线上BUG定位
GPT摘要
本文讨论了大规模项目开发中常见的运维与调试问题,并提出了一系列解决方案: 1. Bug应急管理:对于影响较大的Bug,优先采取紧急止损措施,如回滚版本或关闭功能模块。同时强调事后复盘的重要性以避免类似问题。 2. 数据一致性问题: - 缓存与数据库不一致时(如新增字段未同步缓存),需手动清除缓存或刷新数据。 - 避免滥用重启(可能掩盖问题),重点关注单例数据被意外修改的场景(如YAML配置污染)。 3. 调试优化建议: - 建立常见问题文档库,提倡以日志为主、单元测试为辅的调试方式。 - 生产环境优先通过日志、链路追踪定位问题,谨慎使用远程Debug。 - 推荐使用开关控制入参/出参打印,平衡问题排查与性能消耗。 4. 资源消耗故障案例: - CPU过载:死循环代码(如自旋等待文件更新)或线程管理不当(未使用线程池)会导致资源耗尽。 - 内存问题:大文件一次性加载(如
readAllBytes)可能触发虚拟内存频繁交换,应改用流式处理(如BufferedReader);频繁GC(如循环内重复创建对象)可通过对象复用优化。 - 资源泄漏:未关闭文件句柄、HTTP连接或僵尸线程需通过工具检测。 5. 诊断工具链: - 基础命令:jps定位进程、top/ps查线程、jstack抓取线程栈。 - 高级工具:Arthas实时监控(dashboard)、线程分析(thread -n 3)及详细堆栈查看。 全文贯穿”预防-处理-复盘”的闭环思路,强调通过规范开发习惯(如日志优先、流式处理)和工具化手段提升系统稳定性。
BUG处理
feature还是bug
- 大规模项目,沉淀所有的feature也有难度,需求也是不断变化的(QA)
- bug紧急程度、bug负责团队以及人员
处理步骤
- 紧急止损:根据 bug 的严重性,判断是否需要快速下线相关功能或回滚版本。对于影响较大的 bug,应优先考虑通过回滚代码或关闭功能模块来避免对用户产生进一步影响。
- 问题排查
- 事后复盘
排查
基本解决思路
清缓存:对象加了字段,数据库用脚本补充了,但缓存没有补充,导致缓存数据不完整
刷新
重启:可能可以临时解决问题,但会影响bug定位
单例数据:YAML对象被别人修改了,导致后续其他业务场景出现BUG
维护一个文档,常见问题以及解决方法
非生产以及本地写代码时,养成习惯不要依靠单步调试,以日志为主
不依赖本地项目启动来测试服务,而是通过单元测试实现
定位问题
逻辑+数据,逻辑在代码中,但不同的数据也会走不同的逻辑,生产的完整数据比较难拿到
- 看日志(生产INFO,测试DEBUG)以及错误码定位问题
- 链路追踪,在链路中定位问题
- 测试环境复现,远程debug
- 生产环境复现
- 打印入参出参:开关
CPU占用高
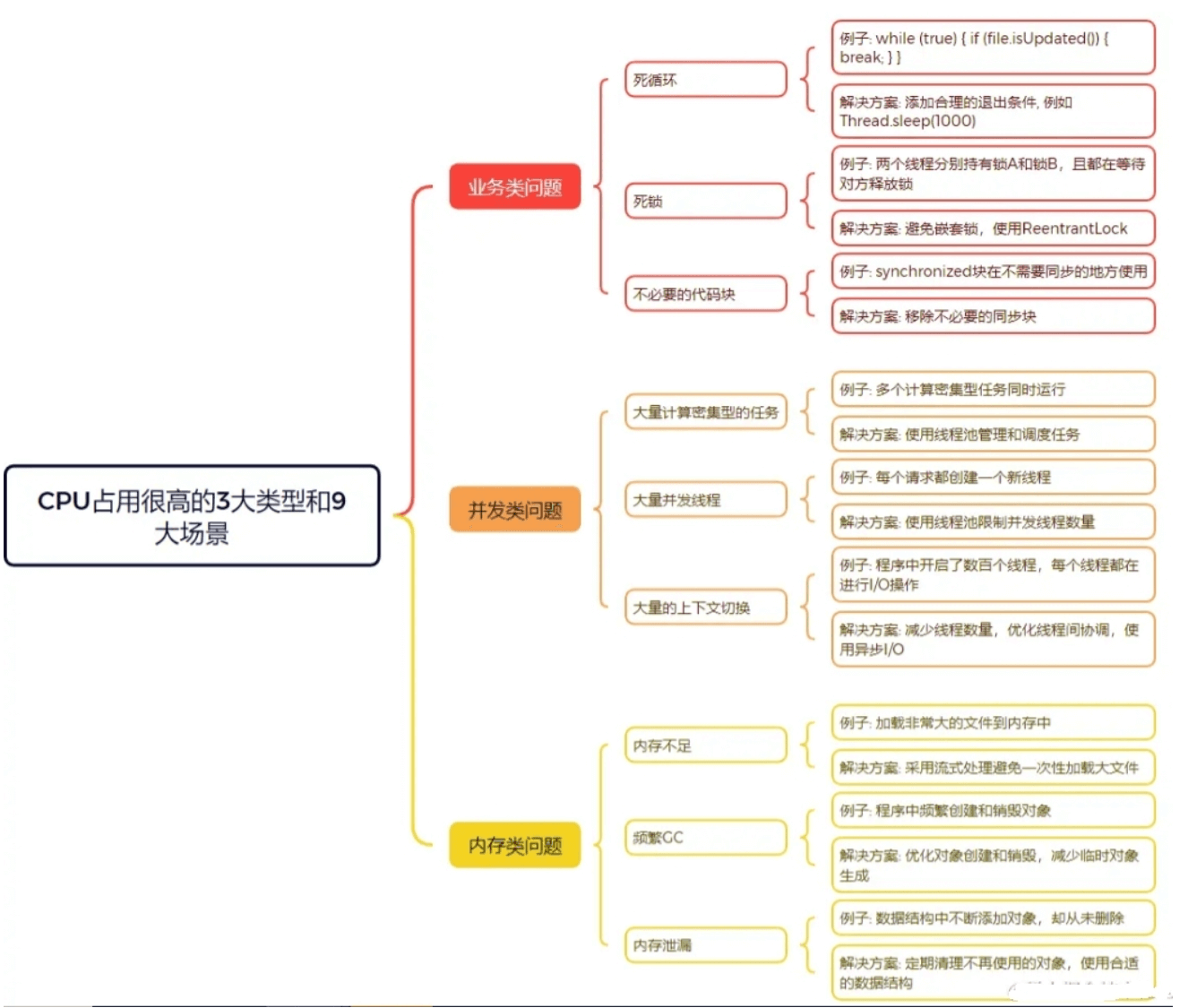
业务问题
死循环
例如:我们有一段代码用来检查文件的更新状态,但由于逻辑错误,条件永远无法满足,结果程序进入了死循环。
1 | |
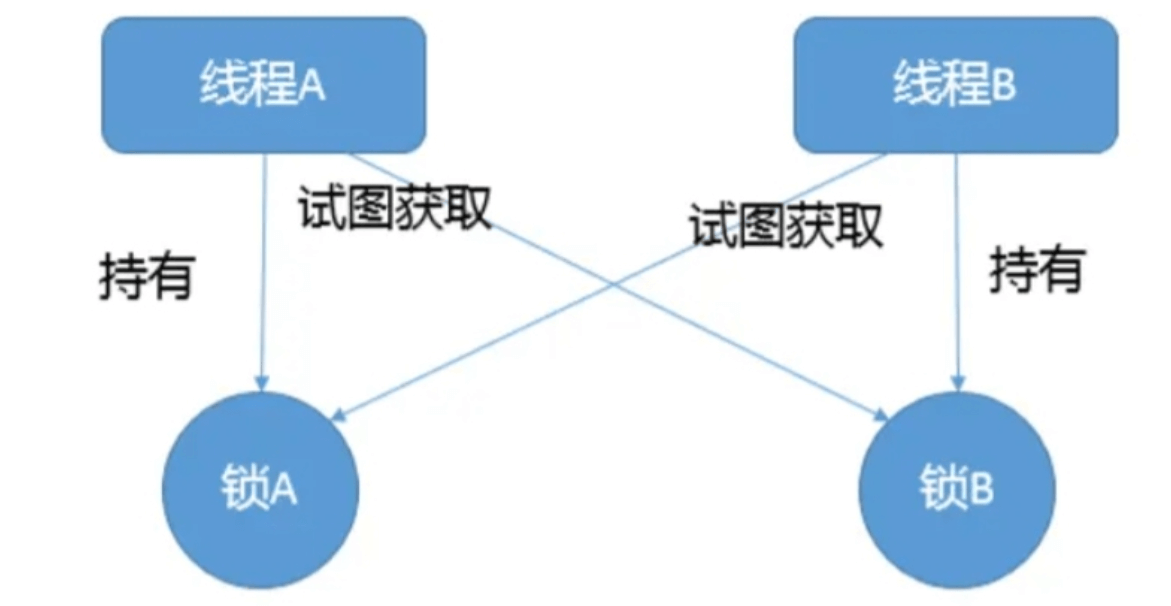
死锁
- 如果是自旋等待,就会耗尽CPU
- 如果是休眠等待,例如synchronized ,会耗尽系统资源(线程、内存、锁、数据库连接、文件句柄)
并发问题
使用线程池来管理线程资源,设置合理的线程数量
内存问题
内存不足
当系统内存不足时,就会将磁盘存储作为虚拟内存使用,而虚拟内存的运行速度要慢得多。
例如:直接一次性加载一个非常大的文件到内存中,导致内存不足
1 | |
这种过度的分页和交换会导致 CPU 占用率居高不下,因为处理器需要花费更多时间来管理内存访问,而不是高效地执行进程。
解决方案:优化内存使用,采用流式处理避免一次性加载大文件
1 | |
频繁GC
频繁的垃圾回收(GC)操作会占用大量CPU资源,导致性能下降。
例如:程序中频繁创建和销毁对象,导致GC频繁触发
1 | |
内存泄漏
内存资源没有释放,例如文件、http请求没有close、线程创建后卡死在某个地方没有销毁
问题定位
jstack
首先,需要找到CPU占用高的Java进程的PID(进程ID)。可以使用 top 或 ps 命令来找到该进程。
1 | |
Arthas
1 | |