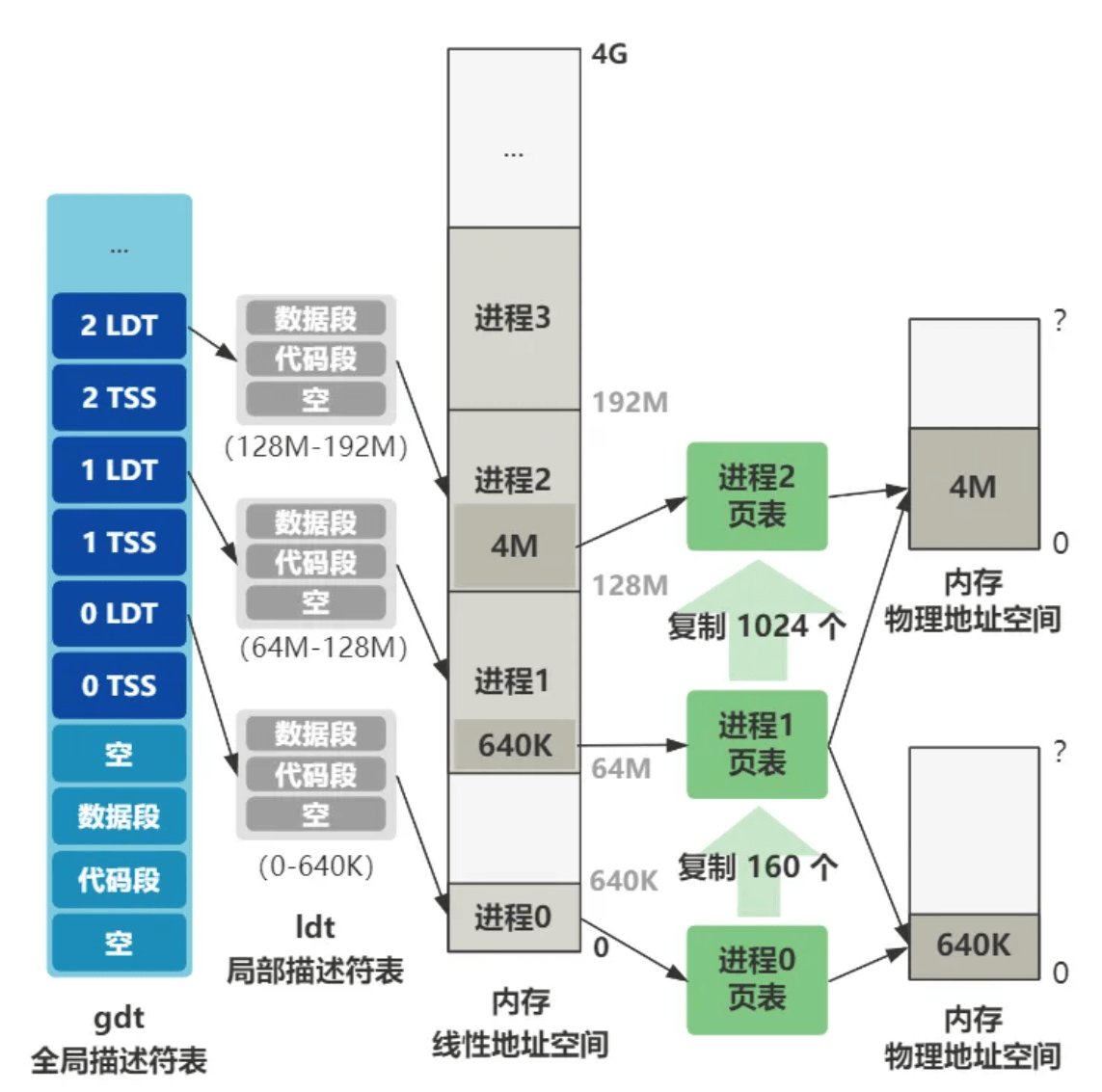
现在进程 0 的线性地址空间是 0 - 64M,进程 1 的线性地址空间是 64M - 128M。我们现在要造一个进程 1 的页表,使得进程 1 和进程 0 最终被映射到的物理空间都是 0 - 64M ,这样进程 1 才能顺利运行起来,不然就乱套了。
假设现在正在运行进程 0,代码中给出一个虚拟地址 0x03,由于进程 0 的 LDT 中代码段基址是 0,所以线性地址也是 0x03,最终由进程 0 页表映射到物理地址 0x03 处。
假设现在正在运行进程 1,代码中给出一个虚拟地址 0x03,由于进程 1 的 LDT 中代码段基址是 64M,所以线性地址是 64M + 3,最终由进程 1 页表映射到物理地址也同样是 0x03 处。
即,进程 0 和进程 1 目前共同映射物理内存的前 640K 的空间。
至于如何将不同地址通过不同页表映射到相同物理地址空间,很简单,举个刚刚的例子。
刚刚的进程 1 的线性地址 64M + 0x03 用二进制表示是:
0000010000_0000000000_000000000011
刚刚的进程 0 的线性地址 0x03 用二进制表示是:
0000000000_0000000000_000000000011
根据分页机制的转化规则,前 10 位表示页目录项,中间 10 位表示页表项,后 12 位表页内偏移。
进程 1 要找的是页目录项 16 中的第 0 号页表
进程 0 要找的是页目录项 0 中的第 0 号页表
那只要让这俩最终找到的两个页表里的数据一模一样即可。*from_page_table = this_page;
~2 表示取反,2 用二进制表示是 10,取反就是 01,其目的是把 this_page 也就是当前的页表的 RW 位置零,也就是是把该页变成只读 。
而 *from_page_table = this_page 表示又把源页表也变成只读 。
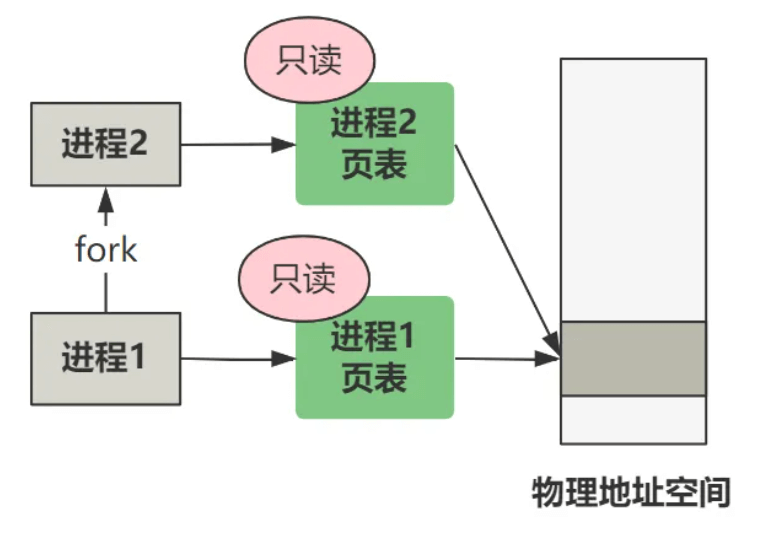
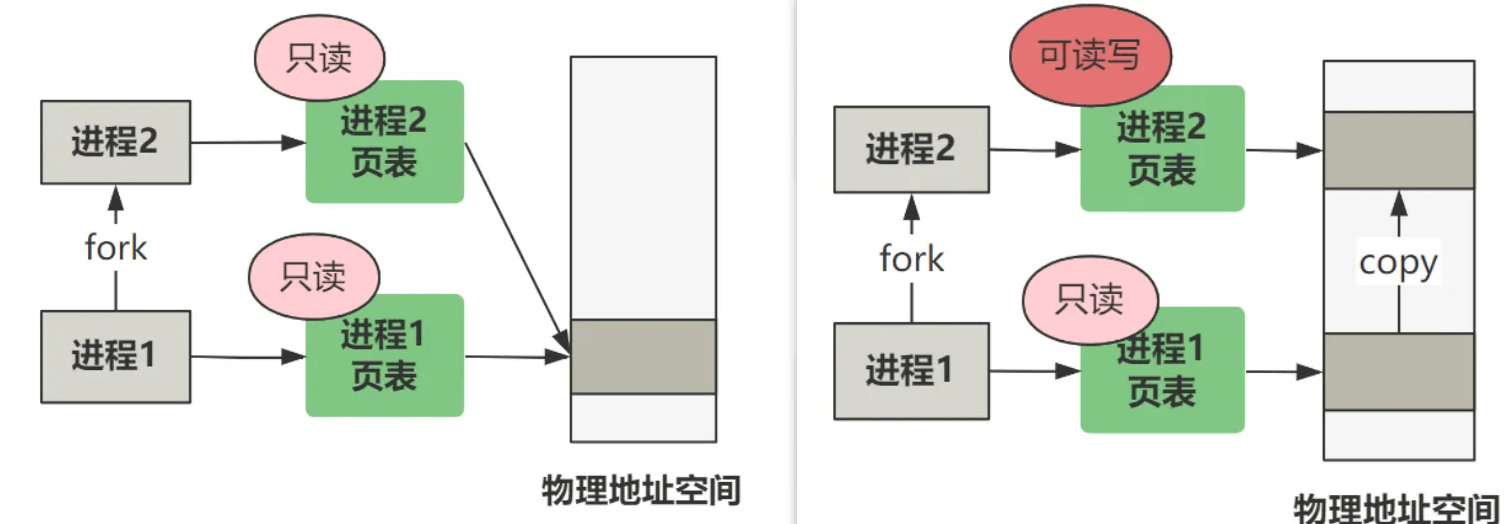
也就是说,经过 fork创建出的新进程,其页表项都是只读的,而且导致源进程的页表项也变成了只读。
这个就是写时复制 的基础,新老进程一开始共享同一个物理内存空间,如果只有读,那就相安无事,但如果任何一方有写操作,由于页面是只读的,将触发缺页中断,然后就会分配一块新的物理内存给产生写操作的那个进程,此时这一块内存就不再共享了。
写时复制 缺页中断 :
包含缺页do_no_page,和只读页do_wp_page 两种情况
1 2 3 4 5 6 7 8 void do_page_fault (..., unsigned long error_code) {if (error_code & 1 )else
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void do_wp_page (unsigned long error_code,unsigned long address) {unsigned long *)10 ) & 0xffc ) + (0xfffff000 &unsigned long *) ((address>>20 ) &0xffc )))));void un_wp_page (unsigned long * table_entry) {unsigned long old_page,new_page;0xfffff000 & *table_entry;if (mem_map[MAP_NR(old_page)]==1 ) {2 ;return ;7 ;
总结
第一 ,原封不动复制了一下 task_struct。
第二 ,LDT 的复制和改造,使得进程 0 和进程 1 分别映射到了不同的线性地址空间。
第三 ,页表的复制,使得进程 0 和进程 1 又从不同的线性地址空间,被映射到了相同的物理地址空间。
最后,将新老进程的页表都变成只读状态,为后面写时复制 的缺页中断 做准备。